c# SQL登陆问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c# SQL登陆问题相关的知识,希望对你有一定的参考价值。
本地的一个SQL,用Navicat 输入账户密码 既可轻松登陆
但用c# 编写代码如下
SqlConnection con = new SqlConnection("SERVER=(local),3306;DATABASE=lol;PWD=123456;UID=gobe;");
con.open();
运行到con.open(); 报错
+ 已引发:“内部连接致命错误。”(System.InvalidOperationException) 异常消息 = "内部连接致命错误。", 异常类型 = "System.InvalidOperationException", 异常 WinRT 数据 = ""
求解~
现已查明内部连接致命错误 是打开了NAVICAT造成的,关闭后错误变成了
+ 已引发:“已成功与服务器建立连接,但是在登录前的握手期间发生错误。 (provider: TCP Provider, error: 0 - 您的主机中的软件中止了一个已建立的连接。)”(System.Data.SqlClient.SqlException) 异常消息 = "已成功与服务器建立连接,但是在登录前的握手期间发生错误。 (provider: TCP Provider, error: 0 - 您的主机中的软件中止了一个已建立的连接。)", 异常类型 = "System.Data.SqlClient.SqlException", 异常 WinRT 数据 = ""
SERVER=(local),3306;DATABASE=lol;PWD=123456;UID=gobe;
这一串,“,3306”是什么意思,没见过这个写法,试试删掉
还有,确定lol的登录名是gobe,密码是123456吗追问
3306 是端口的写法,同时我确定用户密码都没错
追答好吧,我还以为是SQLServer数据库。。。
参考技术A 首先引入mysql.Data.dll。string conn = "Data Source=127.0.0.1;User ID=root;Password=123;DataBase=lol;Charset=gb2312;";
MySqlConnection con = new MySqlConnection(conn);
con.Open();追问
哥们你这是哪儿抄的啊
追答你用的mysql吧。是抄的。学数据库 博客园不过试试可以用不。没连过mysql你要导入插件。不像链接sqlserver 你是写java的吧。
public partial class Form2 : Form
private DataSet dsall;
//private static String mysqlcon = "Data Source=MySQL;database=onepc;Password=;User ID=root;Location=192.168.1.168;charset=utf8";
private static String mysqlcon = "database=onepc;Password=;User ID=root;server=192.168.1.168";//Data Source=MySQL;;charset=utf8";
private MySqlConnection conn;
private MySqlDataAdapter mdap;
public Form2()
InitializeComponent();
博客园上抄的
就是这了!分给你!谢谢啦
本回答被提问者采纳hive sql 经典题目 连续登陆|间隔连续登陆|行列转换|累加|topN | 炸裂
连续问题 : rank + date_diff
间隔连续问题: 计算前一个数据量, 根据当前数据跟前一行数据的diff, 计算是否属于同一个组(是否连续flag), 累加flag得到flag_sum
根据uid, flag_sum进行分组,得到用户间隔连续的登陆次数
- 累加问题: 编写sql实现每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数
样本数据:
# 样本数据
userid,month,visits
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,1
# 创建hive表
spark.read.option("header", true).csv("/user/vc/users/vc/test/demo_4.csv").write.saveAsTable("temp.test_demo_4")
# 使用窗口函数over
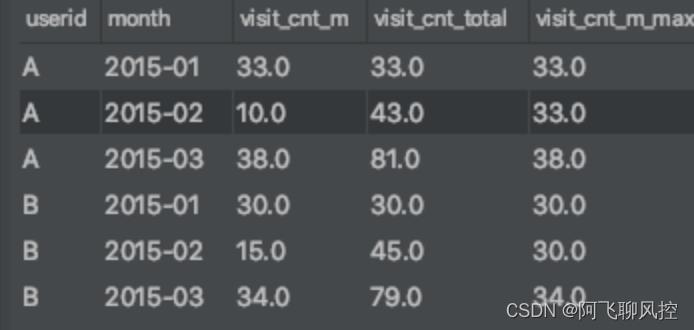
select userid, month,visit_cnt_m,
sum(visit_cnt_m) over(partition by userid order by month) as visit_cnt_total,
max(visit_cnt_m) over(partition by userid order by month) as visit_cnt_m_max
from
(select userid, month, sum(visits) as visit_cnt_m from temp.test_demo_4 group by userid, month ) as t1
- 连续登陆问题:编写连续7天登录的总人数
样本数据:
