机器学习 —— 基础整理:非参数方法——Parzen窗估计k近邻估计;k近邻分类器
Posted Determined22
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习 —— 基础整理:非参数方法——Parzen窗估计k近邻估计;k近邻分类器相关的知识,希望对你有一定的参考价值。
本文简述了以下内容:
(一)生成式模型的非参数方法
(二)Parzen窗估计
(三)k近邻估计
(四)k近邻分类器(k-nearest neighbor,kNN)
(一)非参数方法(Non-parametric method)
对于生成式模型(Generative model)来说,重要的地方在于类条件概率密度 $p(\\textbf x|\\omega_i)$ 的估计。上一篇介绍的参数方法,假定其是一个固定的分布密度形式,然后估计这个显式表达的函数中未知的参数。但这里存在两个问题:首先,假定的形式可能是不准确的,实际数据并不符合这个假设;其次,经典的密度函数的参数形式都是单模的(单个局部极大值),实际上常常会有多模的情况。
非参数方法的做法是,不假定密度的形式,直接从样本来估计类条件概率密度 $p(\\textbf x|\\omega_i)$ 。注意:有些地方会把判别式模型(Discriminative model)也称为非参数方法。如果讲的泛一点的话,“非参”这个词可以用在很多地方,例如非参贝叶斯方法(Nonparametric Bayesian methods),就是指参数个数可以随着数据的变化而自适应变化。
考虑一个点 $\\textbf x$ 落在区域 $\\mathcal R$ 中的概率:
$$P=\\int_{\\mathcal R}p(\\textbf x\')\\text d\\textbf x\'$$
其中 $p(\\textbf x)$ 是概率密度函数。设有 $n$ 个服从 $p(\\textbf x)$ 的iid样本 $\\textbf x_1,...,\\textbf x_n$,并且有 $k$ 个样本落在区域 $\\mathcal R$ 。根据二项分布的均值我们可以知道,$k$ 的期望值是 $nP$ 。
现在假设这个区域足够小(体积 $V$ 、样本数 $k$ ),使得该区域内部是等概率密度的,那么可以有
$$P=\\int_{\\mathcal R}p(\\textbf x\')\\text d\\textbf x\'\\simeq p(\\textbf x)V$$
从以上式子,就可以得到 $p(\\textbf x)$ 的估计为
$$p(\\textbf x)\\simeq \\frac{k/n}{V}$$
其实这个式子很好理解,就是“密度等于概率除以体积”。这里不讨论太理论化的东西了,直接说怎么做。
为了估计点 $\\textbf x$ 处的概率密度 $p(\\textbf x)$ ,采取的做法是构造一系列包含点 $\\textbf x$ 的区域 $\\mathcal R_1,...,\\mathcal R_n$ ,进而产生一个估计序列,该序列收敛到的值就是真实的概率密度。那么对 $p(\\textbf x)$ 的第 $n$ 次估计可表示为
$$p_n(\\textbf x)=\\frac{k_n/n}{V_n}$$
上式在 $n\\rightarrow\\infty$ 时收敛到 $p(\\textbf x)$ 的条件有三个:$V_n\\rightarrow 0$ 、$k_n\\rightarrow\\infty$ 、$k_n/n\\rightarrow 0$ 。
很明显,为了得到这个估计序列,可以有两种处理方式:
1. 固定局部区域的体积 $V$ ,$k$ 改变,这就是Parzen窗估计。换言之,就是当 $n$ 给定时,要求 $V_n$ 唯一确定,再求出此时的 $k_n$ ,进而求得 $p_n(\\textbf x)$ 。
2. 固定局部区域的样本数 $k$ ,$V$ 改变,这就是k近邻估计。也就是说,当 $n$ 给定时,要求 $k_n$ 唯一确定,再求出此时的 $V_n$ ,进而求得 $p_n(\\textbf x)$ 。

图片来源:[1]
(二)Parzen窗估计(Parzen window)
一、窗函数与窗宽
Parzen窗估计通过改变区域内的样本数来获得估计序列。先举一个简单的例子:设 $\\mathcal R_n$ 是一个窗宽为 $h_n$ 的 $d$ 维超立方体,则局部区域的体积为 $V_n=h_n^d$ 。定义窗函数 $\\phi(\\textbf u)$ :
