More is Less——卷积网络加速
Posted shuzfan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了More is Less——卷积网络加速相关的知识,希望对你有一定的参考价值。
一篇讲网络加速的论文,来自2017CVPR。
文章链接: 《More is Less: A More Complicated Network with Less Inference Complexitv》
Introduction
目前做神经网络加速的主要有这几个方面: 低秩分解,定点运算、矢量量化、稀疏表示、特殊的轻量级网络结构。
再介绍本文方法之前,需要了解一下常见的卷积是怎样实现的。以caffe中的卷积为例,首先通过im2col将输入展开重排成一个大矩阵,然后执行矩阵乘法。具体可参考知乎上的一个高票回答,图示很清楚,
https://www.zhihu.com/question/28385679?sort=created。
下面用公式说明一下:
假设输入 \\(X\\in R^{H\\times W\\times C}\\), 一共有 \\(T\\)个 \\(k\\times k \\times C\\)大小的卷积核,再假设卷积stride=1且存在padding,即保证输出 \\(V\\) 的大小与输入一致。
首先,通过im2col将输入展开重排成一个大矩阵 \\(\\hat X\\in R^{HW\\times kkC}\\), 卷积核也被整理成了一个矩阵 \\(W \\in R^{kkC\\times T}\\), 于是输出 \\(V\\in R^{H\\times W\\times T}\\) 直接通过矩阵乘法计算:\\(V = \\hat X \\times W\\).
另一方面,我们通常使用ReLu来对进行激活处理: \\(\\hat V_{i,j,c} = max(V_{i,j,c},0)\\). 结合上面的卷积实现原理,我们可以看出如果激活后某个点的所有通道都为0,就相当于在矩阵乘法时可以直接省略 \\(\\hat X\\)的相应行。 遗憾的是,这有一点马后炮的感觉,因为我们计算完之后才知道是不是会得到0.
本文实现加速的核心就是:提前锁定哪些值将会为0,从而在矩阵乘法时直接避免相应运算。
Method
整体的实现如下图:
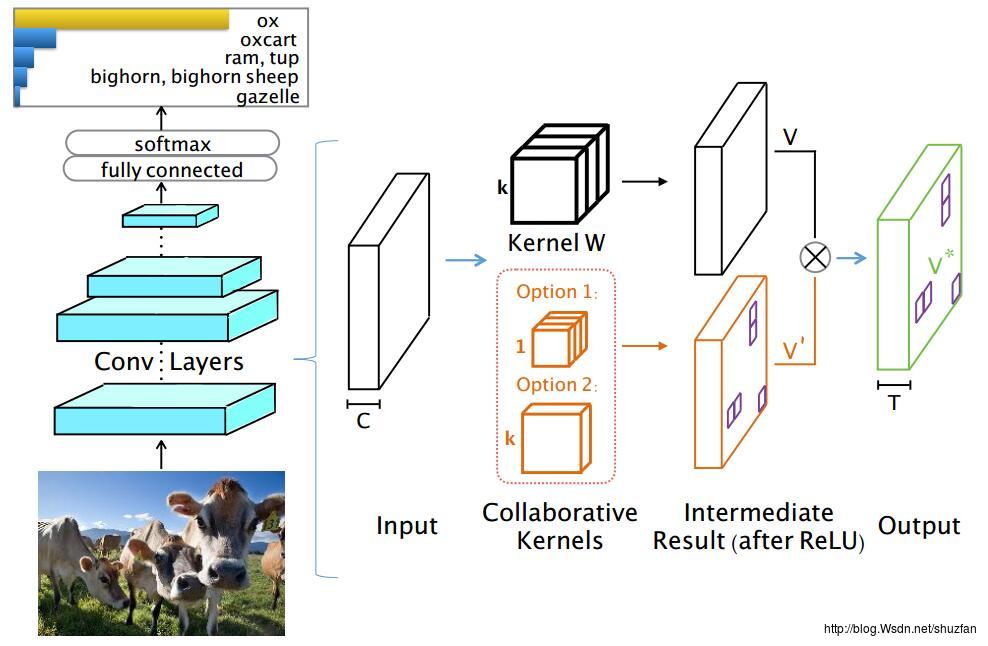