uid dt login_status(1登录成功,0异常)
1 2019-07-11 1
1 2019-07-12 1
1 2019-07-13 1
1 2019-07-14 1
1 2019-07-15 1
1 2019-07-16 1
1 2019-07-17 1
1 2019-07-18 1
2 2019-07-11 1
2 2019-07-12 1
2 2019-07-13 0
2 2019-07-14 1
2 2019-07-15 1
2 2019-07-16 0
2 2019-07-17 1
2 2019-07-18 0
3 2019-07-11 1
3 2019-07-12 1
3 2019-07-13 1
3 2019-07-14 1
3 2019-07-15 1
3 2019-07-16 1
3 2019-07-17 1
3 2019-07-18 1
代码:
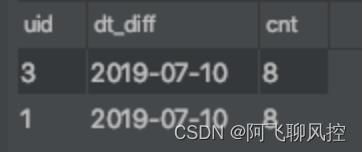
select uid, dt_diff, count(1) as cnt from
(select uid, dt, rnk, date_sub(dt, rnk) as dt_diff from
(select uid, dt, row_number() over(partition by uid order by dt) as rnk
from temp.test_demo_5 where login_status ='1'
group by uid, dt ) as t1 ) as t2
group by uid, dt_diff
having cnt>=7
- 间隔连续问题
当同一个用户id的本次开始时间跟上一次浏览的结束时间的间隔大于10分钟时,需要分到下一组
如果小于10分钟,就将2条数据合并
# 数据准备:
用户编号,开始时间,结束时间,下行流量
1,2020-2-18 14:20,2020-2-18 14:46,20
1,2020-2-18 14:47,2020-2-18 15:20,30
1,2020-2-18 15:37,2020-2-18 16:05,40
1,2020-2-18 16:06,2020-2-18 17:20,50
1,2020-2-18 17:21,2020-2-18 18:03,60
2,2020-2-18 14:18,2020-2-18 15:01,20
2,2020-2-18 15:20,2020-2-18 15:30,30
2,2020-2-18 16:01,2020-2-18 16:40,40
2,2020-2-18 16:44,2020-2-18 17:40,50
3,2020-2-18 14:39,2020-2-18 15:35,20
3,2020-2-18 15:36,2020-2-18 15:24,30
# 第一步:计算上一次的结束时间:
select *,
lag(end_time,1, start_time) over(partition by id order by start_time) as last_end_time
from temp.demo_2_table
# 第二步:将字符串转化为标准时间格式
select t.id,
to_timestamp(t.start_time) as st_time,
to_timestamp(t.end_time) as end_time,
to_timestamp(t.last_end_time) as last_end_time,
t.flow
from
(select *,
lag(end_time,1, start_time) over(partition by id order by start_time) as last_end_time
from temp.demo_2_table ) as t
# 第三步:用本次开始时间-上一次的结束时间,计算浏览时间间隔
注意:需要将标准时间格式转化为时间戳
select id, st_time, end_time, last_end_time, flow,
(unix_timestamp(st_time)- unix_timestamp(last_end_time))/60 as sub_time
from
(select t.id,
to_timestamp(t.start_time) as st_time,
to_timestamp(t.end_time) as end_time,
to_timestamp(t.last_end_time) as last_end_time,
t.flow
from
(select *,
lag(end_time,1, start_time) over(partition by id order by start_time) as last_end_time
from temp.demo_2_table ) as t ) as t2
# 第四步:如果时间间隔>=10s,则flag =1
select
id, st_time, end_time, last_end_time, sub_time, flow,
case when sub_time>=10 then 1 else 0 end as flag
from
(select id, st_time, end_time, last_end_time, flow, (unix_timestamp(st_time)- unix_timestamp(last_end_time))/60 as sub_time
from
(select t.id,
to_timestamp(t.start_time) as st_time,
