第六(关于class&module)
Posted ckl893
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第六(关于class&module)相关的知识,希望对你有一定的参考价值。
一、匿名函数
匿名函数定义:
1.没有定义名字. 2. 函数体自带return
f=lambda x,y,z=1:x+y+z print(f(3,4,5))
匿名函数应用场景:应用于一次性的场景,临时使用
二、内置函数
zip应用场景,比较年龄最大的伙计,取出名字:
guys = { \'laomao\':83, \'sunwen\':60, \'shaoshuai\':103, \'laojiang\':75, \'laodeng\':93 } print(max(guys)) #比较的是key,所以显示sunwen print(max(guys.values())) #比较的是value,所以显示的是103 #希望比较value,显示key,希望如下实现: # x=(1,\'a\') # y=(5,\'c\') # print(x > y) #可以通过zip来实现 # print(list(zip(guys.values(),guys.keys()))) print(max(zip(guys.values(),guys.keys()))[1])
以上如果使用lambda实现
def get_value(name):return guys[name] #这个一次性函数,可以使用lambda --> lambda name:guys[name] print(max(guys,key=lambda name:guys[name])) #key是max方法的比较对象,现在指定的比较对象为value,返回值依然不变,所以实现以上功能
sorted如上用法
guys = { \'laomao\':83, \'sunwen\':60, \'shaoshuai\':103, \'laojiang\':75, \'laodeng\':93 } def get_value(name): return guys[name] print(sorted(guys)) #默认从小到大比较排序,按照名字排序。 print(sorted(guys,key=get_value)) #默认从小到大排序,比较值为vlaue print(sorted(guys,key=get_value,reverse=True)) #默认从小到大,按value排序再反转
结果:

map使用说明
 第一个传递函数,第二个传递参数
第一个传递函数,第二个传递参数
将所有名字添加上 _BOSS:
names = [\'laomao\',\'sunwen\',\'shaoshuai\',\'laojiang\'] print(map(lambda name:name + \'_BOSS\',names)) #得到一个迭代器 print(list(map(lambda name:name + \'_BOSS\',names)))
结果:

如上改变,如果列表里面有laodeng,则除了laodeng都加字符串
names = [\'laomao\',\'sunwen\',\'shaoshuai\',\'laojiang\',\'laodeng\'] #lambda name:name if name == \'laodeng\' else name + \'_BOSS\' #lambda表达是返回函数体,所以此处返回是name,应该是 return name if name == \'laodeng\' else name + \'_BOSS\' #return 可以省略 print(list(map(lambda name:name if name == \'laodeng\' else name + \'_BOSS\',names)))
结果:

reduce
计算从1加到100的值结果,示例如下:
from functools import reduce print(reduce(lambda x,y:x+y,range(101))) print(reduce(lambda x,y:x+y,range(101),100)) #初始值为100
结果:
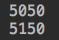
eval
eval可以指定名称空间
