豆瓣解析文本内容出错怎么办
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了豆瓣解析文本内容出错怎么办相关的知识,希望对你有一定的参考价值。
参考技术A 重新解析。豆瓣是一个社区网站。豆瓣解析文本内容出错重新解析。豆瓣创立于2005年3月6日。该网站以书影音起家,提供关于书籍、电影、音乐等作品的信息。呕心沥血的一次爬虫经历豆瓣电影Top250
前言
没有系统的学习爬虫,只是偶尔跟着大佬的博客练练手,有了前几天 女朋友想换情侣头像了,怎么办?【2万张图片满足要求】这个实战,又想着再学点儿关于正则表达式解析HTML的实际应用。
突然想看电影了,TXVideo推荐里没有找到我想看的,就想着来网上看看电影排行榜。
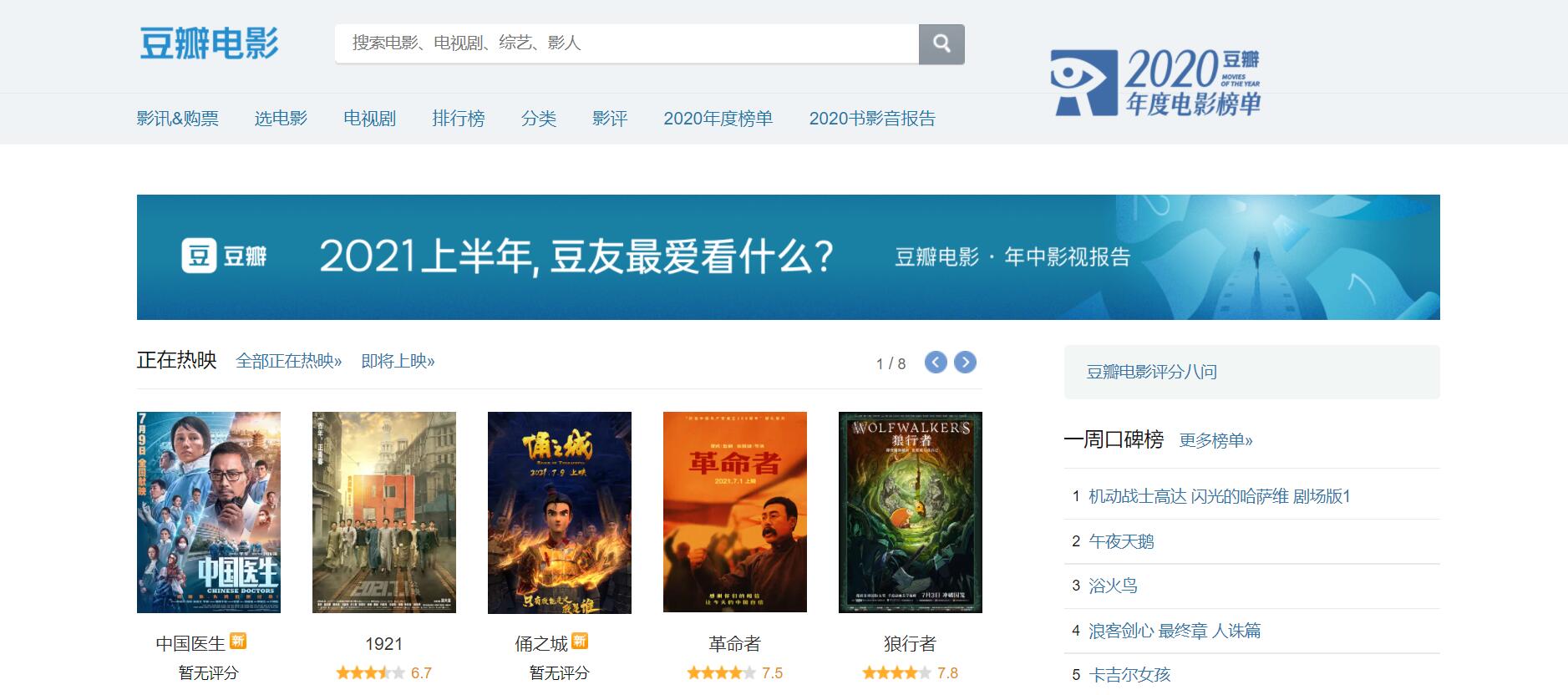
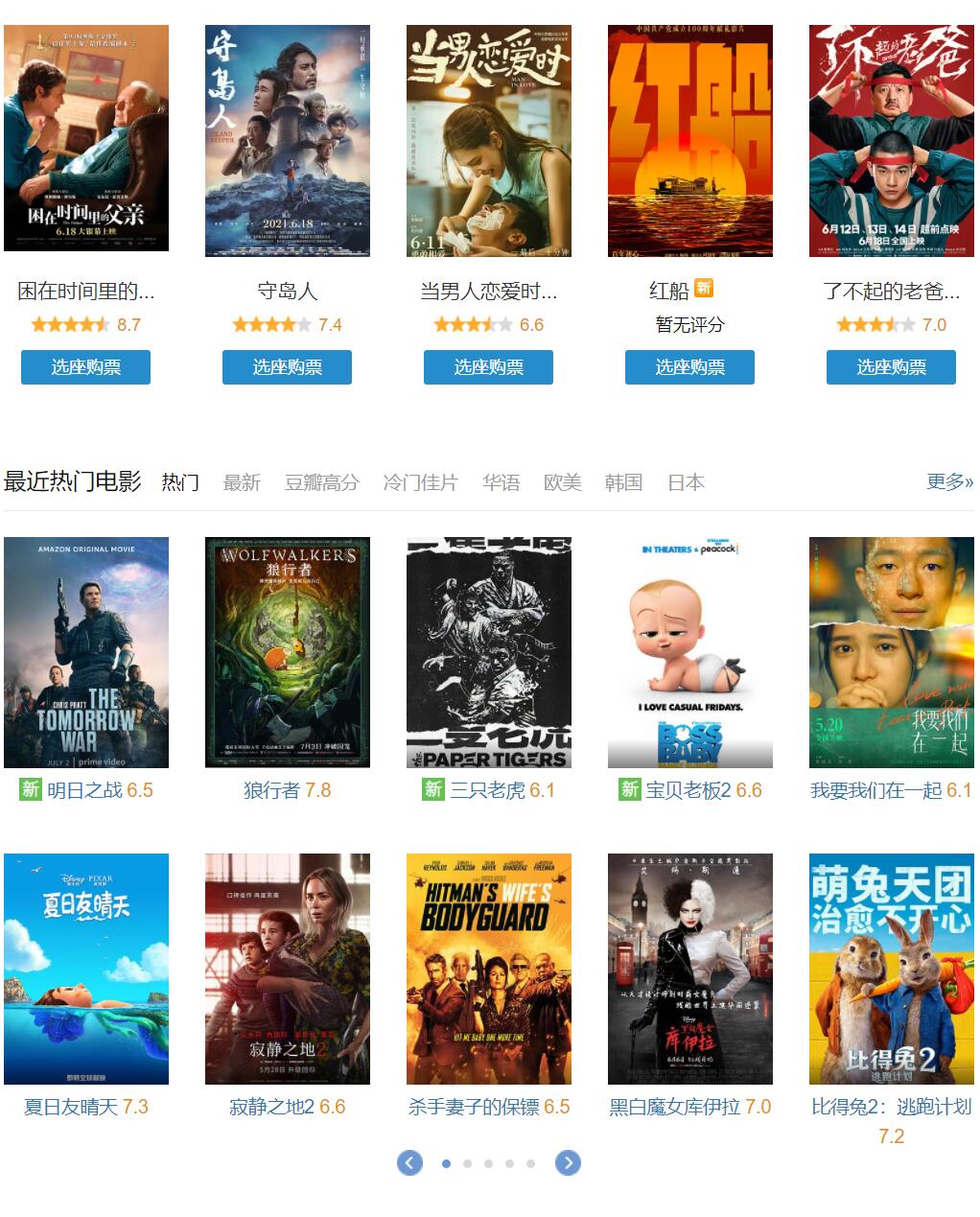
榜单也看到了,我的电影却没看成,开始‘呕心沥血’的爬点数据玩玩儿。
数据来源
豆瓣电影 Top 250: https://movie.douban.com/top250

这里面有你看过的电影吗?