to_timestamp(t.end_time) as end_time,
to_timestamp(t.last_end_time) as last_end_time,
t.flow
from
(select *,
lag(end_time,1, start_time) over(partition by id order by start_time) as last_end_time
from temp.demo_2_table ) as t ) as t2 ) as t3
# 第五步:使用开窗函数对flag进行累加,是为了对小于10分钟的数据和大于十分钟的数据进行分组
select id, st_time, end_time, last_end_time, sub_time, flow, flag,
sum(flag) over(partition by id order by st_time) as sum_flag
from
(select
id, st_time, end_time, last_end_time, sub_time, flow,
case when sub_time>=10 then 1 else 0 end as flag
from
(select id, st_time, end_time, last_end_time, flow, (unix_timestamp(st_time)- unix_timestamp(last_end_time))/60 as sub_time
from
(select t.id,
to_timestamp(t.start_time) as st_time,
to_timestamp(t.end_time) as end_time,
to_timestamp(t.last_end_time) as last_end_time,
t.flow
from
(select *,
lag(end_time,1, start_time) over(partition by id order by start_time) as last_end_time
from temp.demo_2_table ) as t ) as t2 ) as t3 ) as t4
# 第六步:如果连续2条数据的分组flag相同,则需要累加
select
id, min(st_time) as st_time, max(end_time) as end_time, sum(flow) as flow_sum
from
(select id, st_time, end_time, last_end_time, sub_time, flow, flag,
sum(flag) over(partition by id order by st_time) as sum_flag
from
(select
id, st_time, end_time, last_end_time, sub_time, flow,
case when sub_time>=10 then 1 else 0 end as flag
from
(select id, st_time, end_time, last_end_time, flow, (unix_timestamp(st_time)- unix_timestamp(last_end_time))/60 as sub_time
from
(select t.id,
to_timestamp(t.start_time) as st_time,
to_timestamp(t.end_time) as end_time,
to_timestamp(t.last_end_time) as last_end_time,
t.flow
from
(select *,
lag(end_time,1, start_time) over(partition by id order by start_time) as last_end_time
from temp.demo_2_table ) as t ) as t2 ) as t3 ) as t4 ) as t5
group by id, sum_flag
第五步结果
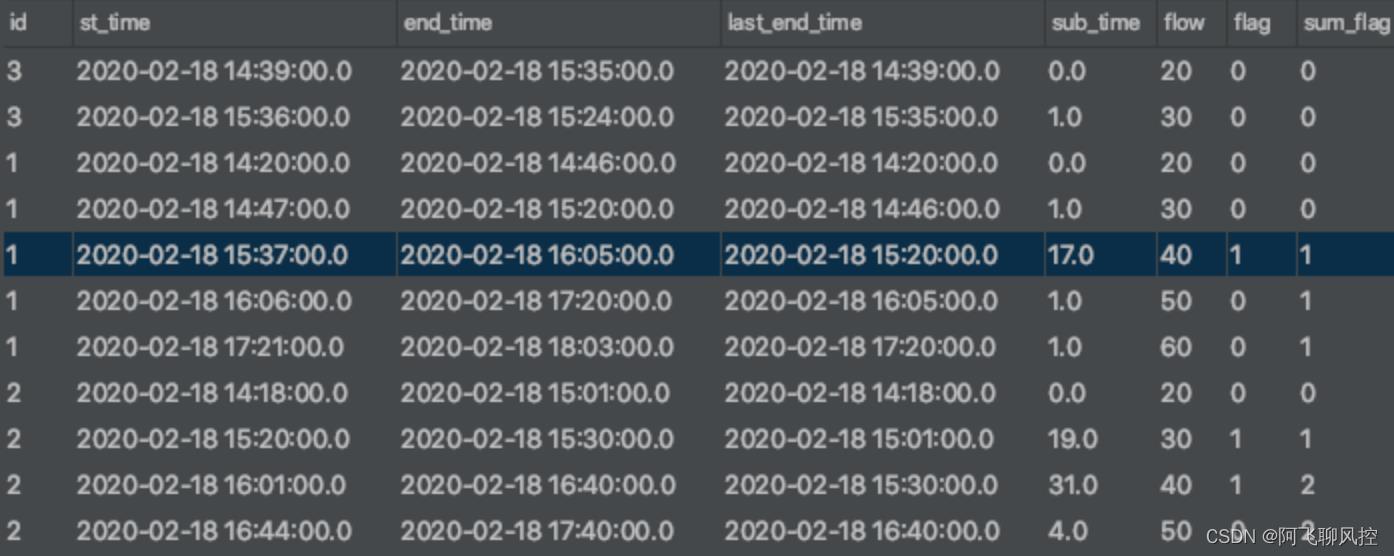
最终结果:

- TOP N问题:实现每班前三名,分数一样并列,同时求出前三名按名次排序的一次的分差
数据:
stu_no class score
1 1901 90
2 1901 90
3 1901 83
4 1901 60
5 1902 66
6 1902 23
7 1902 99
8 1902 67
9 1902 87
select stu_no, class, score, rnk, pre_score, pre_score - score as score_diff from
(select *, lag(score,1, score) over(partition by class order by rnk ) as pre_score from
(select stu_no, class, score, rank() over(partition by class order by score desc ) as rnk from temp.test_demo_7
having rnk<=3) as t1 ) as t2

- 行列互换-列转行
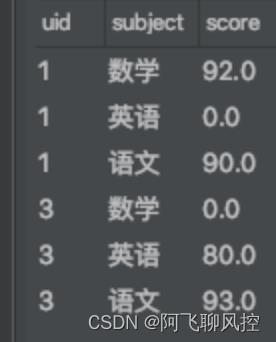
数据:
1,语文,90
1,数学,92
3,英语,80
3,语文,93
代码:
-- 行列互换
select uid,