$$\\phi(\\textbf u)=\\begin{cases} 1,&\\quad |u_j|\\geq\\dfrac12;\\\\0,&\\quad\\text{otherwise.} \\end{cases}$$
对于一维的情况,该函数的图像如下图所示。如果是高维的,那么每一维都是这样的。
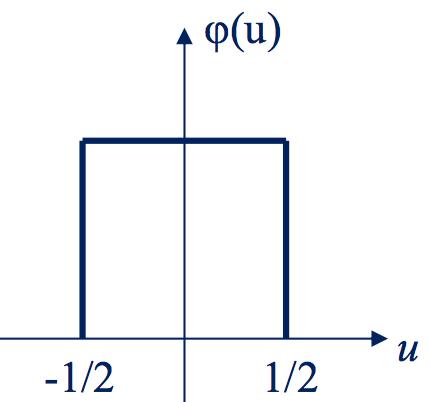
图片来源:[1]
显然,$\\phi(\\textbf u)$ 表示的是一个中心在原点的单位超立方体。在窗函数定义好之后,可以求得以 $\\textbf x$ 为中心、体积为 $V_n=h_n^d$ 的局部区域内的样本数:
$$k_n=\\sum_{i=1}^n\\phi(\\dfrac{\\textbf x-\\textbf x_i}{h_n})$$
这个式子中,$\\textbf x$ 是特征空间内任一点,$\\textbf x_i$ 是 $n$ 个iid样本点。当一个样本 $\\textbf x_i$ 落在局部区域内时,有 $\\phi(\\dfrac{\\textbf x-\\textbf x_i}{h_n})=1$ ,所以累加和可求得局部区域内的样本数。
将上式代入 $p_n(\\textbf x)$ 的表达式,便可估计概率密度函数:
$$p_n(\\textbf x)=\\frac{1}{nV_n}\\sum_{i=1}^n\\phi(\\dfrac{\\textbf x-\\textbf x_i}{h_n})$$
例如,令 $h_n=\\dfrac{h_1}{\\sqrt n}$ ,这样随着 $n$ 的变化得到了估计序列。
实际上,上式给出了一个一般化的估计方式,它规定了窗函数的作用在于:明确样本点 $\\textbf x_i$ 对于点 $\\textbf x$ 的密度函数估计所起到的贡献,贡献大小由两个点的距离来决定。因此,窗函数不一定是上面的形式,只要使得估计出来的密度函数 $p_n(\\textbf x)$ 满足概率密度函数应有的性质(例如,积分为1)即可。因此,要求窗函数满足:
$$\\phi(\\textbf x)\\geq 0,\\quad \\int\\phi(\\textbf u)\\text{d}\\textbf u=1, \\quad V_n=h_n^d$$
Parzen窗估计中,如果窗函数的形式是规定好的,那么密度估计的效果好坏将取决于窗宽。例如有两个模型,分别规定 $h_n=\\dfrac{1}{\\sqrt n}$ 、 $h_n=\\dfrac{2}{\\sqrt n}$ ,这就说明第一个模型的窗宽小于第二个模型( $n$ 相同时,第二个模型的窗宽总是大于第一个模型的)。
下面就讨论窗宽是如何影响估计效果的。
二、不同的窗宽对密度函数的估计效果产生的作用
设 $h_n=\\dfrac{h_1}{\\sqrt n}$ ,那么通过改变参数 $h_1$ 就可获得窗宽不同的模型( $n$ 相同时这些模型有着不同的窗宽)。当然了,窗宽序列的获取当然不是只有这一种途径,一般原则是当 $n$ 越大时 $h_n$ 越小。[1]中首先讨论的是有限样本的情况,使用高斯窗函数,得到的结果是:在样本数有限的情况下,太大的窗宽会是高方差的,欠拟合;太小的窗宽会是低方差的,过拟合;窗宽较大时,平滑程度较大。理论上的证明这里就不赘述了(其实我也没细看。。。),;收敛性也不细说了,在 $p_n(\\textbf x)$ 收敛到一个值后,这个值是 $p(\\textbf x)$ 被窗函数平滑的结果,$p_n(\\textbf x)$ 的期望是 $p(\\textbf x)$ 的平滑(卷积)。
[1]里继续用高斯窗函数的情况下讨论样本数无穷时去估计概率密度(有单模的高斯密度,也有多模的混合密度),得到的结果是:当样本数无穷时,不管窗宽多大,最后总能准确地估计出真实概率密度。
下面这张图就展示了真实密度是多模的情况下,取不同窗宽(每一列代表一个模型,从左到右窗宽依次减小)时,样本数从有限到无限(从上到下样本数依次增大)的估计效果,可以对照上面两个结论来看这张图。能够估计多模的密度,这正是非参数方法可以做到而参数方法所做不到的。

图片来源:[1]
三、Parzen窗估计之后的分类器
其实我们搞了半天,又是参数方法又是非参数方法的,最后的目的无非都是为了得到一个泛化性能好的分类器。对于Parzen窗估计来说,窗函数决定了决策区域。
上面的讨论已经明确指出来Parzen窗估计的优缺点:优点是通用性,无需假设数据分布,即使真实密度函数是多模的,也可以使用;缺点就是如果准确估计窗函数,需要大量的样本,比参数方法所需要的样本要多得多,这带来很大的存储和计算开销。目前,还没有有效的方法可以降低在满足准确估计的情况下所需要的样本数。
