Mycat生产实践---数据迁移与扩容实践
Posted wangshuang1631
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mycat生产实践---数据迁移与扩容实践相关的知识,希望对你有一定的参考价值。
1 离线扩容缩容
工具目前从mycat1.6开始支持。
一、准备工作
1、mycat所在环境安装mysql客户端程序
2、mycat的lib目录下添加mysql的jdbc驱动包
3、对扩容缩容的表所有节点数据进行备份,以便迁移失败后的数据恢复
二、扩容缩容步骤
1、复制schema.xml、rule.xml并重命名为newSchema.xml、newRule.xml放于conf目录下
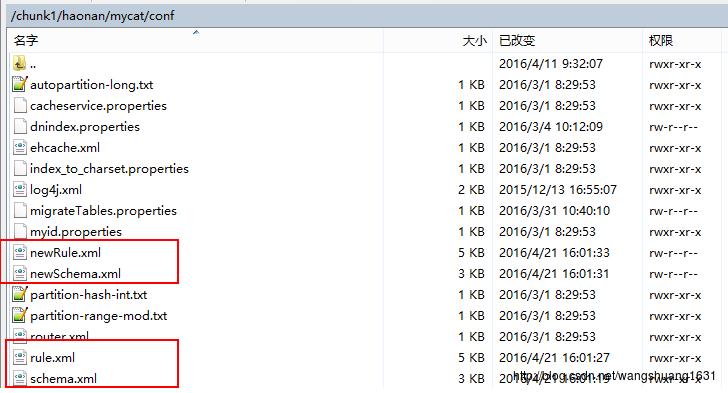
2、修改newSchema.xml和newRule.xml配置文件为扩容缩容后的mycat配置参数(表的节点数、数据源、路由规则)
3、修改conf目录下的migrateTables.properties配置文件,告诉工具哪些表需要进行扩容或缩容,没有出现在此配置文件的schema表不会进行数据迁移,格式:

4、修改bin目录下的dataMigrate.sh脚本文件,参数如下:
tempFileDir 临时文件路径,目录不存在将自动创建
isAwaysUseMaster默认true:不论是否发生主备切换,都使用主数据源数据,false:使用当前数据源
mysqlBin:mysql bin路径
cmdLength mysqldump命令行长度限制 默认110k 110*1024。在LINUX操作系统有限制单条命令行的长度是128KB,也就是131072字节,这个值可能不同操作系统不同内核都不一样,如果执行迁移时报Cannot run program "sh": error=7, Argument list too long 说明这个值设置大了,需要调小此值。
charset导入导出数据所用字符集 默认utf8
deleteTempFileDir完成扩容缩容后是否删除临时文件 默认为true
threadCount并行线程数(涉及生成中间文件和导入导出数据)默认为迁移程序所在主机环境的cpu核数*2
delThreadCount每个数据库主机上清理冗余数据的并发线程数,默认为当前脚本程序所在主机cpu核数/2
queryPageSize 读取迁移节点全部数据时一次加载的数据量 默认10w条5、停止mycat服务(如果可以确保扩容缩容过程中不会有写操作,也可以不停止mycat服务)
6、通过crt等工具进入mycat根目录,执行bin/ dataMigrate.sh脚本,开始扩容/缩容过程:
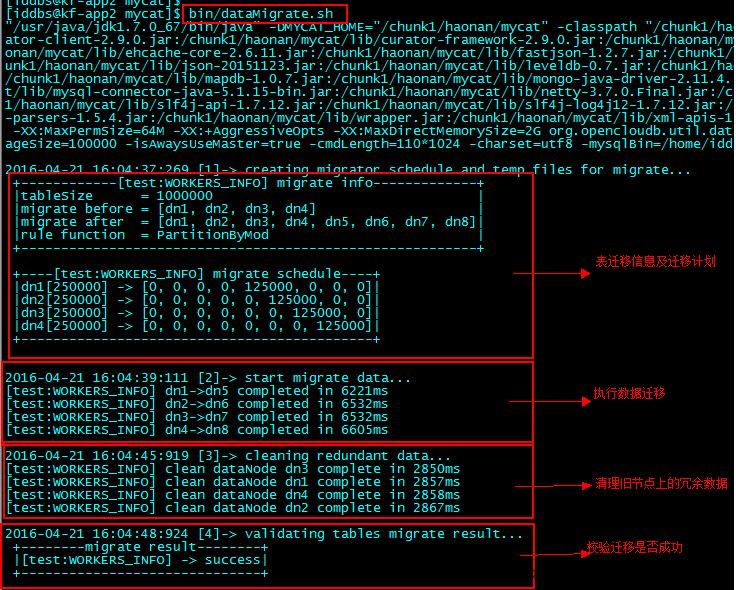
7、扩容缩容成功后,将newSchema.xml和newRule.xml重命名为schema.xml和rule.xml并替换掉原文件,重启mycat服务,整个扩容缩容过程完成。
三、注意事项:
1) 保证拆分表迁移数据前后路由规则一致
2) 保证拆分表迁移数据前后拆分字段一致
3) 全局表将被忽略
4) 不要将非拆分表配置到migrateTables.properties文件中
5) 暂时只支持拆分表使用mysql作为数据源的扩容缩容
四、优化
dataMigrate.sh脚本中影响数据迁移速度的有4个参数,正式迁移数据前可以先进行一次测试,通过调整以下参数进行优化获得一个最快的参数组合
threadCount脚本执行所在主机的并行线程数(涉及生成中间文件和导入导出数据)默认为迁移程序所在主机环境的cpu核数*2
delThreadCount每个数据库主机上清理冗余数据的并发线程数,默认为当前脚本程序所在主机cpu核数/2,同一主机上并发删除数据操作线程数过多可能会导致性能严重下降,可以逐步提高并发数,获取执行最快的线程个数。
