网页中pdf如何下载
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页中pdf如何下载相关的知识,希望对你有一定的参考价值。
网页中pdf如何下载
对于网页中的pdf文件,题主说的有点笼统,我根据不同情况来说一下吧。
复制pdf的下载地址,将其粘贴到迅雷等下载软件中,最后确定下载。
已经在网页中打开了的pdf文件,不同的浏览器会有不同的提示。例如,可以按一下Ctrl+S快捷键或者是点击下载按钮都可以。
对于像Chrome浏览器来说,可以右击,然后打印。将目标打印机选择为另存为PDF。

1、最常用的方法:“选定”网页内容后,右击,选“另存为”,找到存放地址后,保存即可;
2、如从网页上复制过来的内容成乱码,可在“另存为”中,将格式选为txt格式后保存,然后重新排版;要是网上文件有图片,可以先把文字复制到“文本文档”后,再复制到WORD文档,然后在上面插入图片;
3、如禁用了右键菜单(即右键菜单中“另存为”不可用),可选中某网页内容后,点键盘上的组合键Ctri+C进行复制,再打开一文档,点Ctri+V粘贴即可);
4、若上法不可用,可试试先点击左键,不松手,再点击右键。接着松开左键,最后松开右键。如出现快捷菜单,点“另存为”即可保存;
5、用上面三法还是不能复制时: A、先将该网址保存在收藏夹中后(在打开的这个网页中,点收藏、确定);
B、随意打开一个WORD文档(也可以是空白或新建文档),点工具栏中“打开”按钮,在左边的“查找范围”下面点“收藏夹”;
C、在收藏夹下面显示的内容中,找到你刚才保存的网址(即打开了要复制内容的网址),选中要复制的内容并右击,点复制;
D、再打开要存放下载内容的文档,右击后选“粘贴”、保存即可。
