通用报文解析服务的演进之路(基于磁盘目录的分布式消息消费者服务)之一
Posted Pleiades
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通用报文解析服务的演进之路(基于磁盘目录的分布式消息消费者服务)之一相关的知识,希望对你有一定的参考价值。
 实现解析器类ParserHandler通过配置自动加载,原理是C#反射Reflection。
实现解析器类ParserHandler通过配置自动加载,原理是C#反射Reflection。
通用报文解析服务,用C#开发,经历了三版更新,支撑起了关区内的绝大多数数据交换业务,截止至今,每日收发报文约20万,数据量约5G,平均延迟在1分钟内。
回想起那些半夜处理积压报文的场景,不胜唏嘘,决定把这个演进过程向大家讲述一下。回顾历史,展望未来,如果能给大家一些启发,是再好不过的了。
由于某些历史和非历史原因,我们的数据交换在已经有IBMMQ等中间件做支撑的情况下,还需要将报文落地到磁盘目录下再做下一步解析、入库。因此就有了这么一个需求,基于磁盘目录的报文解析服务。
初步计划,按照演进过程中的几个版本分成几篇,我们先从第一版开始说起吧。
一、通用报文解析服务V1.0——可配置解析器类
在我来之前,最早的一版是大约两千零几年做的,当时的设计是这样的:
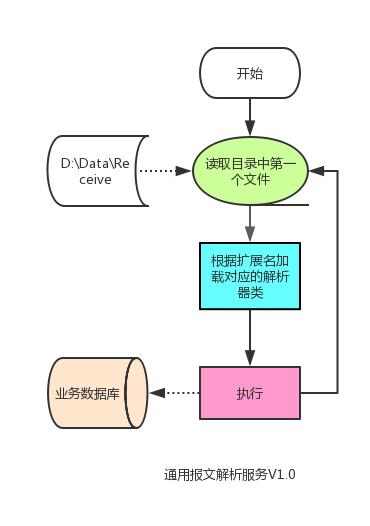
这个程序最大的亮点就是解析器类ParserHandler是可以通过配置自动加载的,原理很简单就是反射Reflection。当因业务需要,有新的报文种类时,只要开发对应的解析器类,编译成类库,再将报文后缀和解析类添加到程序配置文件中即可。
解析器的基类是这样定义的:
///<summary> ///解析器基类 ///</summary> public abstract class BaseHandler { public abstract ParseResult Parse(FileReceiveInfo fileInfo); }
其中ParseResult是枚举,代表解析的结果。
public enum ParseResult { Success, Warning, Error }
FileReceiveInfo是接收到的文件信息,包括文件名、文件内容、接收时间等等,在此不一一列举。
具体的解析器只要继承BaseHandler,实现Parse方法。然后在配置文件中配置某一种扩展名,和这个解析器子类的全名,程序就会自动调用了。
起初报文数量较小时,系统运行还是不错的。它实现了预订数据实时入库的需求,支撑起了关区内的关键业务,而且它的高灵活性,可扩展性也给我们留下了很深的印象。
但是缺点也是很突出的,主要如下:
1) 随着业务量、报文种类的增多,出现了报文长时间积压的问题,高峰时接收目录中几千上万个报文,处理效率却比平时还低。
2) 更要命的时,有时候一个报文解析出错了,查他出错的日志成了很麻烦的事情,因为日志文件相对单一的原因,日志文件变得很大,查起来很不方便。
3) 另外,解析过的历史报文留存也是问题,想日后备查就要存很多文件在磁盘上,占本地磁盘空间,还不好找。
于是决定打造第二代,旨在解决上述三个问题。
欲知后事如何,请听下回分解。
以上是关于通用报文解析服务的演进之路(基于磁盘目录的分布式消息消费者服务)之一的主要内容,如果未能解决你的问题,请参考以下文章