(三)k近邻估计
k近邻估计通过改变包含相同样本数所需要的区域大小来获得估计序列。假设给定 $n$ 时,近邻个数 $k_n$ 是确定的(例如,令 $k_n=k_1\\sqrt n$ ) ,从而在这时需要的 $V_n$ 是刚好可以“包进” $k_n$ 个样本的大小,然后便可利用估计序列 $p_n(\\textbf x)=\\frac{k_n/n}{V_n}$ 来估计概率密度函数。我们希望的是当 $n$ 趋向无穷时,$k_n$ 也趋向无穷;而 $k_n$ 的增长又尽可能慢,使 $V_n$ 能逐渐趋向于0。
k近邻估计中,估计效果取决于近邻数。
下图是我写程序画的[1]上的图(注意两张图的纵轴标度不一样),表明了一维情况下,有限个样本点的k近邻估计取不同的近邻数时的估计结果(图中的样本数为8)。画的是 $n=8$ 时(刚好等于样本数)的情况,这里直接取的 $k_n=3$ 和 $k_n=5$(一般来说 $k_n$ 应该是 $n$ 的函数,这里为了简单起见直接取了两个不同的值) ,由于是一维,所以对于任一一点 $x$ ,其局部区域 $V_n$ 就是刚好包进 $k_n$ 个样本时这 $k_n$ 个样本两两间距的最大值除以2。例如对于 $k_n=3$ 的情形,考虑特征空间中的点 $x=5$ ,由于需要包进3个样本,所以这个点的 $V_n$ 是左起第二个样本到第四个样本之间,$V_n$ 大小为第二个样本和第四个样本的距离的一半。
可见当近邻数较大时,平滑程度较大,这和Parzen窗估计中的窗宽较大时的效果是类似的。


与Parzen窗估计相同的是,当样本量无穷时,k近邻估计可以准确地估计出真实概率密度,这里就不贴图啦。
(四)k近邻分类器(k-nearest neighbor,kNN)
将上述的k近邻估计用于分类,所以需要根据密度的估计值求取后验概率的估计值。根据贝叶斯公式,后验等于似然乘先验除以证据,
$$P_n(\\omega_i|\\textbf x)=\\frac{p_n(\\textbf x|\\omega_i)P_n(\\omega_i)}{\\sum_{j=1}^cp_n(\\textbf x|\\omega_j)P_n(\\omega_j)}=\\frac{p_n(\\textbf x,\\omega_i)}{\\sum_{j=1}^cp_n(\\textbf x,\\omega_j)}$$
因为 $p_n(\\textbf x,\\omega_i)=\\frac{k_i/n}{V}$ ,如果再记 $k=\\sum_{j=1}^ck_j$ ,那么有
$$P_n(\\omega_i|\\textbf x)=\\dfrac{k_i}{k}$$
由此引出了k近邻分类器。
k近邻分类器直接估计后验概率,因此属于判别式模型,是一种没有显式训练过程的“懒惰学习(lazy learning)”算法,它既可以用来分类也可以用来回归:给定一个测试样本,从训练样本里找出与之最相似的k个(相似度可以用欧氏距离、余弦相似度等)训练样本作为近邻,然后投票。可以是直接投票,也可以用相似度作为权重因子来加权投票。分类的话就是近邻里出现次数最多的类别作为该测试样本的类别,或者用相似度加权;回归的话就是近邻的值取平均值,或者用相似度加权。
可以看出该算法的开销非常大。有一些数据结构用来对近邻的计算过程加速,如kd树(k-d tree)等,可以参考 [2] 以及数据结构相关书籍。
用不到10行Python就可以实现一个最简单的kNN(距离计算要用开源包,所以这个说法略标题党哈:) )在MNIST数据集上做了点小实验(数据没有做预处理,就是原始的784维特征,0到255的像素值),结果如下表:

可以看出在这个数据集上,余弦相似度比欧氏距离效果稍好但没好太多;而且当近邻个数太少时不能为判别提供太多信息,而近邻个数太多时则又引入了噪声而不利于判别。
此外,一个比较有意思的结论是:最近邻分类器(k=1)的错误率不超过贝叶斯最优分类器的两倍;当k趋于无穷时k近邻分类器成为最优分类器。
再强调一下,贝叶斯分类器是最优分类器的前提是密度函数可以被准确地估计。实际上这很难做到。
附上sklearn库中对近邻算法的介绍:1.6. Nearest Neighbors
参考资料:
[1] 《模式分类》及slides
[2] 《统计学习方法》
以上是关于机器学习 —— 基础整理:非参数方法——Parzen窗估计k近邻估计;k近邻分类器的主要内容,如果未能解决你的问题,请参考以下文章