6、在网页中,点/查看/源文件,就可打开一个记事本文件,在其中可找到所需要的文字并右击/选“复制”/保存到文档中即可;
7、有时一些网页对源码进行了加密,其复制方法为:
启动IE浏览器,鼠标点击“工具→Internet选项”菜单,选择“安全”标签,点击“自定义级别”按钮,在出现的窗口中将所有脚本全部禁用,然后按F5刷新页面(这时所有的javascript代码都被禁用了,就可对其进行任意的复制、粘贴*操作)。提示:在收集到自己需要的内容后,要给脚本解禁,否则会影响浏览其它网页。 参考技术B 没有下载地址吗?对准下载地址,右键目标另存为。
查看源文件,查找.pdf,如果前边是一个整段的URL的话(如http://www.abc.com/a.pdf),就复制放到迅雷里下载就可以了。本回答被提问者采纳 参考技术C
也许你点击pdf文件下载链接弹出来的是一个网页,想直接下载给你推荐两种办法:
下载时不要直接点击下载链接,而是点击右键 - 目标另存为(或者使用XXX下载)
或者直接点开链接,弹出来的网页地址则是下载地址,复制该网页地址,使用浏览器下载工具新建一个任务,即可下载!
在缓存中可以查找到pdf缓存文件打开后可以看到iE中文件的地址,这样就可以使用迅雷的批量下载了。
下载网页中的 pdf 各种姿势,教你如何 carry 各种网页上的 pdf 文档。
关联词: PDF 下载 FLASH 网页 HTML 报告 内嵌 浏览器 文档 FlexPaperViewer swfobject pdf2swf 。
这个需求是最近帮一个学妹处理一下各大高校网站里的 PDF 文档下载,又增加了无用的逆向知识 XD ,根据这些思路,可以有效的下载这类网站的文档文件。
这需要你有点 HTML5 和 Flash 时代的基础认知,顺便能看 F12 的 network 、cache 等内容,推算真实地址等。