如上图,还是先假设输入 \\(X\\in R^{H\\times W\\times C}\\), 一共有 \\(T\\)个 \\(k\\times k \\times C\\)大小的卷积核,再假设卷积stride=1且存在padding,即保证输出 \\(V\\) 的大小与输入一致。
黑色部分表示原始结构的卷积,橘黄色部分表示新增的一个辅助层,该辅助层的卷积参数有两种选择,第一种是 \\(1\\times1 \\times C\\times T\\),第二种是 \\(k\\times k\\times C\\times 1\\),以第二种为例,其卷积输出为 \\(V^{‘} \\in R^{H\\times W\\times 1}\\)。
\\(V^{‘}\\)由于经过ReLU和一些稀疏约束,因此只有一部分值不为0。因此,根据\\(V^{‘}\\)我们可以控制计算原始卷积 \\(V\\)时,省略掉展开矩阵 \\(\\hat X\\) 的对应行,从而完成加速。
文章解释了为什么不使用第一种\\(1\\times1 \\times C\\times T\\)来产生\\(V^{‘}\\),主要是因为这会导致没办法一次完成所有矩阵乘法。
从上面的解释来看,\\(V^{‘}\\)的稀疏度决定了加速比。
为了让 \\(V^{‘}\\) 更稀疏,文章一方面使用了ReLU激活,同时也尝试对 \\(V^{‘}\\)进行平滑的稀疏正则化\\(L_1L_2(x) = \\mu||x||+\\rho |x|\\), 但是发现很难优化。
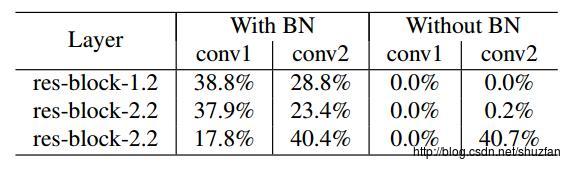
后来作者发现BN+ReLU可以使得输出更稀疏:
Conclusion
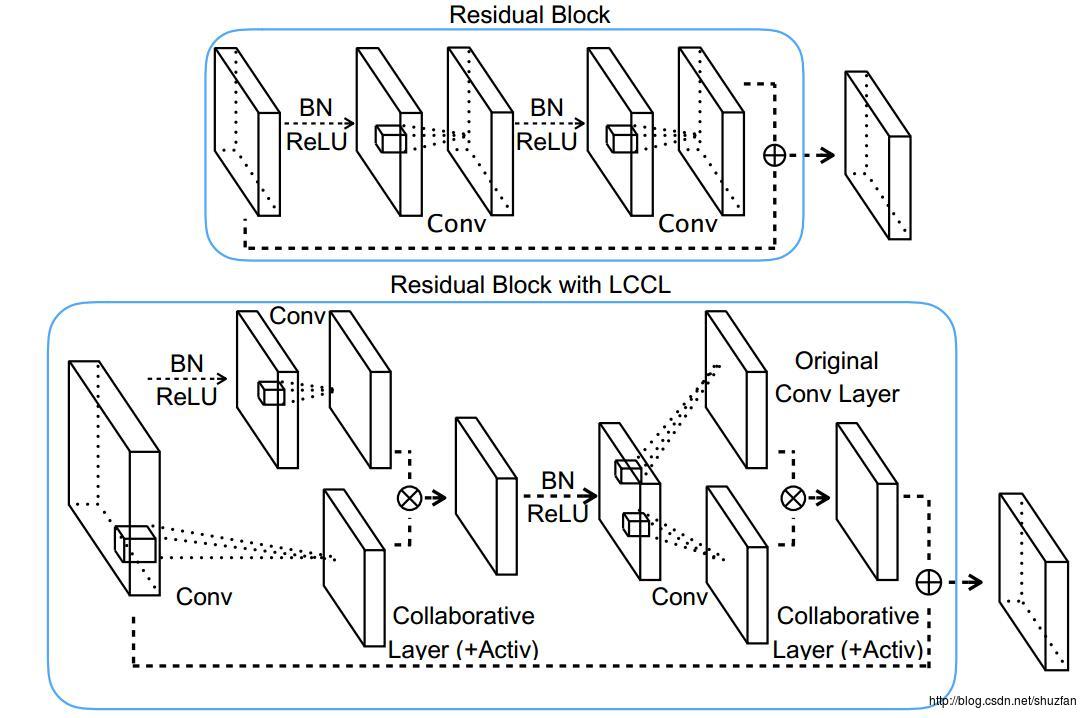
文章将该方法称为low-cost collaborative layer (LCCL)。 Idea很赞,但是考虑到带来的训练难度,其产生的加速效果就不是很令人满意了。
文章在ResNet上进行了实验,下图是网络的基本模块:
 ,
,
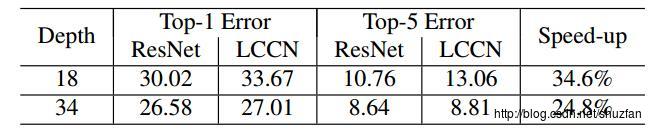
下图是在ImageNet上的实验结果:
以上是关于More is Less——卷积网络加速的主要内容,如果未能解决你的问题,请参考以下文章
Paddle Fluid 加速float16卷积神经网络预测