Python基础之day2
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础之day2相关的知识,希望对你有一定的参考价值。
Python介绍
一、python对比其他语言
C,python,java,C# C语言:代码编译得到机器码,机器码在处理上直接执行,每一条指令控制CPU工作 其他语言:代码编译得到字节码,虚拟机执行字节码并转换成机器码再在处理器上执行 python和C的对比,python是由C开发而来 对于使用:python的类库齐全并且使用简洁,如果要实现同样的功能,Python用10行代码可以解决,C可能就需要100行甚至更多 对于速度:Python的运行速度相较于C比较慢 python对比Java,C#等 对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持 对于速度:Python在速度上可能稍显逊色 所以,python和其他语言没有本质区别,其他区别在于:擅长领域,人才丰富,先入为主。
二、python的种类
- Cpython:Python的官方版本,使用C语言实现,使用最广,Cpython会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。
- Jython:Python的java实现,jython会将Python代码动态编译成java字节码,然后再JVM上运行
- IronPython:Python的C#实现,IronPython将Python编译成C#字节码,然后在CLR上运行
- PyPy:Python实现的Python,将Python的字节码编译成机器码(执行快)
- ...
三、python入门
1.python内部执行过程
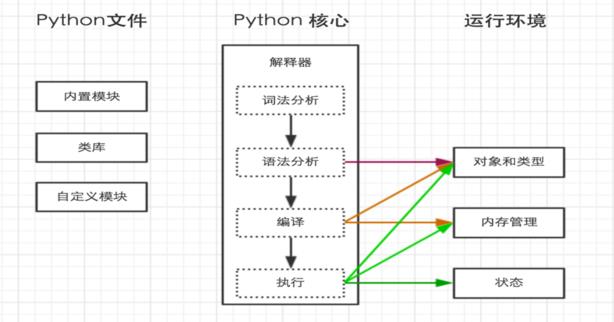
2.解释器
python文件必须在头部明确指明由python解释器来执行。
#!/usr/bin/env python print("hello,world")
3.内容编码
ascii:美国标准信息交换码(8位) unicode:万国码(至少16位),可以表示任何国家的语言 utf-8: UTF-8是一种针对Unicode的可变长度字符编 Python2.x在执行.py文件时默认使用的是ascii编码,如果不在头部指定utf-8编码,代码执行是可能会因为编码问题而报错。Python3.x里面默认使用utf-8读代码,可以忽略编码问题。
编码解码过程:
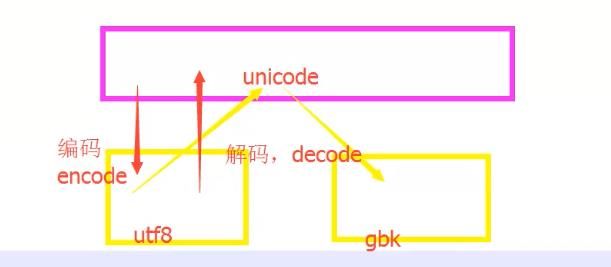
4.注释
单行注释如下:
#这一行被注释
多行注释用三个单引号(‘‘‘ ‘‘‘)或双引号(""" """)表示,如下:
‘‘‘ 多行注释 多行注释 ‘‘‘""" 多行注释 多行注释 """
5.执行脚本传入参数
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
示例:创建一个index.py文件,内容如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys print(sys.argv)
执行:
D:\python>python index.py 0000 [‘index.py‘, ‘0000‘]
argv方法会把文件路径和传入参数组成一个列表
数据类型常用方法
整数常用方法:
1.__abs__:取绝对值,n=-9,n.__abs__()或者abs(n)可以获得 >>> n = -9 >>> n.__abs__() 9 >>> abs(n) 9 2.__add__:加法,用法x.__add__(y)<==>x+y >>> n = 9 >>> n.__add__(9) 18 >>> n + 9 18 3.int():创建一个整数(括号内可以指明创建的是几进制的),比如i=int(‘10‘,base=2),相当于创建一个整数2 >>> int(‘10‘,base=2) 2 >>> int(‘100‘,base=2) 4 >>> int(‘100‘,base=8) 64 4.__and__:位运算x.__and__(y)<==>x&y >>> n = 5 >>> n.__and__(6) 4 >>> 5&6 4 5.__cmp__:比较两个数大小,返回0(相等),1(大于),-1(小于),用法x.__cmp__(y)<==>cmp(x,y) >>> n = 5 >>> n.