我从最简单的说起,首先准备一个谷歌浏览器,有趣的是需要谷歌浏览器的打印功能,导出到 PDF 上。
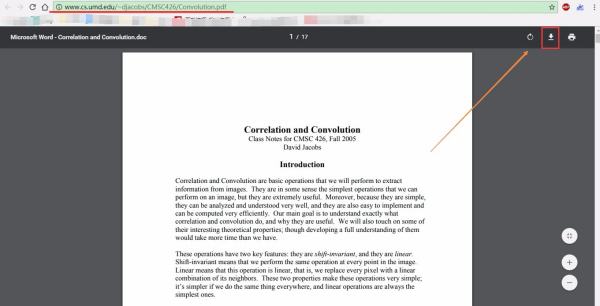
第一种样本,是直接的 .pdf 该类直接下载即可,没有难度。
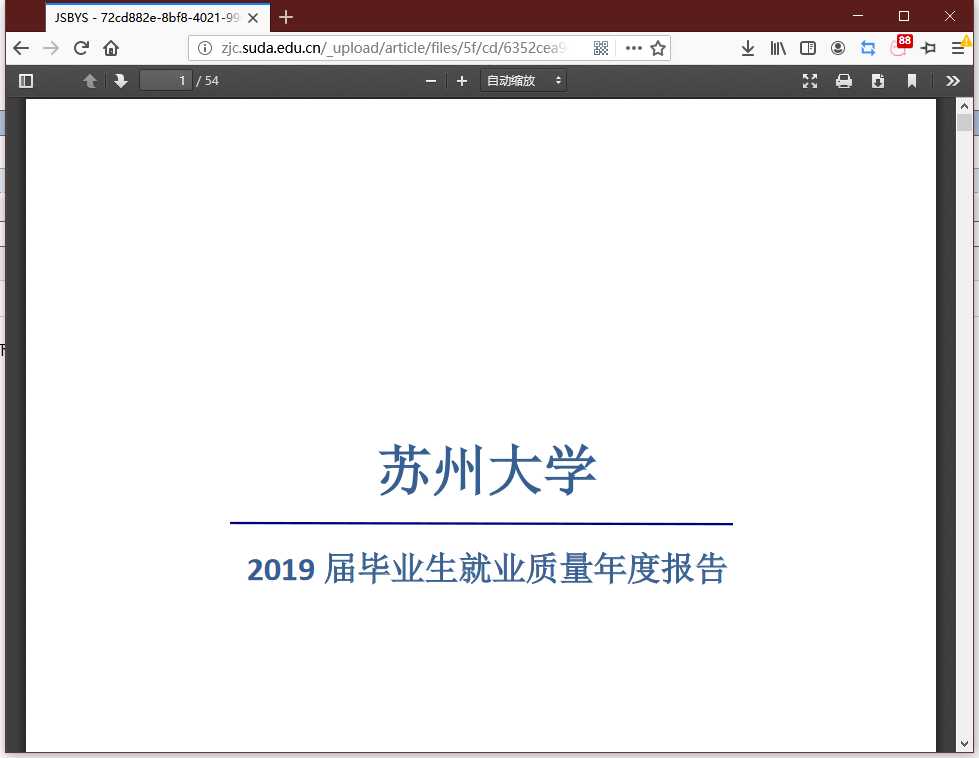
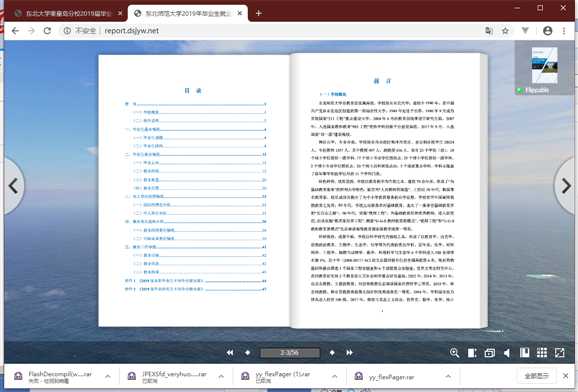
第二种样本,是现代 H5 + JS 内嵌 PDF 浏览器的方式。
属于现代 H5 JS 的产物,需要用 F12 开发者工具看源码推断 PDF 文件路径,接下来截图举例。
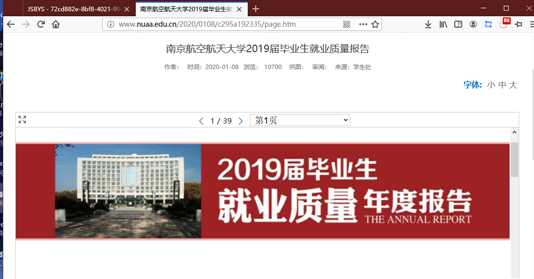
对其右键选检查,此时进入 F12 的 HTML 元素审查位置,可以找到它的定义代码。
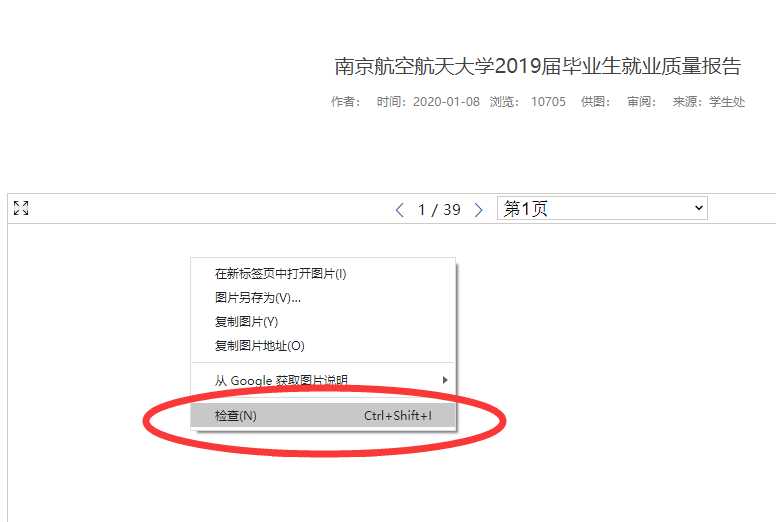
仔细看标签内容可以发现,存在 data-url="/_upload/article/files/3d/8d/78ed42f44031bcb6793b0eb27af1/8e6ad93b-4902-4fd8-bba5-bfabaf852885_1.png" 这类标签。
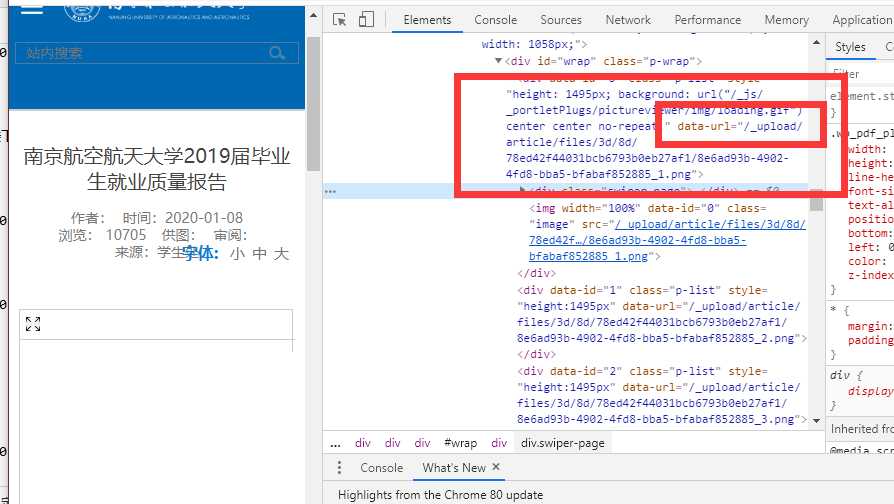
试图搜索(Ctrl + F)页面内容中的 .pdf 文件后缀,就会发现它的文件源存在了 pdfsrc="/_upload/article/files/3d/8d/78ed42f44031bcb6793b0eb27af1/8e6ad93b-4902-4fd8-bba5-bfabaf852885.pdf" 。
