基于深度学习的图像语义编辑
Posted 张雨石
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于深度学习的图像语义编辑相关的知识,希望对你有一定的参考价值。
深度学习在图像分类、物体检测、图像分割等计算机视觉问题上都取得了很大的进展,被认为可以提取图像高层语义特征。基于此,衍生出了很多有意思的图像应用。
为了提升本文的可读性,我们先来看几个效果图。


图1. 图像风格转换

图2. 图像修复,左上图为原始图,右下图为基于深度学习的图像

图3. 换脸,左图为原图,中图为基于深度学习的算法,右图为使用普通图像编辑软件的效果

图4. 图像超清化效果图,从左到右,第一张为低清图像三次插值结果,第二张残差网络的效果,第三张为使用对抗神经网络后的结果,第四张为原图。
卷积神经网络(For starters)
深度学习在图像领域表现较好的是卷积神经网络,在自然语言处理领域的则是递归神经网络。本文所介绍的内容都是卷积神经网络的。
普通的神经网络是上一层神经元与下一层神经元全连接的非线性变换。如图5所示,其数学表达如图6所示。
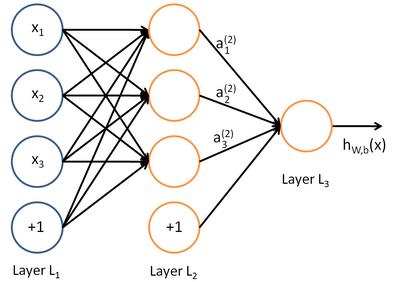
图5. 神经网络示意图
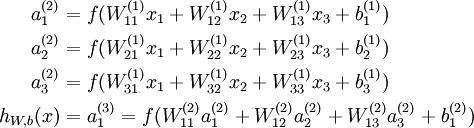
图6. 神经网络的数学表达
而卷积神经网络则可以看做局部连接的非线性变换。一个卷积单元的示意图如图7所示。由该图可以看到,一个卷积核划过整张图像,得到一张新的图像。其中卷积核是卷积神经网络的参数,将由神经网络从数据中学习得到。经过卷积核处理后的图像称之为特征图。
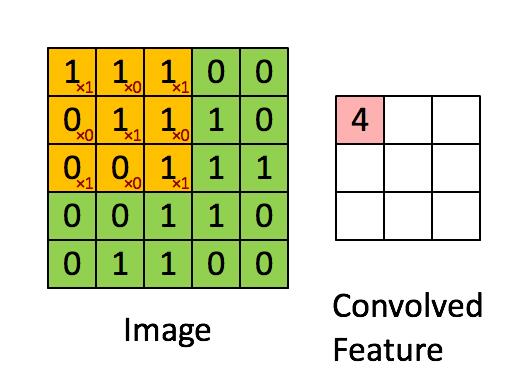
图7. 卷积单元示意图
将多个卷积单元组合就可以形成一个卷积层。多个卷积层顺序处理图像就形成了深度卷积神经网络。每一个卷积层所有卷积单元的特征图组合起来称之为图像在该层的特征表示。