分析网页源码
- 打开要爬取的网页链接
- 按F12进入开发者模式,点击图片的选中区域,之后可以在网页中定位代码位置
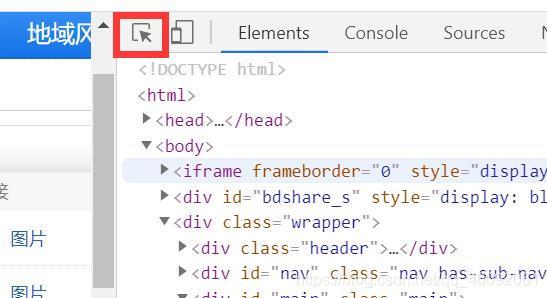
- 经分析,我们可以看到电影信息都在
<li>标签下,如下图:
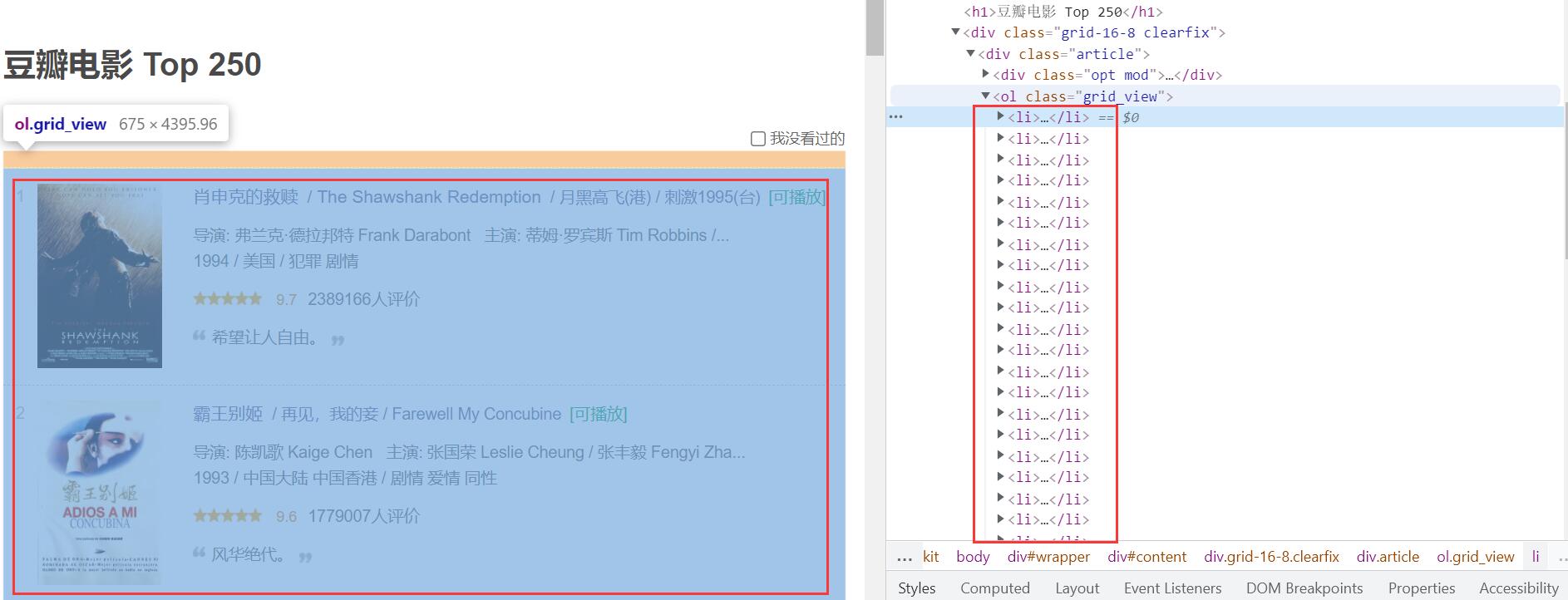
- 接着往下看:
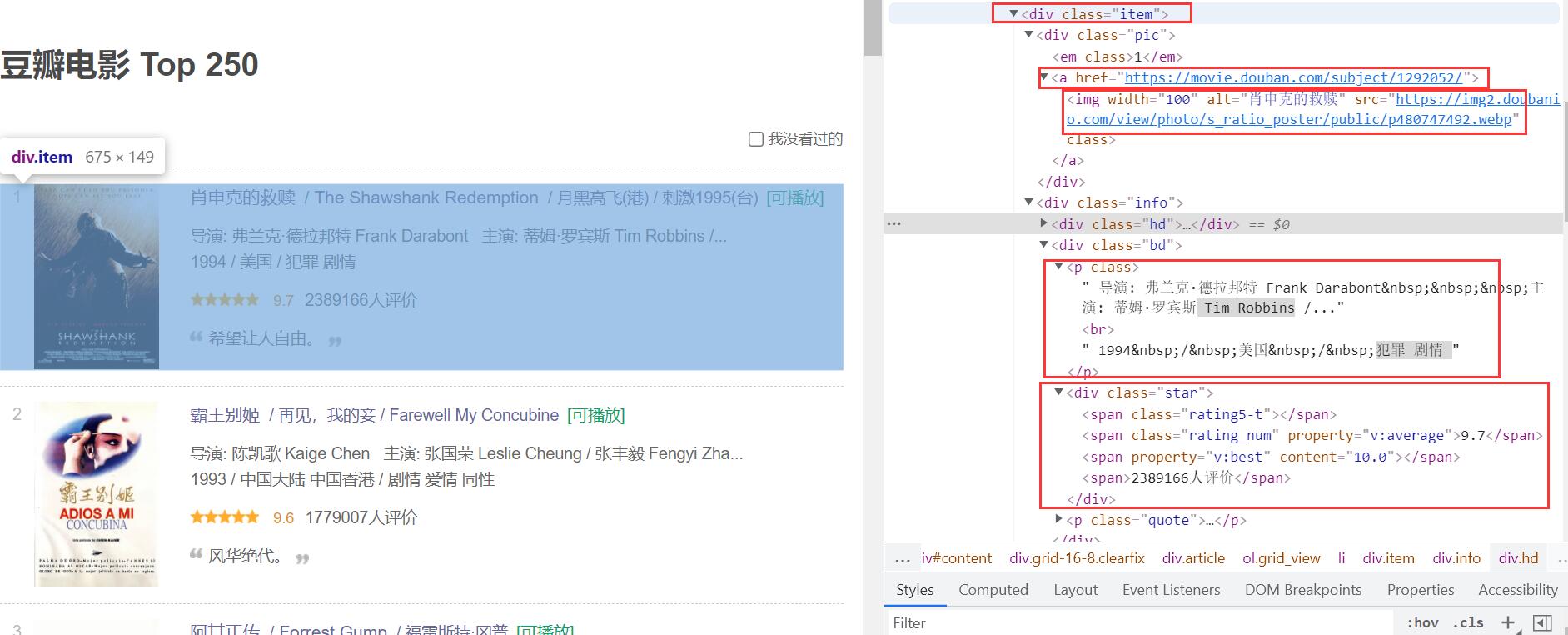