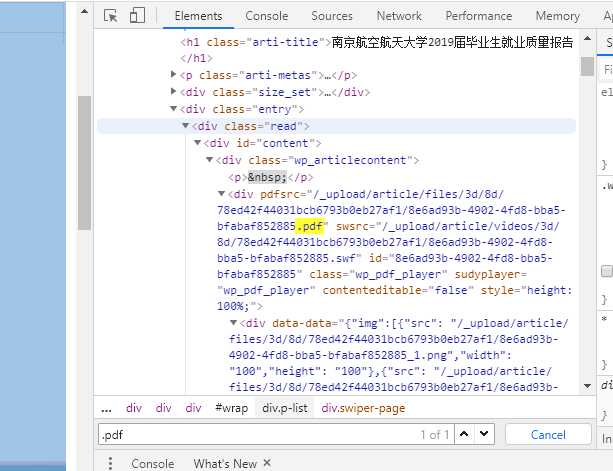
此时需要确定它的服务器源,从而获取真实地址,可以绝大概率是从这里来的。
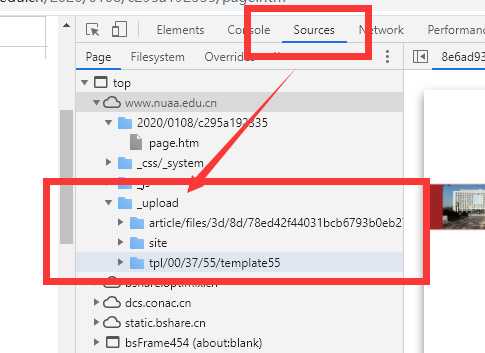
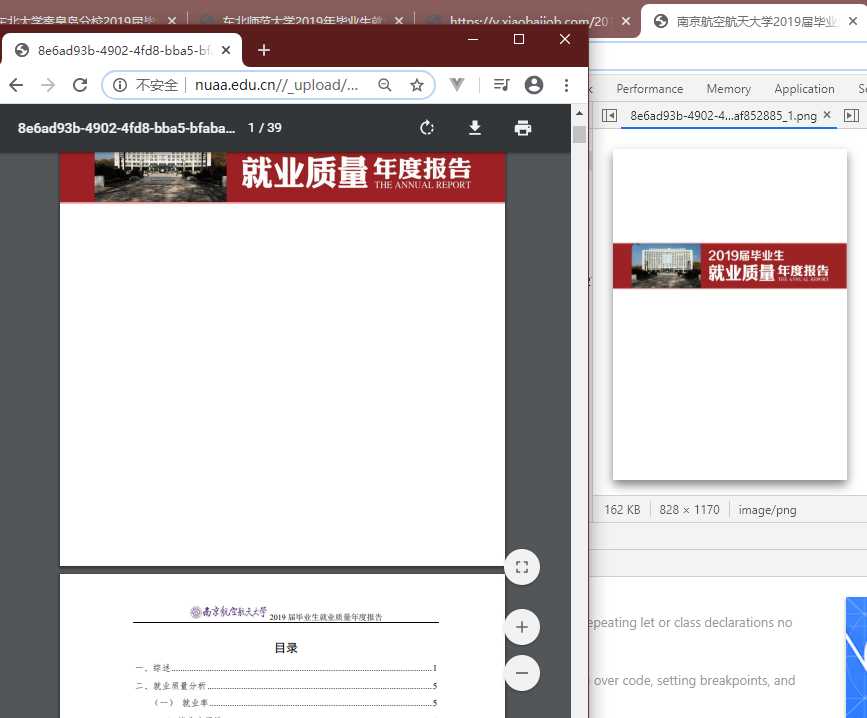
觉得还不太相信?那就再来一个。
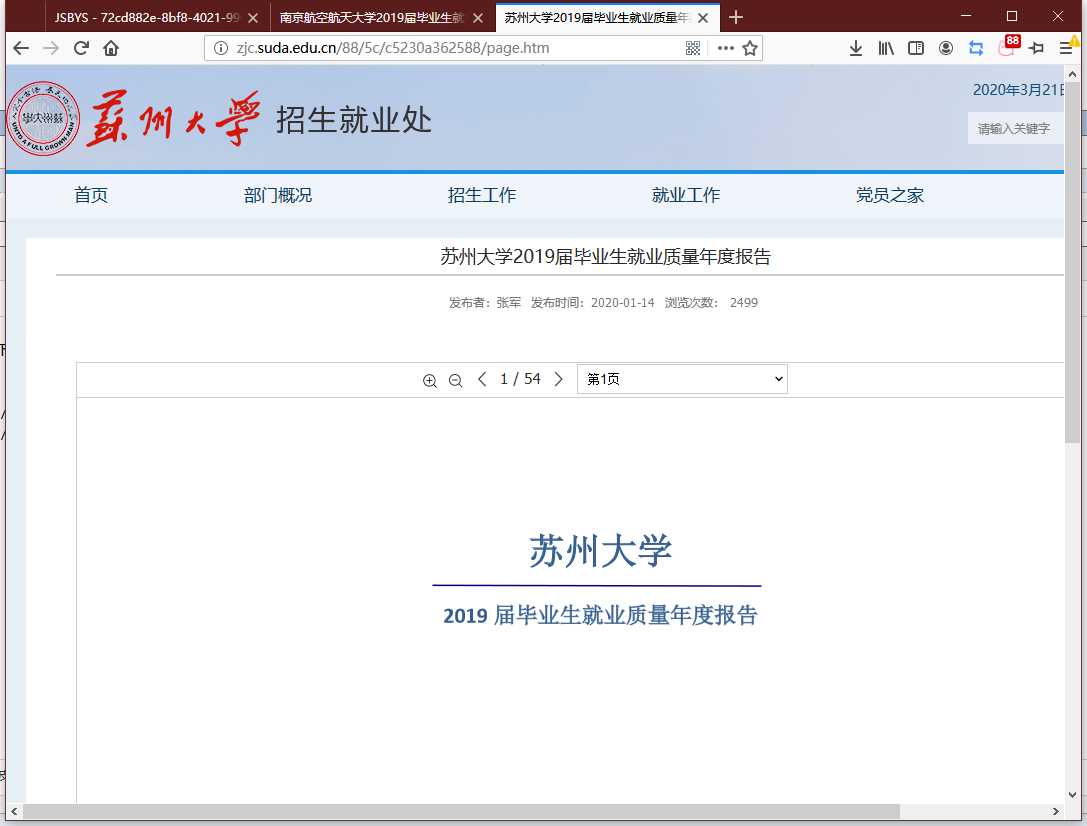
直接进 F12 直接搜 .pdf 直接找到源直接替换直接得到文件路径。
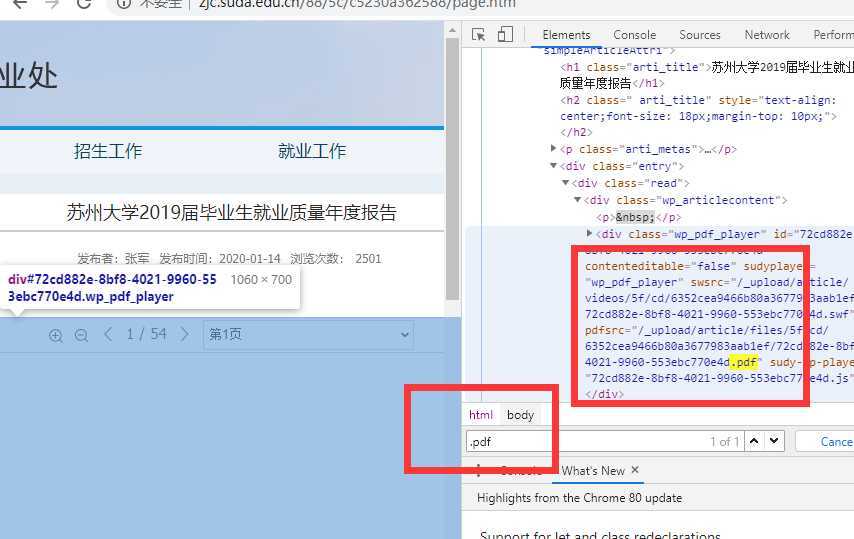
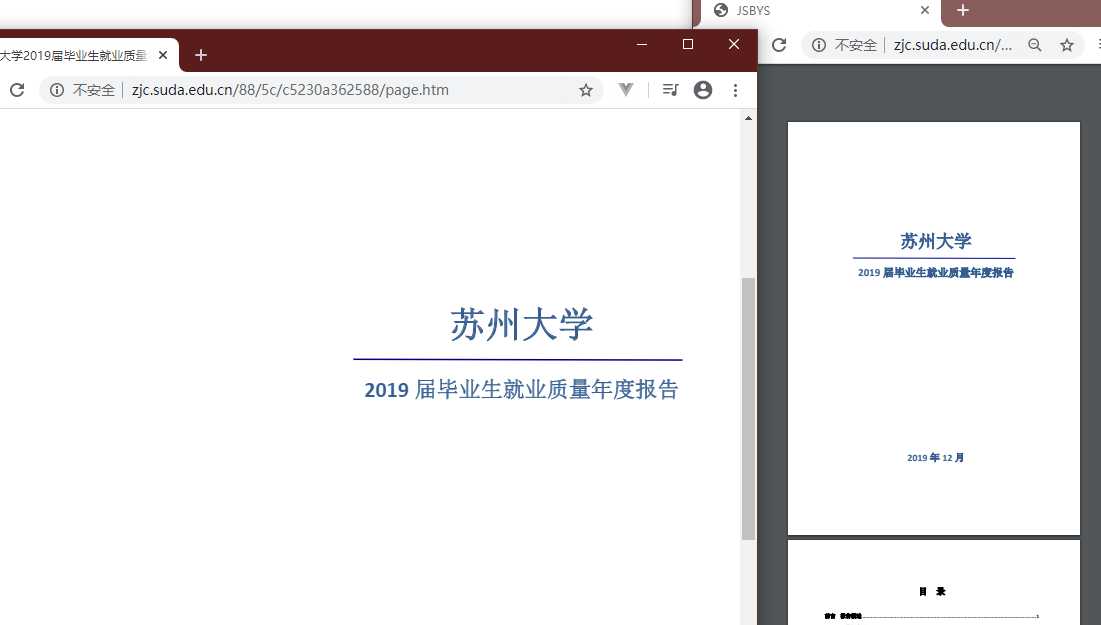
聪明的你学会了吗?接着我们进入第三种样本吧。
第三种样本,旧时代的遗留产物 FLASH 下的 PDF 文档
这个需要一点编程基础了,我之前思路走歪了,现代电脑已经不支持过去的 Flash 软件了,我先是获取了 swf 后试图转换图片、反编译其内容,但能够在 Win10 上 work 的软件已经不多了。
最后痛定思痛,想起,我是个程序猿鸭,为什么要这么耿直的使用工具呢?没错,我直接怼代码进去了,就可以解决了嘻嘻,接下来就是复现这个过程。
注意,针对 swf 转 pdf 问题文件,可以使用 github 的代码去实现,在这里不过多提及,关键词可以是 pdf2swf 和 FlexPaper 使用正向代码解决问题。
只是想起以前浏览器还可以直接读取 flash swf 文件的,不知道为什么现在已经不支持了。
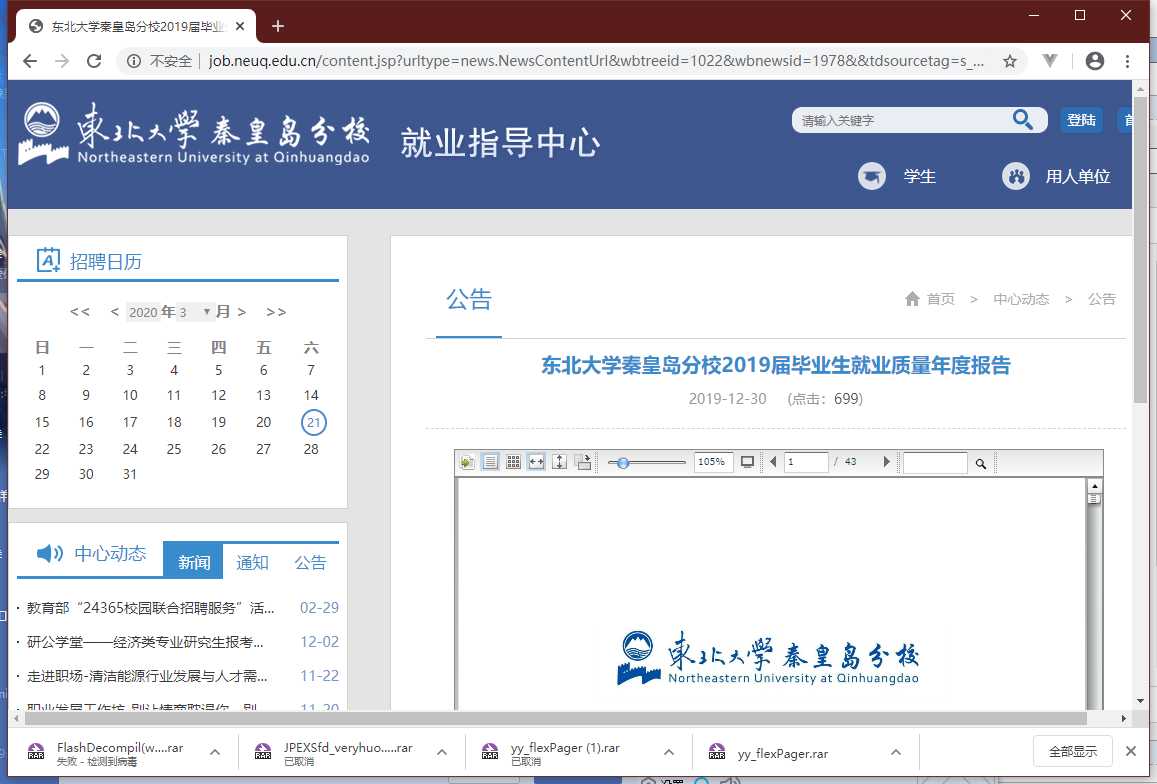
从右键我们可以得知它是 flash 播放器,这个真的没办法通过 html 得到,那么怎么办呢。