eval(cmd,{ 全局名称空间},{局部名称空间})
cmd=\'print(x)\' x=8 eval(cmd,{},{\'x\':99})
结果:

cmd=\'print(x)\' x=8 eval(cmd,{\'x\':66},{\'y\':99})
结果:

compile说明
s = \'for i in range(5):print(i)\' code=compile(s,\'\',\'exec\') exec(code)
结果:

三、re模块
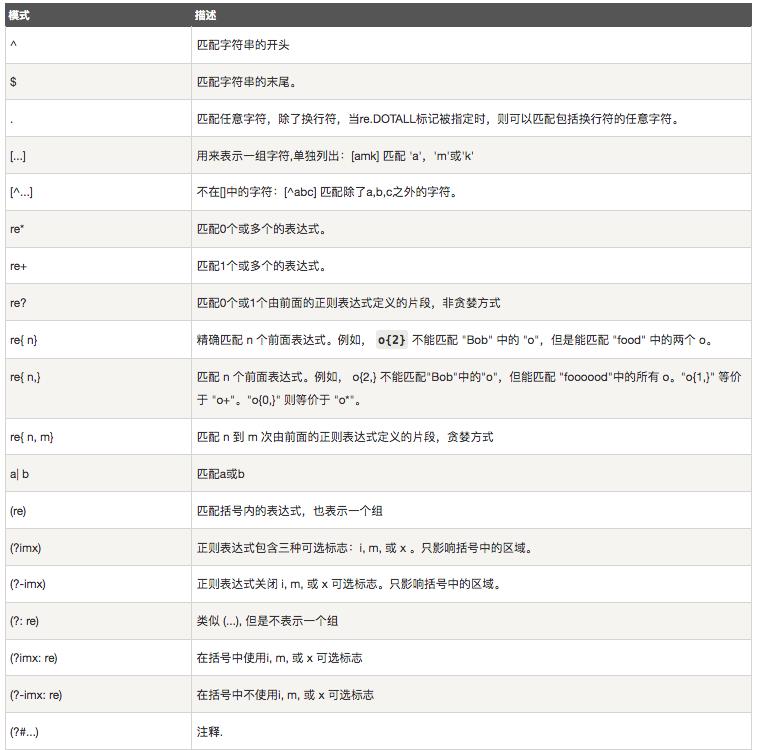
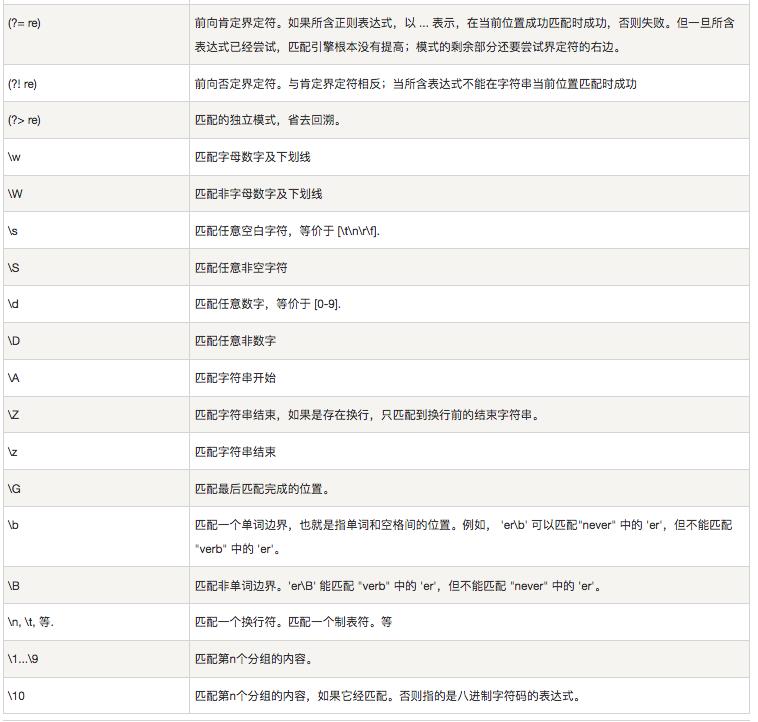
示例说明:
import re print(re.findall(\'\\w\',\'hi the world & i am _893\')) # [\'h\', \'i\', \'t\', \'h\', \'e\', \'w\', \'o\', \'r\', \'l\', \'d\', \'i\', \'a\', \'m\', \'_\', \'8\', \'9\', \'3\'] print(re.findall(\'\\W\',\'hi the world & i am _893\')) # [\' \', \' \', \' \', \'&\', \' \', \' \', \' \'] print(re.findall(\'\\s\',\'hi the world & i am _893 \\t \\n\')) # [\' \', \' \', \' \', \' \', \' \', \' \', \'\\t\', \' \', \'\\n\'] print(re.findall(\'\\S\',\'hi the world & i am _893 \\t \\n\')) # [\'h\', \'i\', \'t\', \'h\', \'e\', \'w\', \'o\', \'r\', \'l\', \'d\', \'&\', \'i\', \'a\', \'m\', \'_\', \'8\', \'9\', \'3\'] print(re.findall(\'\\d\',\'hi the world & i am _893 \\t \\n\')) # [\'8\', \'9\', \'3\'] print(re.findall(\'\\D\',\'hi the world & i am _893 \\t \\n\')) # [\'h\', \'i\', \' \', \'t\', \'h\', \'e\', \' \', \'w\', \'o\', \'r\', \'l\', \'d\', \' \', \'&\', \' \', \'i\', \' \', \'a\', \'m\', \' \', \'_\', \' \', \'\\t\', \' \', \'\\n\'] # print(re.findall(\'\\Ahi\',\'hi the world & hi wold i am _893 \\t \\n\')) print(re.findall(\'^hi\',\'hi the world & hi wold i am _893 \\t \\n\')) # [\'hi\'] print(re.findall(\'world\',\'hi the world & hi wold i am _893 \\t \\n\')) # [\'world\']
关于“.”的说明
# . 匹配任意一个字符 print(re.findall(\'a.c\',\'a a2c a*c a3c abc a c aaaac aacc\')) # [\'a2c\', \'a*c\', \'a3c\', \'abc\', \'a c\', \'aac\', \'aac\'] # 但是无法匹配到换行符 print(re.findall(\'a.c\',\'a a2c a*c a3c abc a c aaaac aacc a\\nc\')) # [\'a2c\', \'a*c\', \'a3c\', \'abc\', \'a c\', \'aac\', \'aac\'] #匹配换行符的操作 print(re.findall(\'a.c\',\'a a2c a*c a3c abc a c aaaac aacc a\\nc\',re.DOTALL)) print(re.findall(\'a.c\',\'a a2c a*c a3c abc a c aaaac aacc a\\nc\',re.S)) # [\'a2c\', \'a*c\', \'a3c\', \'abc\', \'a c\', \'aac\', \'aac\', \'a\\nc\']
关于[]的说明