我们想要获取电影的详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,相关信息。
看上图可以发现每一部电影的相关信息都包含在 <div class="item">...</div>标签下。
于是我们可以获取当前页面下所有该<div class="item">...</div>标签并逐一分析里面的代码,解析出我们所需的信息。
# 逐一解析每一步电影,分析得:每一部的电影均存储在 <div class='item'>
soup = BeautifulSoup(html, 'html.parser')
# 获取每一部电影所在的<div>标签下
movies = soup.find_all('div', class_='item')
- 继续滚动滑轮往下看:
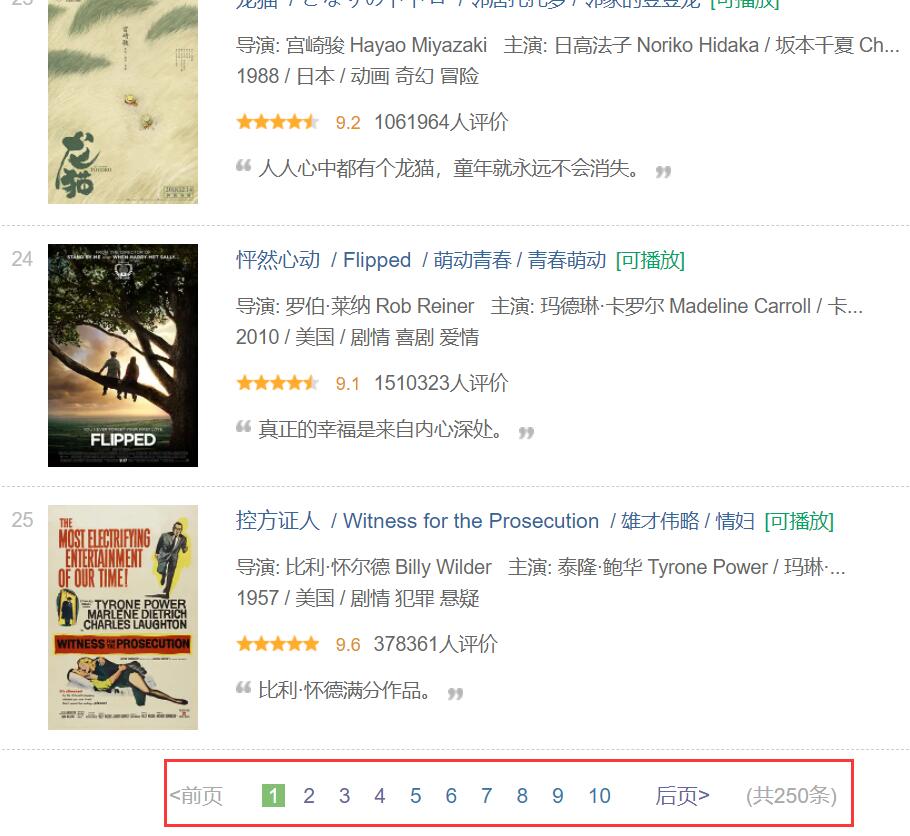
我们发现每一页只有25部电影,共有10页。
- 一起找规律


来回切换页面时,可以发现地址唯一变化的就是start=?