图像风格转换-V1
作为基于深度学习图像生成的第一个引爆点,图像风格转换将图像A的内容与图像B的风格糅合的一起,形成一张别出心裁的新图像。
图像的生成过程: 想象存在一张图像S,我们使用迭代的方式来从一张噪音图像N中复原它。那么我们可以定义一个损失函数E,E为S中每个像素和N中对应位置的像素的欧式距离的平方(欧式距离)。此时对N中的每个像素位置求导数,然后将导数乘以一个系数alpha然后加到N中该位置的像素上,从而得到一个更接近图像S的图像,逐步迭代,直至得到与S相差无几的图像。
图像风格转换是利用了卷积神经网络可以提取高层特征的效果,不在像素级别进行损失函数的计算,而是将原图像S和生成图像S都输入到一个已经训练好的神经网络里,在得到的某曾特征表示上计算欧式距离(内容损失函数)。这样得到的图像能够得到与原图内容相似但不必像素级别的相似,更具鲁棒性。
在卷积神经网络里的特征表示上计算欧式距离可以很好的复原内容。但是神奇之处来了,或许是随机尝试,或许是验证某个经过精确推导的数学公式,又或许是直觉的引导,某人发现了利用卷积神经网络提取风格特征的方法。
图像在某个卷积层的特征图统称为特征表示,那么在特征图之间两两求相关度,得到相关性矩阵,在原图像S和生成图像S的相关性矩阵上求欧式距离(风格损失函数)会如何呢? 答案就是提取出图像的风格特征。
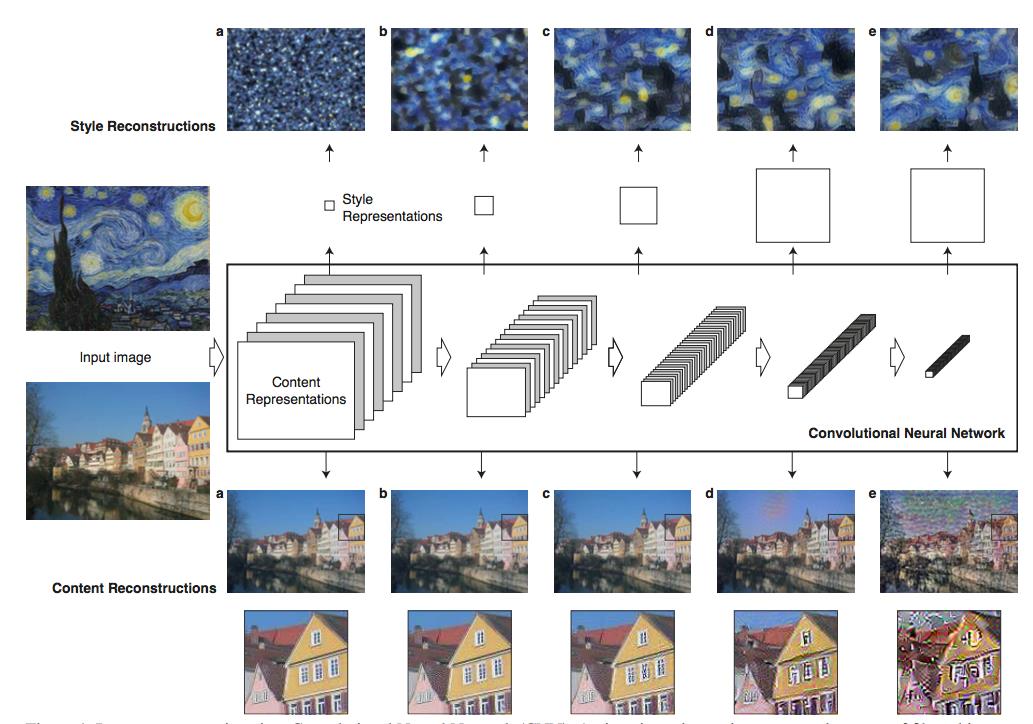
图8. 风格重建和内容重建
图8中是分别采用风格损失函数和内容损失函数进行图像复原,上半部分是在不同层次的特征图上进行风格损失函数计算得到的不同的风格重建结果。下半部分则是在不同层次的特征表示上计算内容损失函数得到的不同的内容重建结果。
而将这两种损失函数加权组合起来,就得到了一张具有图像B的风格和图像A的内容的图像了。

