Hive HQL学习
Posted 一夜飘零
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive HQL学习相关的知识,希望对你有一定的参考价值。
HQL学习

1.hive的数据类型

2.hive_DDL
2.1创建、删除、修改、使用数据库



 Default数据库,默认的,优先级相对于其他数据库是最高的
Default数据库,默认的,优先级相对于其他数据库是最高的

2.2重点:创建表_内部表_外部表
hive通过sql来分析hdfs上结构化的数据,将数据文件映射为表的结构
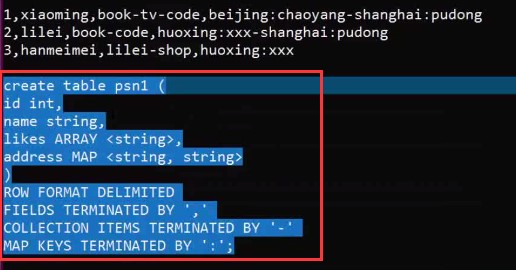
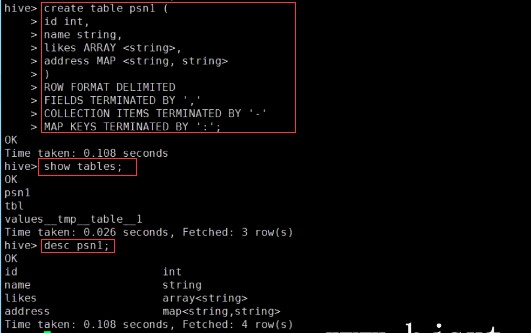
– create table person(– id int,– name string,– age int,– likes array<string>,– address map<string,string>–)– row format delimited– FIELDS TERMINATED BY \',\'– COLLECTION ITEMS TERMINATED BY \'-\'– MAP KEYS TERMINATED BY \':\'– lines terminated by \'\\n\';–Select address[‘city’] from person where name=‘zs’
第一点注意:ROW FORMAT row_format


序列化和反序列化要对数据文件进行拆分映射到表里面,那么ROW FORMAT 加上 DELIMITED 就是指定序列化和反序列化的规则,通俗讲就是如何进行数据的拆分,重写的规则就是ROW FORMAT 加上 SERDE
比如:
FIELDS TERMINATED BY \',\' 指定一行数据的字段按照,分割
COLLECTION ITEMS TERMINATED BY \'-\' 如果是集合,按照-分割集合中的每个元素
MAP KEYS TERMINATED BY \':\' map类型的按照:分割
LINES TERMINATED BY \'\\N\' 行之间按照换行符分割,这也是默认的
第二点注意:STORED AS file_format


它指定文件在hdfs上以什么格式进行存储,默认是TEXTFILE
其他几种方式在存储时可以指定压缩,使用压缩(好处:减少磁盘占用空间,坏处:写的时候进行压缩,读的时候进行解压缩,都需要占用cpu资源,效率会打折扣)
第三点注意:定义字段时的特殊类型(array,map,struct)

第四点注意:想想插入测试数据(上面的那三条)会用insert语句么?
也可以,但是不会那样做,因为insert底层转化为MR
所以这里采用另一种方式:

LOCAL:如果数据存在本地需要加LOCAL;如果存在hdfs上就不用了
如果是本地,那麽这种方式先上传到hdfs中一个临时文件,再将临时文件移动到hive中对应的数据存放目录下
如果是将hdfs中的数据加载进表,那么这种方式实际是讲hdfs中的数据文件移动到了hive的dir下(/user/hive/warehouse)

第五点注意:外部表
创建外部表时,需要指定数据存放的位置



创建外部表,会在hdfs中LOCATION指定的路径下创建和表名对应的目录
(而创建内部表,会在hive-site.xml中配置的dir下创建对应的目录)




删除内部表和外部表的区别?
1.删除内部表,会元数据信息联同数据一块进行删除(内部表数据的维护交由hive本身进行管理)
2.删除外部表,只会删除元数据信息,但是在hdfs上存储的数据还在(外部表则不是)
truncate table 表名

第六点注意:将子查询的结果存储到新表中



第一步:创建了表;第二部:将查出的结果插入到表中(注意这种方式在创建表时不能指定列,否则就会报错)
6.1这种方式什么时候会用?
创建中间表的时候,如果需要一些数据可以通过这种方式来做。
6.2这种方式和 create table psn4 like psn3 的区别?

3.hive_分区
1.分区表什么时候会用?
举例一:比如有一张人员表,分析一些日志数据,可以按照天进行分区,那么每一天的数据会存放在对应的分区中(会存储在每一天的目录下面)
举例二:有一个很大的表,里面存放了很多的日志,这时候可以采用分区,进行标识,分块管理
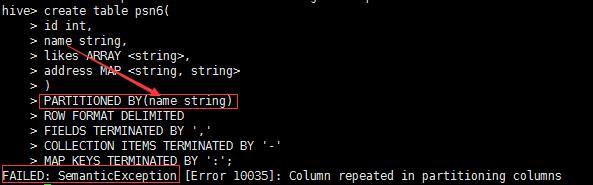
注意:分区的字段一定不能在表的列名里面
2.分区表的创建,添加数据,查看对应分区下的数据,修改分区、删除分区
创建带有分区的表psn5

创建了分区,进行插入数据,就需要指定分区字段,否则就会报错



查看表,发现有两个分区(boy, girl)

在hdfs中查看,发现目录下有两个目录对应两个分区

查看指定分区下的数据
select * from psn5 where sex = \'boy\'
添加分区
ALTER TABLE psn5 ADD PARTITION (sex = \'weizhi\') //在一个表中添加一个分区
ALTER TABLE psn5 DROP PARTITION (sex = \'weizhi\') //同时删除对应分区中的数据
---分区_指定两个分区字段create table psn5(id int,name string,likes ARRAY <string>,address MAP <string, string>)PARTITIONED BY(sex string,age int)ROW FORMAT DELIMITEDFIELDS TERMINATED BY \',\'COLLECTION ITEMS TERMINATED BY \'-\'MAP KEYS TERMINATED BY \':\';---创建分区后,再进行插入数据,就需要指定分区字段load data local inpath \'/root/data\' into table psn5 partition (sex=\'boy\',age=1);
删除分区的时候,一定要注意(分区下可能还有分区)

4.hive_DML
重点掌握1:load data方式,2:from insert ...插入数据
1.创建psn7,将数据从psn1中查出来,插入到psn7中
create table psn7 like psn1;from psn1insert into table psn7 select id, name, likes, address

思考一:hive其实就是写sql来分析hdfs上的数据,那么问题来了,以上这种方式做什么用?
比如我们要分析一个WordCount,那么结果只是显示在控制台么,显然不是,我们要将hive sql运行的结果存储到另一张表中
为什么要将from放在上面呢?
我们将对同一张表分析的多个指标写到结果表中,就不用写多个sql了,要不还需要join

以上是关于Hive HQL学习的主要内容,如果未能解决你的问题,请参考以下文章