因为电影评分Top250,每个页面只显示25个,所以我们需要访问页面10次,25*10=250。
于是10个页面的网址便知道了:
https://movie.douban.com/top250?start=i*25
# 调用获取页面信息的函数,10次
for i in range(10):
# 拼接url
url = baseUrl + str(i*25)
baseurl = "https://movie.douban.com/top250?start="
获取HTML源码
# 获取网页源代码
def getHtml(url):
try:
# 当前请求代理,模拟浏览器头部信息
# # 用户代理User-Agent,表示告诉服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
# 获取url请求对象
r = requests.get(url, timeout=30, headers=headers)
r.raise_for_status() # 判断返回状态码是不是200,反之抛出HttpError异常
# 规范字符编码,根据当前编码环境自适应编码格式
r.encoding = r.apparent_encoding
print('状态码:', r.status_code)
# 返回网页源代码
return r.text
except Exception as e:
print(e.__traceback__)
return '访问url失败'
解析网页内容
- 解析数据我们使用
BeautifulSoup(靓汤) 库的find_all方法,获取每一部电影所在的<div class="item">...</div>标签内容。
# 逐一解析每一步电影,分析得:每一部的电影均存储在 <div class='item'>
soup = BeautifulSoup(html, 'html.parser')
# 获取每一部电影所在的<div>标签下
movies = soup.find_all('div', class_='item')
- 之后对
<div class="item">标签下的信息使用正则表达式进行提取。
# 创建正则表达式对象
movieLink = re.compile(r'<a href="(.*?)">') # 电影详细信息链接
imgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # 电影封面图片
movieTitle = re.compile(r'<span class="title">(.*?)</span>') # 电影名称
movieRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') # 电影评分
judgeNum = re.compile(r'<span>(\\d*)人评价</span>') # 评价人数
movieInq = re.compile(r'<span class="inq">(.*?)</span>') # 电影简介
otherInfo = re.compile(r'<p class="">(.*?)</p>', re.S) # 相关信息
# 查找符合要求的字符串,获取所需信息
for movie in movies:
data = [] # 保存一部电影的信息
movie = str(movie) # 转为字符串,方便解析
备注:
re.S:
在字符串a中,包含换行符\\n,在这种情况下:
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
保存数据
保存数据到excel中
关于python对excel的操作,请参考:【干货】建议收藏! ! !全网最全的Python.openpyxl操作Excel数据
# 存储数据到excel中
def saveData(datalist, savepath):
# 获取工作簿
wb = openpyxl.Workbook()