图像风格转换-V2
上述方法对每一张图像都需要反复迭代多次进行求导,非常慢。所以首个图像风格转换应用Prisma在创业初期的做法是将图像传到GPU服务器上进行处理然后返回结果,导致服务器不堪重负经常不响应。
于是快速方法应运而生,网络结构如图5所示。在图5中,仍然是使用上述损失函数,但是不再是对噪声图像进行求导迭代,而是训练一个变换网络,将内容图像作为输入,然后将在变换网络的输出上计算内容和风格损失。这样,在变换某一张图像的时候,只要将这样图像输入进网络,做正向网络计算就能直接得到风格转换后的结果。
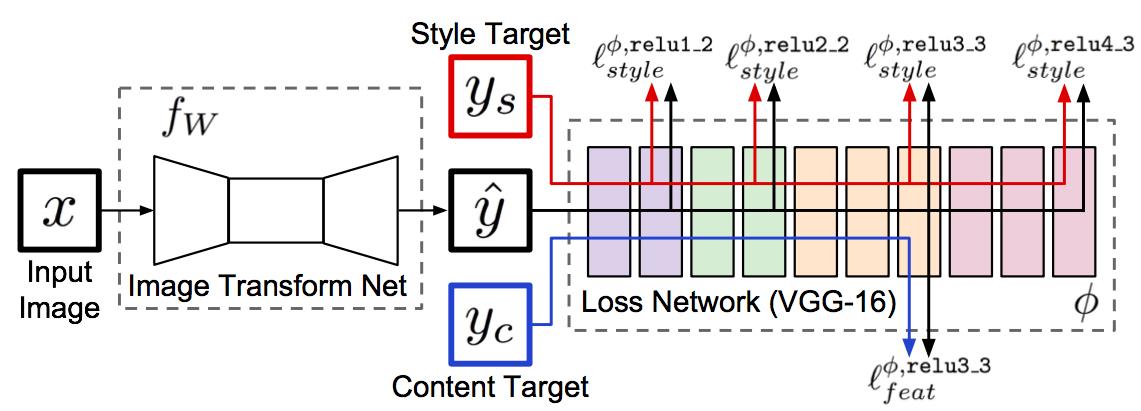
图9. 快速风格转换算法框架
图9的算法框架稍作变换就可以应用于图像超清化问题。在风格转换问题中,x和yc都是原图像,ys是风格图像。而在图像超清问题中,将风格图像和风格损失都去掉,然后x为低分辨率图像,yc为高分辨率图像,以此,可以将变换网络训练成处理超清化问题的网络。
图像风格转换-V3
V1和V2中都使用Gram矩阵来提取风格,这个方法没有严格的数学推导,比较tricky;在实践中也有混合不当的问题。如图10所示。