#[]内部可以有多个字符,但值匹配一个 print(re.findall(\'a[1 23]c\',\'a a2c a*c a3c abc a c aaaac aacc a\\nc\')) #匹配a c,a1c,a2c,a3c这四种情况 # [\'a2c\', \'a3c\', \'a c\'] print(re.findall(\'a[a-z]c\',\'a a2c a*c a3c abc a c aaaac aacc a\\nc\')) # [\'abc\', \'aac\', \'aac\'] print(re.findall(\'a[A-Z]c\',\'a a2c a*c aAc abc a c aaaac aacc a\\nc\')) # [\'aAc\'] print(re.findall(\'a[a-zA-Z]c\',\'a a2c a*c aAc abc a c aaaac aacc a\\nc\')) # [\'aAc\', \'abc\', \'aac\', \'aac\'] print(re.findall(\'a[0-9]c\',\'a a2c a*c aAc abc a c aaaac aacc a\\nc\')) # [\'a2c\'] print(re.findall(\'a[^a-zA-Z]c\',\'a a2c a*c aAc abc a c aaaac aacc a\\nc\')) # [\'a2c\', \'a*c\', \'a c\', \'a\\nc\'] #注意,匹配特殊符号最后转义,因为"-" 在中间有范围的歧义 print(re.findall(\'a[\\+\\-\\*\\/]c\',\'a a+c a-c a/c a2c a*c aAc abc a c aaaac aacc a\\nc\')) [\'a+c\', \'a-c\', \'a/c\', \'a*c\']
转义注意:
#匹配a\\c呢? # print(re.findall(\'a\\\\c\',\'abc a\\c a c aaaac\')) #这样写会报错,因为第二个转义,第一个没有转义 print(re.findall(\'a\\\\\\\\c\',\'abc a\\c a c aaaac\')) #这样可以,但是太麻烦 # [\'a\\\\c\'] #python 的rawstring print(re.findall(r\'a\\\\c\',\'abc a\\c a c aaaac\')) # [\'a\\\\c\']
#? * + 说明
#? * + {} #?左边那一个字符有0个或1个 print(re.findall(\'ab?\',\'a ab abb aab bbbb\')) # [\'a\', \'ab\', \'ab\', \'a\', \'ab\'] #* 左边那一个字符有0个或无穷个 print(re.findall(\'ab*\',\'a ab abb abbb abbbbb bbbbb\')) # print(re.findall(\'ab{0,}\',\'a ab abb abbb abbbbb bbbbb\')) # [\'ab\', \'abb\', \'abbb\', \'abbbbb\'] #+ 左边那一个字符有一个或无穷个 print(re.findall(\'ab+\',\'a ab abb abbbb bbbbbb\')) # print(re.findall(\'ab{1,}\',\'a ab abb abbbb bbbbbb\')) # [\'ab\', \'abb\', \'abbbb\'] #{n,m}匹配左边的那一个字符,n到m次 print(re.findall(\'ab{3}\',\'a ab abb abbbb bbbbbb\')) # [\'abbb\'] print(re.findall(\'ab{2,3}\',\'a ab abb abbbb bbbbbb\')) # [\'abb\', \'abbb\']
#.* .*?
