Xml解析之排除注释
Posted 小不懂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Xml解析之排除注释相关的知识,希望对你有一定的参考价值。
总结:
1、Xml中的注释也被当作节点元素;
示例XMLFile1.xml:
<?xml version="1.0" encoding="utf-8" ?> <News> <!--{标题注释}--> <NewsTitle>{标题1}</NewsTitle> <NewsList> <!--{标题列表注释}--> <NewsDetailTitle>{详细标题1}</NewsDetailTitle> <NewsDetailName>{详细名称}</NewsDetailName> </NewsList> </News>
C#解析代码:
private void button1_Click(object sender, EventArgs e) { XmlDocument doc = new XmlDocument(); doc.Load("XMLFile1.xml"); // 根节点 XmlNode node = doc.DocumentElement; // 遍历根节点的子节点 foreach (XmlNode childNode in node.ChildNodes) { // 【注意1:把根节点中的注释当成子节点】 //if (childNode.NodeType != XmlNodeType.Comment) // 判断不等于注释时 //{ textBox1.Text += childNode.InnerText; //} // 遍历根节点的孙节点 foreach (XmlNode item in childNode.ChildNodes) { // 【注意2:把根节点中的子节点的注释当成孙节点】 textBox2.Text += item.InnerText; } } }
效果图:
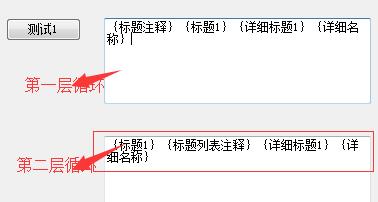
2、如果不要注释这个节点元素,可以根据XmlNodeType这个枚举类型来判断。
// 摘要: // 指定节点的类型。 public enum XmlNodeType { // 摘要: // 如果未调用 Read 方法,则由 System.Xml.XmlReader 返回。 None = 0, // // 摘要: // 元素(例如,<item>)。 Element = 1, // // 摘要: // 特性(例如,id=\'123\')。 Attribute = 2, // // 摘要: // 节点的文本内容。 Text = 3, // // 摘要: // CDATA 节(例如,<![CDATA[my escaped text]]>)。 CDATA = 4, // // 摘要: // 实体引用(例如,#)。 EntityReference = 5, // // 摘要: // 实体声明(例如,<!ENTITY...>)。 Entity = 6, // // 摘要: // 处理指令(例如,<?pi test?>)。 ProcessingInstruction = 7, // // 摘要: // 注释(例如,<!-- my comment -->)。 Comment = 8, // // 摘要: // 作为文档树的根的文档对象提供对整个 XML 文档的访问。 Document = 9, // // 摘要: // 由以下标记指示的文档类型声明(例如,<!DOCTYPE...>)。 DocumentType = 10, // // 摘要: // 文档片段。 DocumentFragment = 11, // // 摘要: // 文档类型声明中的表示法(例如,<!NOTATION...>)。 Notation = 12, // // 摘要: // 标记间的空白。 Whitespace = 13, // // 摘要: // 混合内容模型中标记间的空白或 xml:space="preserve" 范围内的空白。 SignificantWhitespace = 14, // // 摘要: // 末尾元素标记(例如,</item>)。 EndElement = 15, // // 摘要: // 由于调用 System.Xml.XmlReader.ResolveEntity() 而使 XmlReader 到达实体替换的末尾时返回。 EndEntity = 16, // // 摘要: // XML 声明(例如,<?xml version=\'1.0\'?>)。 XmlDeclaration = 17, }
也就是如下代码:
private void button1_Click(object sender, EventArgs e) { XmlDocument doc = new XmlDocument(); doc.Load("XMLFile1.xml"); // 根节点 XmlNode node = doc.DocumentElement; // 遍历根节点的子节点 foreach (XmlNode childNode in node.ChildNodes) { // 【注意1:把根节点中的注释当成子节点】 if (childNode.NodeType != XmlNodeType.Comment) // 判断不等于注释时 { textBox1.Text += childNode.InnerText; } // 遍历根节点的孙节点 foreach (XmlNode item in childNode.ChildNodes) { // 【注意2:把根节点中的子节点的注释当成孙节点】 if (item.NodeType != XmlNodeType.Comment) // 判断不等于注释时 { textBox2.Text += item.InnerText; } } } }
效果图如下:

以上是关于Xml解析之排除注释的主要内容,如果未能解决你的问题,请参考以下文章