__cmp__(6) -1 >>> cmp(5,6) -1 >>> cmp(6,6) 0 >>> cmp(6,7) -1 6.__coerce__:强制生成一个元祖,用法x.__coerce__(y)<==>coerce(x,y) >>> n = 10 >>> n.__coerce__(20) (10, 20) >>> coerce(10,20) (10, 20) 7.__divmod__:相除得到的商和余数并组成一个元组,用法x.__divmod__(y)<==>divmod(x,y) >>> divmod(99,10) (9, 9) >>> n = 99 >>> n.__divmod__(10) (9, 9) 8.__div__:取商,x.__div__(y)<==>divmod(x,y) >>> n = 20 >>> n.__div__(5) 4 >>> 20/5 4 9.__float__:把整数转成浮点数 >>> n = 20 >>> n.__float__() 20.0 >>> float(20) 20.0 10.__floordiv__:取商,地板除 >>> n = 5 >>> n.__floordiv__(2) 2 >>> 5//2 2 11.__hex__:将数字转换成16进制,用法x.__hex__()<==>hex(x) >>> n = 20 >>> n.__hex__() ‘0x14‘ 12.__oct__:八进制,用法同上 >>> n = 20 >>> n.__oct__() ‘024‘ >>> oct(20) ‘024‘ 13.__mod__:取模(余数),x.__mod__(y)<==>x%y >>> n =11 >>> n.__mod__(2) 1 >>> 11%2 1 14.__neg__:正负数互转(正转负,负转正),用法x.__neg__() >>> n =-5 >>> n.__neg__() 5
字符串常用方法:
1.capitalize方法,把字符串首字母变为大写: >>> name = ‘akon‘ >>> name.capitalize() ‘Akon‘ 2.center方法,把字符串放中间(两边可填充其他字符): >>> name = ‘akon‘ >>> name.center(20,‘=‘) ‘========akon========‘ 3.count方法,寻找子序列在字符串中出现个数(可指定起始结束位置): >>> name = ‘akonakonakonakon‘ >>> name.count(‘k‘) 4 >>> name.count(‘a‘,0,10) 3 >>> name = ‘akonakonakonakon‘ >>> name.count(‘a‘,5,10) 1 4.编码与解码(Python3.5里只能编码不能解码) decode解码: >>> str1 = ‘有‘ >>> str1 ‘\xe6\x9c\x89‘ encode编码: >>> str1 = ‘有‘ >>> str1 ‘\xe6\x9c\x89‘ >>> str2 = str1.decode(‘utf-8‘) >>> str2 u‘\u6709‘ >>> str2.encode(‘gbk‘) ‘\xd3\xd0‘ 5.expandtabs,将tab键转换成空格,默认情况下1个tab等于8个空格,用法如下: >>> name=‘ akon‘ >>> name.expandtabs() ‘ akon‘ >>> name.expandtabs(4) ‘ akon‘ 6.find方法,可以查单个字符在字符串中的位置[索引](从左到右,rfind为从右到左),如果没找到则返回-1,用法如下: index(rindex从右到左)方法的用法跟find一样,只不过用index方法如果找不到会报错 find(rfind): >>> name = ‘akonbkonakon‘ >>> name.find(‘n‘) 3 >>> name.find(‘c‘) -1 >>> name.rfind(‘n‘) 11 index(rindex): >>> name = ‘akonbkonakon‘ >>> name.index(‘o‘) 2 >>> name.rindex(‘o‘) 10 >>> name.index(‘c‘) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: substring not found >>> 7.