# 获取工作表
ws = wb.active
# 设置工作表sheet名称
ws.title = '豆瓣电影Top250'
# 添加表头列名
columns = ["影片中文名", "影片外国名", "评分", "评价数", "概况", "相关信息", "电影详情链接", "封面链接"]
ws.append(columns)
# 循环遍历写入每一部电影数据
for data in datalist:
ws.append(data)
# 保存工作簿
wb.save(savepath)
完整代码
# 爬取豆瓣电影 Top 250相关信息
from bs4 import BeautifulSoup
import requests
import re
import openpyxl
'''
re.S:
在字符串a中,包含换行符\\n,在这种情况下:
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
'''
# 创建正则表达式对象
movieLink = re.compile(r'<a href="(.*?)">') # 电影详细信息链接
imgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # 电影封面图片
movieTitle = re.compile(r'<span class="title">(.*?)</span>') # 电影名称
movieRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') # 电影评分
judgeNum = re.compile(r'<span>(\\d*)人评价</span>') # 评价人数
movieInq = re.compile(r'<span class="inq">(.*?)</span>') # 电影简介
otherInfo = re.compile(r'<p class="">(.*?)</p>', re.S) # 相关信息
# 获取网页源代码
def getHtml(url):
try:
# 当前请求代理,模拟浏览器头部信息
# # 用户代理User-Agent,表示告诉服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
# 获取url请求对象
r = requests.get(url, timeout=30, headers=headers)
r.raise_for_status() # 判断返回状态码是不是200,反之抛出HttpError异常
# 规范字符编码,根据当前编码环境自适应编码格式
r.encoding = r.apparent_encoding
print('状态码:', r.status_code)
# 返回网页源代码
return r.text
except Exception as e:
print(e.__traceback__)
return '访问url失败'
# 爬取网页,分析HTML内容,获取想要的信息
def getInfo(baseUrl):
datalist = [] # 存放爬虫数据
# 多页面循环爬取,每一个页面25部电影
for i in range(10):
# 拼接url
url = baseUrl + str(i*25)
# 获取网页源代码
html = getHtml(url)
# 逐一解析每一步电影,分析得:每一部的电影均存储在 <div class='item'>
soup = BeautifulSoup(html, 'html.parser')
# 获取每一部电影所在的<div>标签下
movies = soup.find_all('div', class_='item')
# 查找符合要求的字符串,获取所需信息
for movie in movies:
data = [] # 保存一部电影的信息
movie = str(movie) # 转为字符串,方便解析