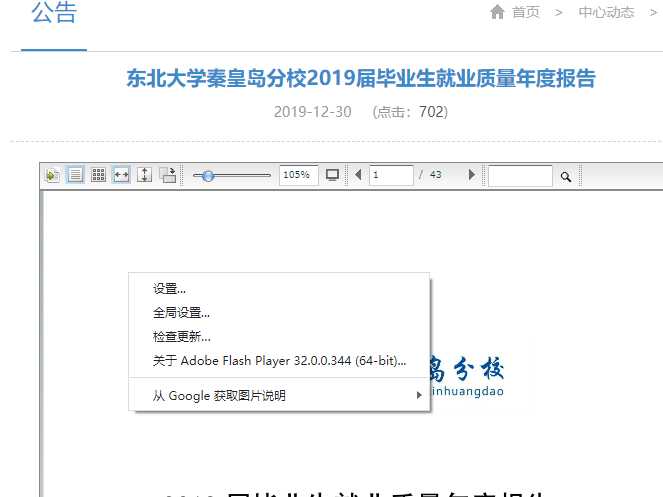
搜索 .pdf 或 .doc 都没用了,根本得不到它的文件,反而可以得到 swf 文件,讲道理,如果是早年间的电脑,相关工具应该还是可以解决问题的,如 swf2png 这类工具。
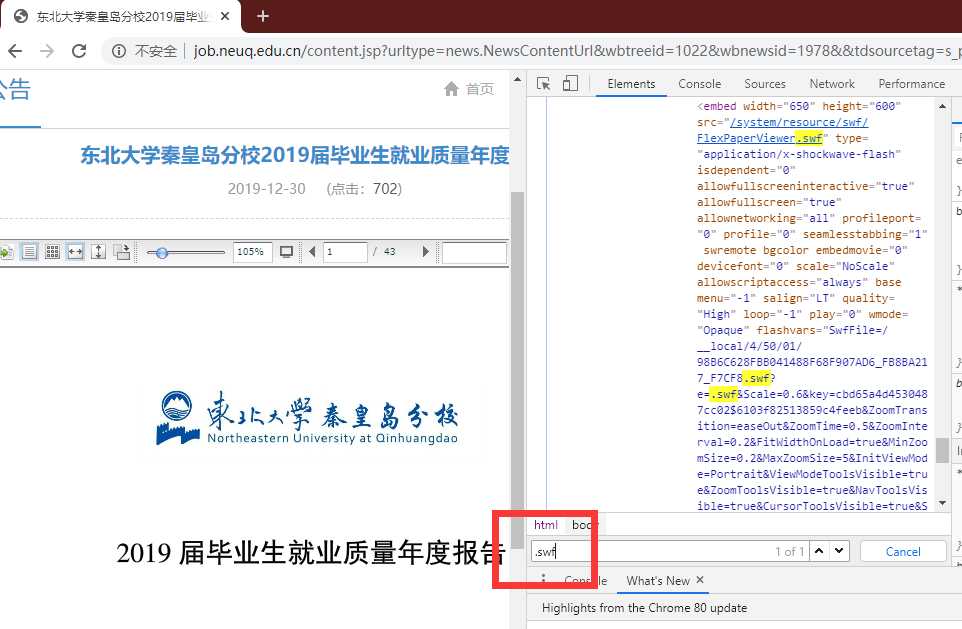
但是 win10 已经无法正常 work 了,那么我在这个地方浪费了很久以后,仔细看了一下它的组件,对,就是 /system/resource/swf/FlexPaperViewer.swf 挺古老的东西了。
顺便一提,谷歌浏览器将在 2020年12月终止 flash 组件。
那么,正面转换 swf 已经不现实了,我开始阅读标签代码,如下图。
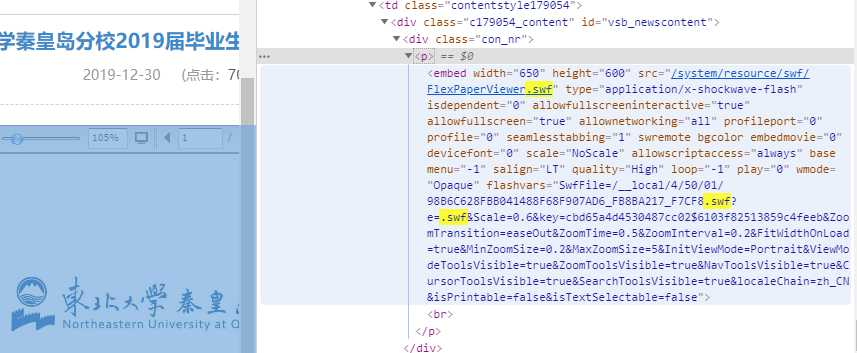
<p><embed width="650" height="600" src="/system/resource/swf/FlexPaperViewer.swf" type="application/x-shockwave-flash" isdependent="0" allowfullscreeninteractive="true" allowfullscreen="true" allownetworking="all" profileport="0" profile="0" seamlesstabbing="1" swremote="" bgcolor="" embedmovie="0" devicefont="0" scale="NoScale" allowscriptaccess="always" base="" menu="-1" salign