#.* 贪婪匹配 print(re.findall(\'a.*c\',\'a123c456c\')) # [\'a123c456c\'] #.*? 非贪婪匹配 print(re.findall(\'a.*?c\',\'a123c456c\')) # [\'a123c\']
#():分组
#():分组 print(re.findall(\'ab\',\'abababab123\')) #[\'ab\', \'ab\', \'ab\', \'ab\'] #匹配到所有ab并显示 print(re.findall(\'(ab)\',\'abababab123\')) # [\'ab\', \'ab\', \'ab\', \'ab\'] #匹配到所有ab并返回括号内的内容,也就是返回所有ab print(re.findall(\'(a)b\',\'abababab123\')) # [\'a\', \'a\', \'a\', \'a\'] #匹配到所有ab并返回括号内的内容,也就是返回所有a print(re.findall(\'a(b)\',\'abababab123\')) # [\'b\', \'b\', \'b\', \'b\'] #匹配到所有ab并返回括号内的内容,也就是返回所有b print(re.findall(\'(ab)+\',\'abababab123\')) # [\'ab\'] #匹配到最长的那个,也就是abababab123,并返回括号内的内容,也就是返回ab print(re.findall(\'(ab)+123\',\'abababab123\')) # [\'ab\'] #匹配到最长的那个,也就是abababab123,并返回括号内的内容,也就是返回ab print(re.findall(\'(ab)+(123)\',\'abababab123\')) # [(\'ab\', \'123\')] #匹配到ab最长的且只返回括号的内容,并且跟上123
返回所有内容:
print(re.findall(\'(?:ab)+123\',\'abababab123\')) #[\'abababab123\'] #匹配到最长的那个,也就是abababab123,并返回所有的内容
print(re.findall(\'compan(y|ies)\',\'company is not the point,companies also not\')) # [\'y\', \'ies\'] print(re.findall(\'compan(?:y|ies)\',\'company is not the point,companies also not\')) # [\'company\', \'companies\']
re其它方法
search
#search 一直找,直到找到一次就返回 print(re.search(\'ab\',\'ababababa123\')) # <_sre.SRE_Match object; span=(0, 2), match=\'ab\'> print(re.search(\'ab\',\'ababababa123\').group()) # ab print(re.search(\'ab\',\'12mmmmnnnnnabsssssd\').group()) # ab
match
#match 从最开始找,找不到就返回None print(re.search(\'ab\',\'cthhkab883\').group()) # ab print(re.match(\'ab\',\'cthhkab883\')) # None
split
print(re.split(\'b\',\'abcde\')) # [\'a\', \'cde\'] print(re.split(\'[ab]\',\'abcde\')) # [\'\', \'\', \'cde\']
sub&subn
#匹配一次 print(re.sub(\'laomao\',\'boss\',\'laomao manage a big troop laomao\',1)) # boss manage a big troop laomao #匹配两次 print(re.sub(\'laomao\',\'boss\',\'laomao manage a big troop laomao\',2)) # boss manage a big troop laomao #匹配所有,并返回次数 print(re.subn(\'laomao\',\'boss\',\'laomao manage a big troop laomao\')) # (\'boss manage a big troop boss\', 2)
# 需求:\'laomao is old\' 替换laomao和old位置 # 获取到单词及位置 print(re.sub(\'(\\w+)(\\W+)(\\w+)(\\W+)(\\w+)\',r\'\\1\\2\\3\\4\\5\',\'laomao is old\')) # laomao is old #替换 print(re.sub(\'(\\w+)(\\W+)(\\w+)(\\W+)(\\w+)\',r\'\\5\\2\\3\\4\\1\',\'laomao is old\')) # old is laomao print(re.sub(\'(\\w+)( .* )(\\w+)\',r\'\\3\\2\\1\',\'laomao is old\')) # old is laomao
四、时间模块
import time print(time.time()) #当前时间戳,从1970年开始 # 1543751613.326711 print(time.strftime(\'%Y-%m-%d %X\')) # 格式化时间字符串 # 2018-12-02 19:53:33 print(time.localtime()) #本地时区的struct_time # time.struct_time(tm_year=2018, tm_mon=12, tm_mday=2, tm_hour=19, tm_min=53, tm_sec=33, tm_wday=6, tm_yday=336, tm_isdst=0) print(time.gmtime()) #UTC时区的struct_time # time.struct_time(tm_year=2018, tm_mon=12, tm_mday=2, tm_hour=11, tm_min=53, tm_sec=33, tm_wday=6, tm_yday=336, tm_isdst=0) print(time.localtime().tm_mon) #获取本地时区的月 # 12 print(time.gmtime().tm_mday) #获取UTC时间的日 # 2 print(time.localtime(144567876)) #将一个时间戳转为当前时区的struct_time # time.struct_time(tm_year=1974, tm_mon=8, tm_mday=1, tm_hour=13, tm_min=44, tm_sec=36, tm_wday=3, tm_yday=213, tm_isdst=0) print(time.mktime(time.localtime())) #将struct_time转为时间戳 # 1543751613.0 print(time.strftime(\'%Y-%m-%d %X\',time.localtime())) #将本地时区struct_time转为格式化时间 # 2018-12-02 19:53:33 print(time.strptime(\'2011-10-02 13:21:46\',\'%Y-%m-%d %X\')) #将格式化时间转为struct_time # time.struct_time(tm_year=2011, tm_mon=10, tm_mday=2, tm_hour=13, tm_min=21, tm_sec=46, tm_wday=6, tm_yday=275, tm_isdst=-1)
print(time.ctime()) # Sun Dec 2 20:02:29 2018 print(time.asctime()) # Sun Dec 2 20:02:29 2018 print(time.ctime(143958322)) # Thu Jul 25 12:25:22 1974
五、random模块
import random print(random.random()) #float类型结果,大于0,小于1之间 # 0.008231991538039551 print(random.randint(1,6)) #取出大于等于1小于等于6之间的整数 # 3 print(random.randrange(3,9)) #取出大于等于3,小于9之间的整数 # 8 print(random.choice([\'ckl\',3,[7,9],\'kk\'])) #取出列表中随机一个元素 # kk print(random.sample([\'ckl\',3,[7,9],\'kk\'],2)) #取出列表中随机两个元素的组合 # [\'ckl\', 3] print(random.uniform(2,5)) #取出大于2小于5的小数 # 2.0408054451427087 x=[1,3,5,6,7,9] #随机洗牌 random.shuffle(x) print(x) # [5, 1, 3, 7, 9, 6]
生成随机验证码,大写及数字组合
def create_code(n): code=\'\' for i in range(n): x=str(random.randint(0,9)) y=chr(random.randint(65,90)) code+=random.choice([x,y]) return code sc=create_code(6) print(sc) # TR7NL6
六、os模块
import os os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd os.curdir #返回当前目录: (\'.\') os.pardir #获取当前目录的父目录字符串名:(\'..\') os.makedirs(\'dirname1/dirname2\') #可生成多层递归目录 os.removedirs(\'dirname1\') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(\'dirname\') #生成单级目录;相当于shell中mkdir dirname os.rmdir(\'dirname\') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(\'dirname\') #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() #删除一个文件 os.rename("oldname","newname") #重命名文件/目录 os.stat(\'path/filename\') #获取文件/目录信息 os.sep #输出操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/" os.linesep #输出当前平台使用的行终止符,win下为"\\t\\n",Linux下为"\\n" os.pathsep #输出用于分割文件路径的字符串 win下为;,Linux下为: os.name #输出字符串指示当前使用平台。win->\'nt\'; Linux->\'posix\' os.system("bash command") #运行shell命令,直接显示 os.environ #获取系统环境变量 os.path.abspath(path) #返回path规范化的绝对路径 os.path.split(path) #将path分割成目录和文件名二元组返回 os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) #返回path最后的文件名。如何path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) #如果path是绝对路径,返回True os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) #返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) #返回path的大小
七、sys模块
sys.argv #命令行参数List,第一个元素是程序本身路径 sys.exit(n) #退出程序,正常退出时exit(0) sys.version #获取Python解释程序的版本信息 sys.maxint #最大的Int值 sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform #返回操作系统平台名称
模拟滚动条:
import sys import time #sys.stdout实现 for i in range(20):以上是关于第六(关于class&module)的主要内容,如果未能解决你的问题,请参考以下文章