# 获取电影名称
titles = re.findall(movieTitle, movie) # 可能有多个title
if len(titles) == 2:
firstTitle = titles[0]
data.append(firstTitle)
secTitle = titles[1].replace("/", "") # 消除转义字符
data.append(secTitle)
else:
data.append(titles[0])
data.append(' ')
# 获取电影评分
rating = re.findall(movieRating, movie)[0]
data.append(rating)
# 获取评价人数
judgenums = re.findall(judgeNum, movie)[0]
data.append(judgenums)
# 获取电影简介
introduce = re.findall(movieInq, movie)
# 如果不为空,则把一句话后面的 。去除
if len(introduce) != 0:
introduce = introduce[0].replace('。', '')
data.append(introduce)
else:
data.append(' ')
# 电影其他信息
others = re.findall(otherInfo, movie)[0]
others = re.sub('<br(\\s+)?/>(\\s+)?', "", others)
others = re.sub('/', "", others)
data.append(others.strip())
# 通过正则表达式,获取电影link
link = re.findall(movieLink, movie)[0] # 有多个<a>超链接标签,只需第一个就够
data.append(link)
# 获取图片link
imgLink = re.findall(imgSrc, movie)[0] # 有多个<a>超链接标签,只需第一个就够
data.append(imgLink)
# 一部电影获取完成
datalist.append(data)
return datalist
# 存储数据到excel中
def saveData(datalist, savepath):
# 获取工作簿
wb = openpyxl.Workbook()
# 获取工作表
ws = wb.active
# 设置工作表sheet名称
ws.title = '豆瓣电影Top250'
# 添加表头列名
columns = ["影片中文名", "影片外国名", "评分", "评价数", "概况", "相关信息", "电影详情链接", "封面链接"]
ws.append(columns)
# 循环遍历写入每一部电影数据
for data in datalist:
ws.append(data)
# 保存工作簿
wb.save(savepath)
def main():
# 爬取网页链接
baseurl = 'https://movie.douban.com/top250?start='
# 爬取数据
datalist = getInfo(baseurl)
# 保存路径及文件命名(当前目录新建.xlsx)
savepath = './豆瓣电影Top250.xlsx'
# 保存数据
saveData(datalist, savepath)
if __name__ == '__main__':
main()
print('爬取数据完成!')
结果展示
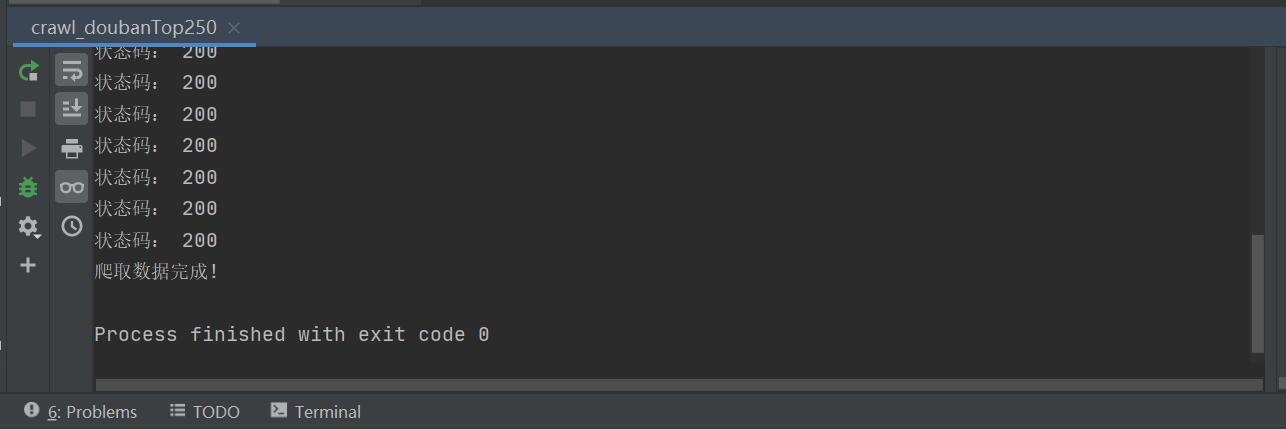
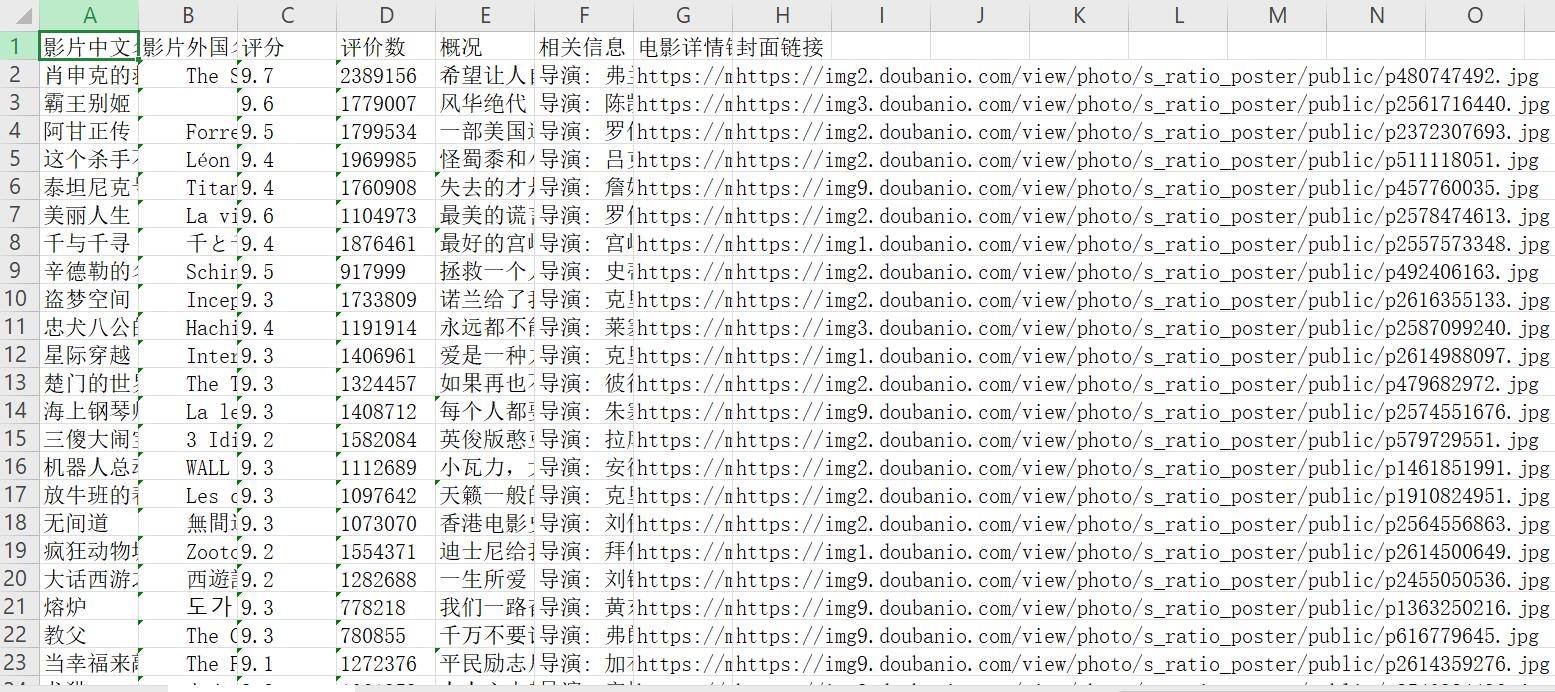
代码冗余较大,希望各位大佬不吝赐教,谢谢欣赏!
加油!
感谢!
努力!
以上是关于豆瓣解析文本内容出错怎么办的主要内容,如果未能解决你的问题,请参考以下文章
在豆瓣阅读购买图书,总是提示“出错了…… 可能是网络连接出现了问题,重试一下吧。”