图10. 使用Gram矩阵时混合不当问题效果图
为了解决这个问题,V3算法中去除了Gram矩阵的应用,而是使用了最近邻算法。
将内容图像和风格图像都分为多个Patch,在各个Patch上计算损失函数,而整张图像的损失函数则为所有Patch上损失函数之和。
对于每个Patch而言,内容损失同上,但风格损失不再计算Gram矩阵,而是计算Patch的特征表示和风格图像中特征表示最接近的Patch的欧式距离。这样,既能达到更加平滑的效果,又可以摆脱Gram矩阵这样比较tricky的东西。效果对比如图11所示。

图11. 风格转换效果图,左图为内容图像,中图为V1算法的结果,右图为V3算法的效果
图像风格转换的三种典型算法至此就全部阐述了,换脸、图像修复和图像超清化均和这上述三种算法有密切的联系。
换脸
由于换脸是只针对人脸的操作,因而除了卷积神经网络外,还需要一定的预处理步骤,即将原图的人脸和目标人脸进行对齐。预处理步骤如图12所示。
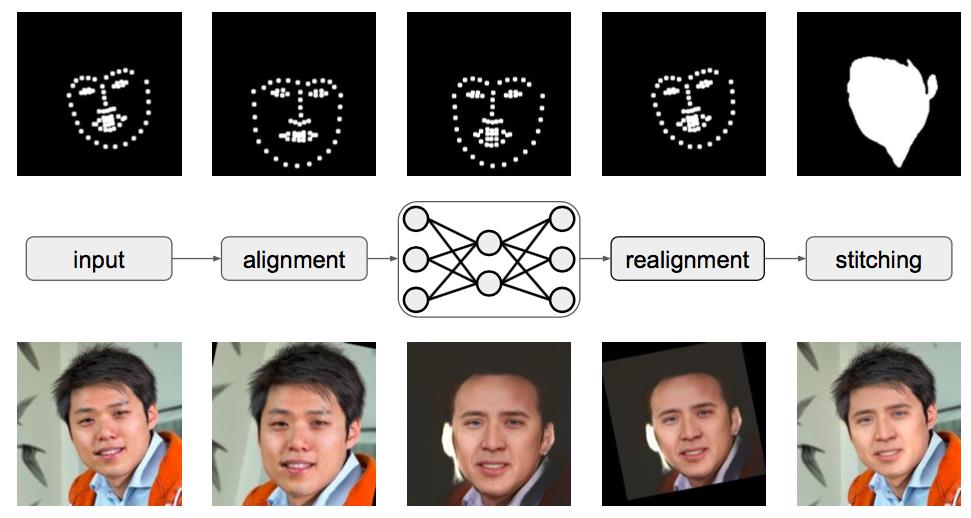
图12.原图人脸和目标人脸的对齐
在预处理中,使用两种现有的技术,一种是人脸标定,即识别出人脸上的68个关键点,然后依据这68个关键点将人脸进行对齐。另一种是前后景切分,将人脸从背景中分割出来,只对人脸进行操作。
换脸时使用的卷积神经网络架构同图像风格转换-V3很类似,即输入图像是原图,目标人脸图像是风格图像。不同的地方有两点:
- 需要目标图像的多张图像来适应不同的表情,也即神经网络不能产生表情,而是在目标图像中寻找最相似的表情。
- 在使用最近邻来寻找Patch的时候,会根据关键点的位置进行搜索域的限制,即眼部的Patch只在目标图像的眼部附近进行搜索,但由于目标图像有多张,因而可以在多张图像上进行查找。
换脸效果如图13所示。

图13.使用Nicolas Cage和Tylar Swift对某章图像进行人脸替换,第一行为原图,第二行为Cage替换结果,第三行为Swift替换结果
图像修复
本文所言的图像修复问题是指依据现有的图像信息,将图像中缺失的部分复原回来。其实在该问题上,如果缺失部分有残存部分不存在的信息,是不能复原的。所复原后的图像是用背景将缺失部分进行填充。但即便如此,图像复原的效果也依然令人震撼。
深度学习下的图像修复算法可以看做是图像风格转换-V1,图像风格转换-V2和图像风格转换-V3的组合体。如图14所示。
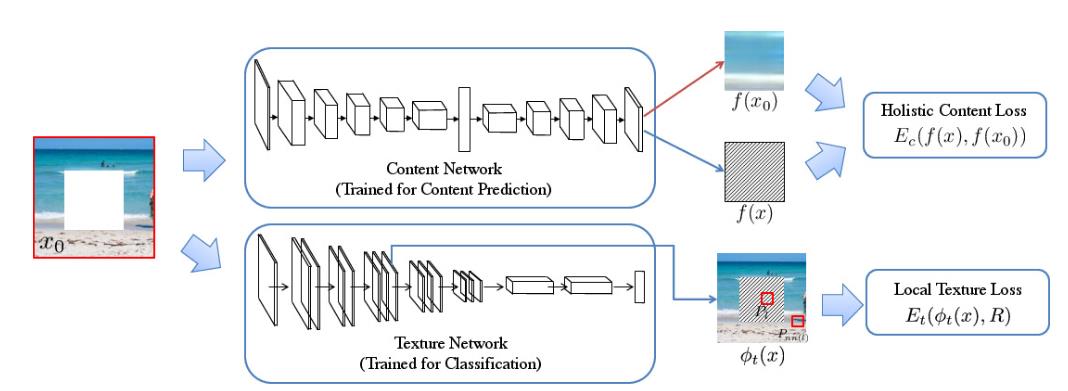
图14. 图像修复的卷积神经网络框架
算法步骤分为两步走:
- x0输入进内容生成网络得到生成图片x
- x作为最后生成图像的初始值,保持纹理生成网络的参数不变,使用Loss NN对x进行梯度下降,得到最后的结果。
内容生成网络(Content Network)类似于图像风格转换-V2的结构,训练一个转换网络将缺失图像补全。但仅仅是这样并不能得到比较好的效果,还需要对纹理进行进一步的细化。纹理网络则是结构上同图像风格转换-V1算法类似,直接对图像进行求导,是图像越来越接近真实图像,但损失函数上却与图像风格转换-V3类似,在全局域内寻找最相似的Patch来进行损失函数的计算。
算法效果如图15所示。

