平台调优方案
Posted 流浪在伯纳乌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了平台调优方案相关的知识,希望对你有一定的参考价值。
存在的问题:
1 启动hive后等待资源的时间

2 根据输入文件的大小,map task 的个数是变化的,reduce始终是30,如何优化map的个数,map个数与reduce个数之间的关系比例?
Map 执行到百分之多少的时候,reduce可以进行?有个参数比例设置?
调整map和reduce 任务执行的内存和CPU虚拟内核数,将之前的2G和2核调整为4G和4核
3 insert中表与表之间的join,设计mapreduce的建议将小表放在前面。
where的条件写在join里面,使得减少join的数量
如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,实际测试过程中,执行时间能提升50%
4 包含group by 的是否要防止数据倾斜?set hive.groupby.skewindata = true
单个SQL所起的JOB个数尽量控制在5个以下
5 集群1点到4点多个复杂的任务在抢占资源,最高是运行85个程序,平均40多个,可以适当调整时间
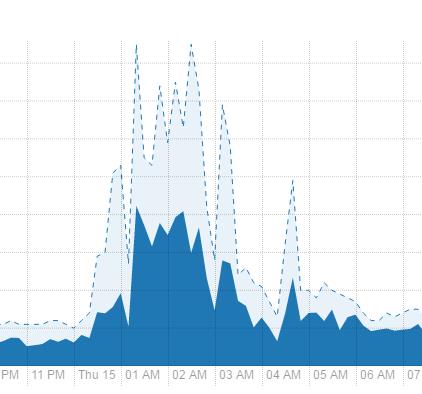
6 优化执行时间超过一个小时的程序:
从odsh到ods层的程序

7 删除hdfs 目录下包含.hive-staging的文件

9 相关可能的调优参数
Yarn 资源分配性能调优
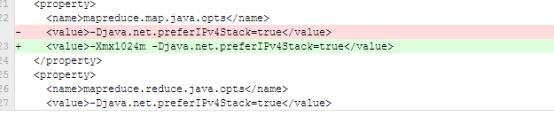
mapreduce.map.Java.opts –Xmx1024
mapreduce.reduce.java.opts=-Xms1024m –Xmx1024m;
说明:这两个参主要是为需要运行JVM程序(java、Scala等)准备的,通过这两个设置可以向JVM中传递参数的,与内存有关的是,-Xmx,-Xms等选项。此数值大小,应该在AM中的map.mb和reduce.mb之间。
以上是关于平台调优方案的主要内容,如果未能解决你的问题,请参考以下文章