字符串的格式化 >>> name = ‘I am {0},age{1}‘ >>> name.format(‘akon‘,‘26‘) ‘I am akon,age26‘ >>> name = ‘I am {b},age {a}‘ >>> name.format(a=16,b=‘akon‘) ‘I am akon,age 16‘ 列表传参数: >>> name = ‘I am {0},age{1}‘ >>> list1 = [‘akon‘,26] >>> name.format(*list1) ‘I am akon,age26‘ 字典传参数: >>> name = ‘I am {a},age {b}‘ >>> dict1 = {‘a‘:‘akon‘,‘b‘:27} >>> name.format(**dict1) ‘I am akon,age 27‘ 8.字符串首字母如果为大写则为标题,用title方法可以把字符串变成标题 >>> name = ‘akon hello‘ >>> name2 = name.title() >>> name2 ‘Akon Hello‘ >>> name2.istitle() True 9.ljust和rjust(跟center用法相同)填充数据并把字符串放到左边和右边 10.lower(casefold)/upper方法把字符串全部变成小写/大写 >>> name = ‘Akon Hello‘ >>> name.upper() ‘AKON HELLO‘ >>> name.lower() ‘akon hello‘ 11.swapcase大小写对换 >>> name = ‘Akon Hello‘ >>> name.swapcase() ‘aKON hELLO‘ >>> 12.partition把字符串分割成3部分(以括号内字符串为分割点) >>> name = ‘AkonIsGood‘ >>> name.partition(‘Is‘) (‘Akon‘, ‘Is‘, ‘Good‘) >>> 13.replace方法替换(会找到所有符合的字符替换) >>> name=‘abcdefgabcdabc‘ >>> name.replace(‘cde‘,‘CCC‘) ‘abCCCfgabcdabc‘ >>> name.replace(‘c‘,‘KKK‘) ‘abKKKdefgabKKKdabKKK‘ >>> name.replace(‘abc‘,‘a‘,1) #指定转换个数 ‘adefgabcdabc‘ 14.contains包含 >>> name = ‘abcdefg‘ >>> name.__contains__(‘ab‘) True >>> ‘ab‘ in name True 15.format格式化 >>> name = ‘abc{0}‘ >>> name.format(‘abc‘) ‘abcabc‘ 16.endswith判断字符串(或子序列)是否以指定字符结尾 >>> n = ‘dfsdfsdfsd‘ >>> n.endswith(‘d‘) True >>> n.endswith(‘d‘,0,5) False 17.join把列表拼接成字符串 >>> li = [‘you‘,‘are‘,‘fool‘] >>> ‘ ‘.join(li) ‘you are fool‘ 18.split以指定字符分割字符串,并组成一个列表 >>> name=‘abcdefgabcdabc‘ >>> name.split(‘b‘) [‘a‘, ‘cdefga‘, ‘cda‘, ‘c‘] 19.maketrans对应表,与translate一起用
列表常用方法:
1.append往列表尾部添加一个元素 >>> name = [‘abc‘,‘akon‘,‘ak‘,] >>> name.append(‘cloris‘) >>> name [‘abc‘, ‘akon‘, ‘ak‘, ‘cloris‘] 2.clear清空列表 >>> name = [‘abc‘,‘akon‘,‘ak‘,] >>> name.clear() >>> name [] 3.count查看元素出现的次数 >>> name = [‘abc‘,‘akon‘,‘ak‘,] >>> name.count(‘ak‘) 1 4.extend扩展,把列表拼接 >>> name = [‘abc‘,‘akon‘,‘ak‘,] >>> name2 = [‘cloris‘] >>> name.extend(name2) >>> name [‘abc‘, ‘akon‘, ‘ak‘, ‘cloris‘] 5.index查看索引 >>> name = [‘abc‘,‘akon‘,‘ak‘,] >>> name.index(‘akon‘) 1 6.pop删除指定元素(索引)并返回这个元素,默认删除最后一个 >>> name = [‘abc‘,‘akon‘,‘ak‘,] >>> name.pop(1) ‘akon‘ >>> name [‘abc‘, ‘ak‘] 7.remove删除指定元素 >>> name = [‘abc‘,‘akon‘,‘ak‘,] >>> name.remove(‘abc‘) >>> name [‘akon‘, ‘ak‘] 8.reverse反转列表 >>> name = [‘abc‘, ‘akon‘, ‘ak‘, ‘cloris‘] >>> name.reverse() >>> name [‘cloris‘, ‘ak‘, ‘akon‘, ‘abc‘] 9.sort排序 name = [‘abc‘, ‘akon‘, ‘ak‘, ‘cloris‘] >>> name [‘abc‘, ‘ak‘, ‘akon‘, ‘cloris‘]
元组
1.count方法,计算指定元素的个数 >>> t1 = (1,2,1,2,) >>> t1.count(1) 2 2.index方法,获取索引 >>> t1 = (1,2,1,2,) >>> t1.index(2) 1
字典
字典的创建 >>> dic = dict(k1=‘v1‘,k2=‘v2‘) >>> dic {‘k2‘: ‘v2‘, ‘k1‘: ‘v1‘} >>> dic2 = {‘k3‘:‘v3‘,‘k4‘:‘v4‘} >>> dic2 {‘k3‘: ‘v3‘, ‘k4‘: ‘v4‘} 字典常用方法 1.fromkeys方法 >>> dic = dict(k1=‘v1‘,k2=‘v2‘) >>> dic2 = dic.fromkeys([‘k1‘,‘k2‘],‘v10‘) >>> dic2 {‘k2‘: ‘v10‘, ‘k1‘: ‘v10‘} 2.get方法,获取指定key的值,如果key不存在,默认返回一个空,可以指定返回什么信息 >>> dic = dict(k1=‘v1‘,k2=‘v2‘) >>> print(dic.get(‘k1‘)) v1 >>> print(dic.get(‘k3‘)) None >>> print(dic.get(‘k3‘,‘nothing‘)) nothing 3.items,keys,values方法 >>> dic2 = {‘k3‘:‘v3‘,‘k4‘:‘v4‘} >>> dic2.items() [(‘k3‘, ‘v3‘), (‘k4‘, ‘v4‘)] >>> dic2.keys() [‘k3‘, ‘k4‘] >>> dic2.values() [‘v3‘, ‘v4‘] 4.pop删除指定元素并返回元素的值 >>> dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘} >>> dic.pop(‘k2‘) ‘v2‘ >>> dic {‘k3‘: ‘v3‘, ‘k1‘: ‘v1‘} 5.popitem()方法,随机删除一个元素,并返回 >>> dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘} >>> dic.popitem() (‘k3‘, ‘v3‘) >>> dic {‘k2‘: ‘v2‘, ‘k1‘: ‘v1‘} 6.update方法,遍历字典key,如果存在则更新对应的value,如果不存在则创建并添加到字典中 >>> dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘} >>> dic.update({‘k3‘:‘v33‘}) >>> dic {‘k3‘: ‘v33‘, ‘k2‘: ‘v2‘, ‘k1‘: ‘v1‘} >>> dic.update({‘k4‘:‘v4‘}) >>> dic {‘k3‘: ‘v33‘, ‘k2‘: ‘v2‘, ‘k1‘: ‘v1‘, ‘k4‘: ‘v4‘} 7.setdefault方法,相当于往字典添加一个元素 >>> dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘} >>> dic.setdefault(‘k4‘,‘v4‘) ‘v4‘ >>> dic {‘k3‘: ‘v3‘, ‘k2‘: ‘v2‘, ‘k1‘: ‘v1‘, ‘k4‘: ‘v4‘}
以上是关于Python基础之day2的主要内容,如果未能解决你的问题,请参考以下文章