="LT" quality="High" loop="-1" play="0" wmode="Opaque" flashvars="SwfFile=/__local/4/50/01/98B6C628FBB041488F68F907AD6_FB8BA217_F7CF8.swf?e=.swf&Scale=0.6&key=cbd65a4d4530487cc02$6103f82513859c4feeb&ZoomTransition=easeOut&ZoomTime=0.5&ZoomInterval=0.2&FitWidthOnLoad=true&MinZoomSize=0.2&MaxZoomSize=5&InitViewMode=Portrait&ViewModeToolsVisible=true&ZoomToolsVisible=true&NavToolsVisible=true&CursorToolsVisible=true&SearchToolsVisible=true&localeChain=zh_CN&isPrintable=false&isTextSelectable=false"><br></p>写代码嘛,这里就是定义这个 FlexPaperViewer 组件的调用参数,那么看到 isPrintable=false ,这里 false 就是关,表示停用打印机选项,改成 true 先。
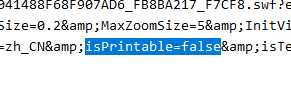
发现没反应,这是因为这时候标签没有刷新,所以编辑一下再保存,让 JS 重载改组件。
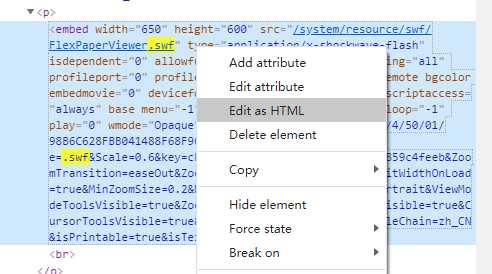
此时你会看到一个神奇的选项出来了,对的,就是打印机,那么你知道怎么做了吗?