sum(case subject when '语文' then score else 0 end) as is_chinese,
sum(case subject when '数学' then score else 0 end) as is_math,
sum(case subject when '英语' then score else 0 end) as is_english,
sum(score) as total_score
from temp.test_demo_8
group by uid
-- 或者
select uid,
sum(case when subject='语文' then score else 0 end) as is_chinese,
sum(case when subject='数学' then score else 0 end) as is_math,
sum(case when subject='英语' then score else 0 end) as is_english,
sum(score) as total_score
from temp.test_demo_8
group by uid

- 行列互换-行转列
原数据:

select uid, subject, score from
(select uid, '数学' as subject, is_math as score from temp.demo_10 )
union all (select uid, '语文' as subject, is_chinese as score from temp.demo_10 )
union all (select uid, '英语' as subject, is_english as score from temp.demo_10 )
order by uid, subject
- hive中coalesce()、nvl()、concat_ws()、collect_list()、 collect_set()、regexp_replace().这几个函数的意义
coalesce(表达式1, 表达式2,..., 表达式n) n>=2, 返回第一个不为空的表达式,如果都为空则返回空
nvl()、nvl(T v1,T v2):空值判断。如果v1为空则返回v2,不为空则为v1.v1,v2 为同类型数据
concat_ws()、concat_ws(separator,str1,str2,....):指定分隔符(第一位)连接字符串函数。参数需要字符串
collect_list()、 collect_list(T col):将某列的值连在一起,返回字符串数组,有相同的列值不会去重
collect_set()、 collect_set(T col):将某列的值连接在一起,返回字符串数组,有相同的列值会去重
regexp_replace(). 用一个指定的 replace_string 来替换匹配的模式,从而允许复杂的"搜 索并替换"操作
- 你们公司使用什么来做的cube
一般分为基本聚合和高级聚合
基本聚合就是常见的group by,高级聚合就是grouping set、cube、rollup等。
一般group by与hive内置的聚合函数max、min、count、sum、avg等搭配使用。
1、grouping sets可以实现对同一个数据集的多重group by操作。
事实上grouping sets是多个group by进行union all操作的结合,它仅使用一个stage完成这些操作。
grouping sets的子句中如果包换() 数据集,则表示整体聚合。多用于指定的组合查询。
2、cube俗称是数据立方,它可以时限hive任意维度的组合查询。
即使用with cube语句时,可对group by后的维度做任意组合查询
如:group a,b,c with cube ,则它首先group a,b,c 然后依次group by a,c 、 group by b,c、group by a,b 、group a 、group b、group by c、group by () 等这8种组合查询,所以一般cube个数=2^3个。2是定 值,3是维度的个数。多用于无级联关系的任意组合查询。
3、rollup是卷起的意思,俗称层级聚合,相对于grouping sets能指定多少种聚合,而with rollup则表示从左 往右的逐级递减聚合,如:group by a,b,c with rollup 等价于 group by a, b, c grouping sets( (a, b, c), (a, b), (a), ( )).直到逐级递减为()为止,多适用于有级联关系的组合查询,如国家、省、市级联组合查 询。
4、Grouping__ID在hive2.3.0版本被修复过,修复后的发型版本和之前的不一样。对于每一列,如果这列 被聚合 过则返回0,否则返回1。应用场景暂时很难想到用于哪儿。
-
计算用户的pv和uv
pv:page review 页面的浏览量
uv: unique visitor 浏览的用户量(用户需要去重,一天内一个客户只能算一次) -
模糊查询 like
%: 表示任意0个或者多个字符,可匹配任意形状和长度的字符;有些情况下若是中文,请使用两个百分号(%%)表示
_: 表示任意单个字符
'a%' :以a开头的数据
'%a' :以a结尾的数据
'%a%':含有a的数据
'_a_' :三位且中间字母是a的
以上是关于c# SQL登陆问题的主要内容,如果未能解决你的问题,请参考以下文章
C#程序访问SQL2008报错:已成功与服务器建立联系,但登陆前握手期间发生错误
用C#做一个只有登陆后才能显示的页面,普通进入提示请先登录。急求高手!