GPU入门
Posted 胡韬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPU入门相关的知识,希望对你有一定的参考价值。
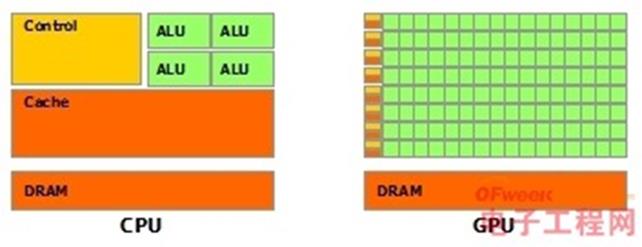
CPU和GPU区别,CPU像是一头牛,GPU像是一万只小鸡。
关于CPU设计理念:基于低延时性设计
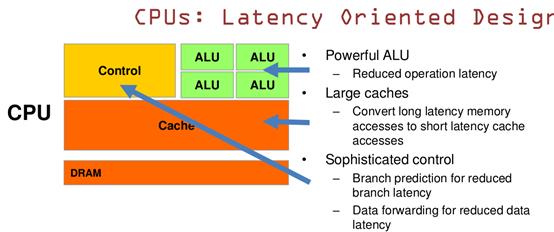
■ ALU:CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算。
■ 当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期。
■ CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方).
■ Cache:大的缓存也可以降低延时。保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。
■ Control:复杂的逻辑控制单元。
■ 当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
■ 数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。这些动作需要很多的对比电路单元和转发电路单元。
结论:CPU运算速度更快,指令周期短,即便是双精度的浮点数乘法也只需要1~3个时钟周期。
GPU的设计理念:基于吞吐量。
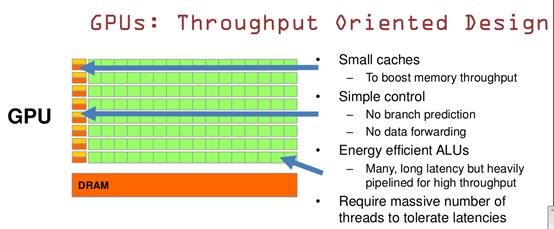
ALU,Cache:GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
Control:控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多的thread. 为了平衡内存延时的问题,我们可以中充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的Threads.通常来看GPU ALU会有非常重的pipeline就是因为这样。
结论:GPU可以达到很好的吞吐量。
对比:CPU擅长逻辑控制,串行的运算。和通用类型数据运算不同,GPU擅长的是大规模并发计算,这也正是密码破解等所需要的。所以GPU除了图像处理,也越来越多的参与到计算当中来。
CPU和GPU区别,CPU像是一头牛,GPU像是一万只小鸡。
关于CPU设计理念:基于低延时性设计
■ ALU:CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算。
■ 当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期。
■ CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方).
■ Cache:大的缓存也可以降低延时。保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。
■ Control:复杂的逻辑控制单元。
■ 当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
■ 数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。这些动作需要很多的对比电路单元和转发电路单元。
结论:CPU运算速度更快,指令周期短,即便是双精度的浮点数乘法也只需要1~3个时钟周期。
GPU的设计理念:基于吞吐量。
ALU,Cache:GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
Control:控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多的thread. 为了平衡内存延时的问题,我们可以中充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的Threads.通常来看GPU ALU会有非常重的pipeline就是因为这样。
结论:GPU可以达到很好的吞吐量。
对比:CPU擅长逻辑控制,串行的运算。和通用类型数据运算不同,GPU擅长的是大规模并发计算,这也正是密码破解等所需要的。所以GPU除了图像处理,也越来越多的参与到计算当中来。
以上是关于GPU入门的主要内容,如果未能解决你的问题,请参考以下文章