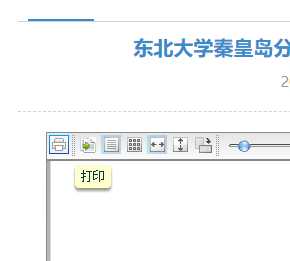
打印它,然后另存为 PDF 就可以了。
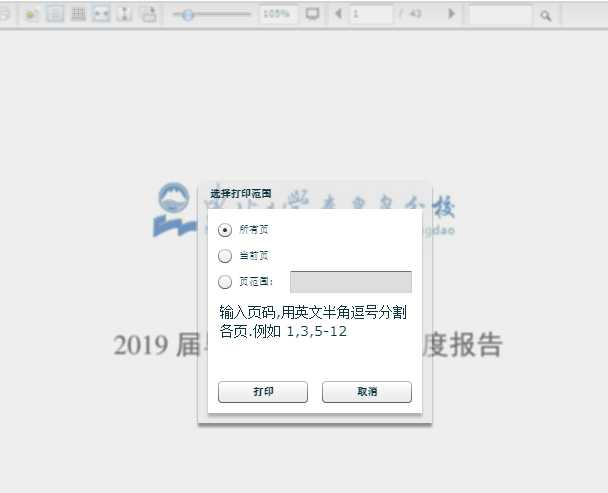
嗯,接下来你都知道了吧。
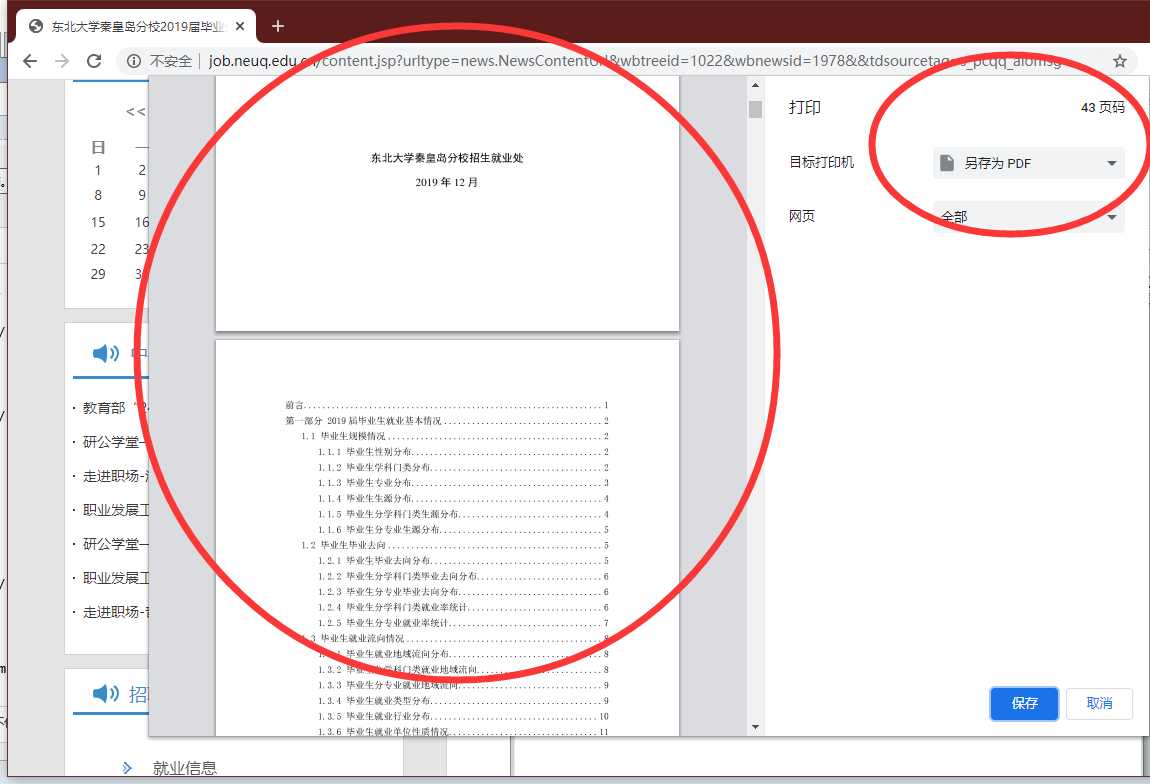
第四种样本,炫酷的动画版 PDF 文档。
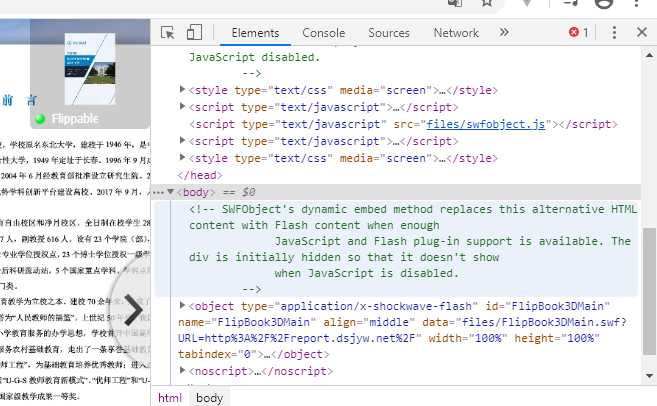
这一种动画制的 PDF 版本,有点复杂,依赖库使用的是 SWFObject 组件,但也不是不能搞,但不能像前面的那种方式处理了。
/*! SWFObject v2.2 <http://code.google.com/p/swfobject/>
is released under the MIT License <http://www.opensource.org/licenses/mit-license.php>
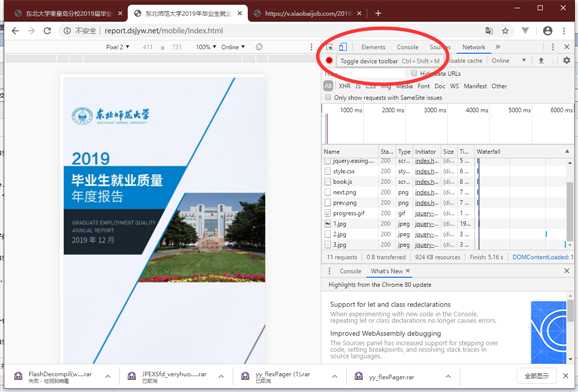
*/现在怎么办呢?打印也没用,文件源也找不到,只好仔细观察 network 的数据流了。
PC 页面下什么也做不了了,那就切换到手机页面试试