图15. 使用图像修复算法进行物体移除,从左到右,第一张为原图,第二张为移除物体后的图像,第三张为非卷积网络算法处理结果,第四张为深度学习算法处理结果
图像超清
图像超清化算法的结构如同图像风格转换-V2,但在神经网络上有一些特殊性。如图16所示。
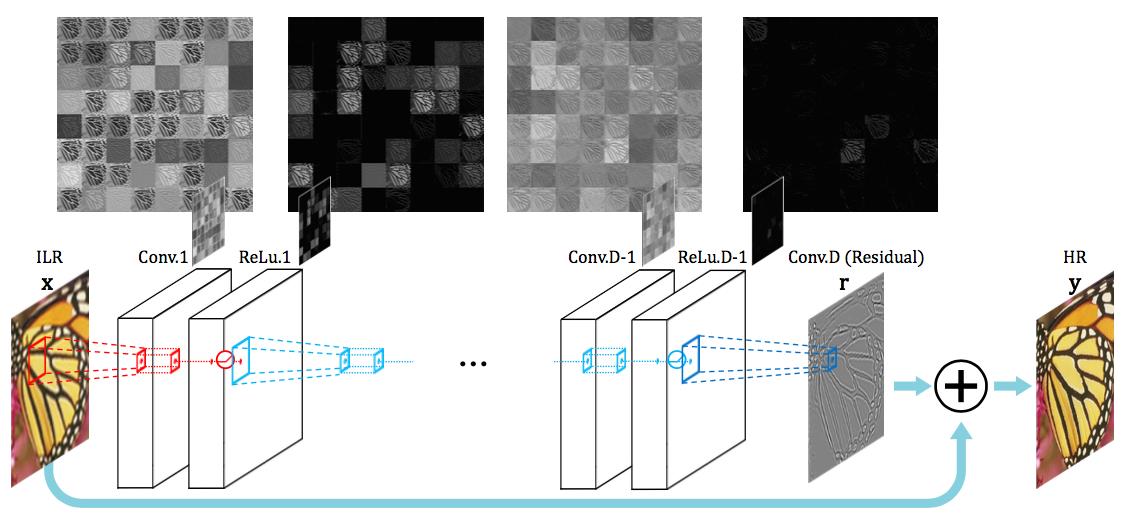
图16. 图像超清化网络结构
由于输入图像与输出图像有极大的相似性,因而,不需要让神经网络每一层都学习全部的图像信息,而是让神经网络学习到高清图像和低清图像的差值即可。
为了达到这种效果,在网络结构上进行如下变动。在处理的时候,首先,使用三次插值法将低清图像变为高清图像的尺寸,然后让神经网络学习高清图像与低清图像之差。
这种网络结构也称之为skip-connection,是最近热火的残差网络的基础之一。
自然,此处阐述的算法是最基本的算法,还有更加复杂的算法,比如基于对抗神经网络的算法和基于PixelCNN的算法等。
总结
本文首先介绍了图像风格转换的三种典型算法,然后以此为出发点,介绍了基于类似技术的另外三个应用,即图像修复,图像超清化和换脸。这些问题都属于图像生成问题。
在图像生成问题领域,还有很多前沿的技术是本文所没有涉及的,比如对抗神经网络和PixelCNN,这两种算法在图像超清领域已经有了比本文介绍的算法更好的效果。对抗神经网络甚至在很多其他的图像语义编辑问题上也有了很好的效果应用。
深度学习是一门正在快速变化的技术,新的技术突破与创新层出不穷。虽然不能真正达到AI的效果,但确实能够帮助我们在语言理解和图像理解上前进一大步。
引申链接
更多文章欢迎关注微信公众号【雨石记】。

以上是关于基于深度学习的图像语义编辑的主要内容,如果未能解决你的问题,请参考以下文章