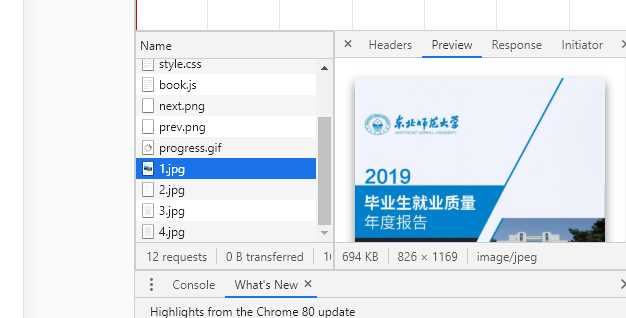
此时注意到 network 的图片文件在随着翻页加载。
现在发现它在获取图片了,这是个好消息。
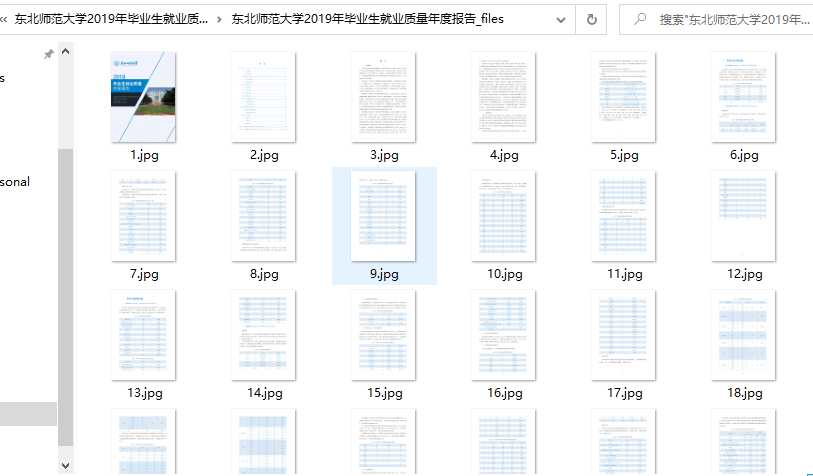
对的,我们可以将全部图片下载下来,然后保存全部网页,包括图片。
有了图片,就可以使用福昕 PDF 图片合并工具了。
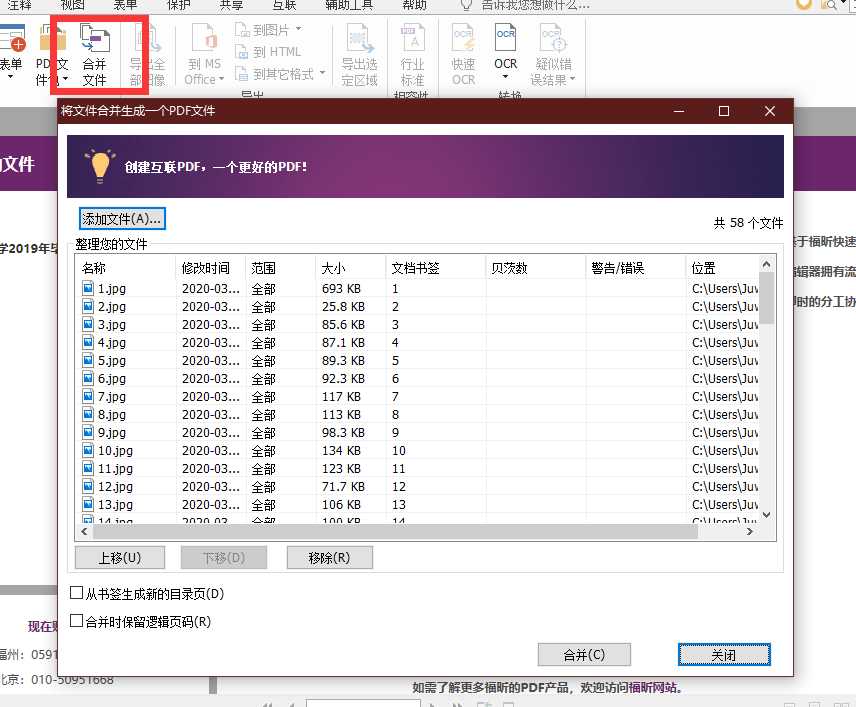
现在就可以得到,但这种方法下得到的像素会有一点损失,并不是最佳的,主要是因为 jpg 的有损显示导致的字体模糊。
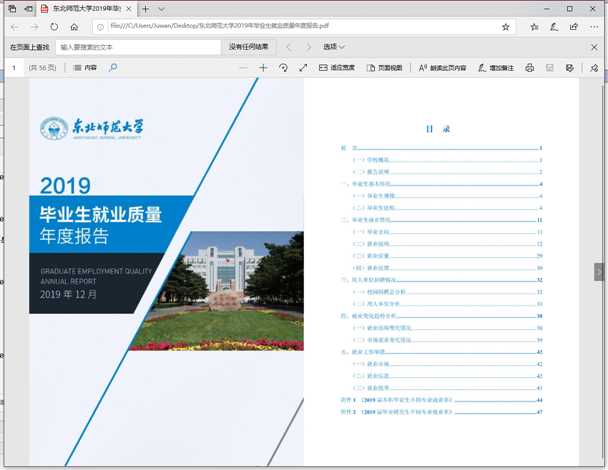
如果你仔细阅读代码,也许可以把打印机的选项开起来,但我看到这个高度封装的 nodejs 产物就没有耐心了(摊手。
第五种样本,恶心的 PPT 视频
没想到吧,还有 MP4 的动画版本。

最后一种的 MP4 样本,我认为可以忽略了,如果真的要处理,那就丢到 ScreenToGif 中取关键帧出来,去除相似度较高的内容即可。
最后,这些内容希望可以给你一些启发,嘻嘻。
以上是关于网页中pdf如何下载的主要内容,如果未能解决你的问题,请参考以下文章