queryPageSize 读取迁移节点全部数据时一次加载的数据量 默认10w条
cmdLength mysqldump命令行长度限制 默认110k 110*1024。尽量让这个值跟操作系统命令长度最大值一致,可以通过以下过程确定操作系统命令行最大长度限制:
逐步减少100000,直到不再报错
/bin/sh -c "/bin/true $(seq 1 100000)"
获取不报错的值,通过wc –c统计字节数,结果即操作系统命令行最大长度限制(可能稍微小一些)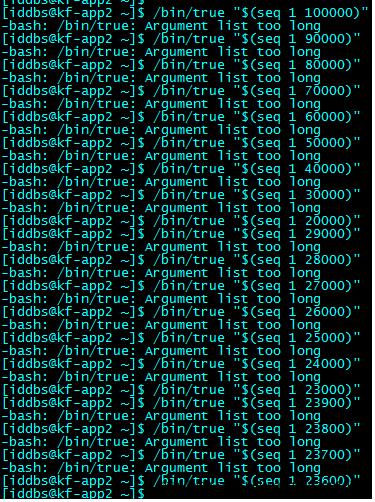

2 案例一:使用一致性Hash进行分片
当使用一致性Hash进行路由分片时,假设存在节点宕机/新增节点这种情况,那么相对于使用其他分片算法(如mod),就能够尽可能小的改变已存在key映射关系,尽可能的减少数据迁移操作。当然一致性hash也有一个明显的不足,假设当前存在三个节点A,B,C,且是使用一致性hash进行分片,如果你想对当前的B节点进行扩容,扩容后节点为A,B,C,D,那么扩容完成后数据分布就会变得不均匀。A,C节点的数据量是大于B,D节点的。
据测试,分布最均匀的是mod,一致性哈希只是大致均匀。数据迁移也是,迁移量最小的做法是mod,每次扩容后节点数都是2的N次方,这样的迁移量最小。但是mod需要对每个节点都进行迁移,这也是mod的不足之处。总之,还得酌情使用,根据业务选择最适合自己系统的方案。
2.1 配置使用
rule.xml:定义分片规则
<tableRule name="sharding-by-murmur">
<rule>
<columns>SERIAL_NUMBER</columns> <algorithm>murmur</algorithm>
</rule> </tableRule>
<function name="murmur" class="org.opencloudb.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<property name="count">2</property>
<property name="virtualBucketTimes">160</property>
</function>tableRule定义分片规则
- name:分片规则的名字。在schema.xml文件中调用。
- columns:根据数据库中此字段进行分片。
- algorithm:值是分片算法定义处的name属性。比如:murmur。
function定义一致性Hash的参数
- seed:计算一致性哈希的对象使用的数值,默认是0。
- count:待分片的数据库节点数量,必须指定,否则没法分片。
- virtualBucketTimes:虚拟节点。默认是160倍,也就是虚拟节点数是物理节点数的160倍。指定virtualBucketTimes可以使一致性hash分片更加均匀。
- bucketMapPath:用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur
hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西。必须是绝对路径,且可读写。
schema.xml:定义逻辑库,表、分片节点等内容
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="mycat" checkSQLschema="false" sqlMaxLimit="100">
<table name="T_CMS_ORDER" primaryKey="ORDER_ID" dataNode="dn202_3316"
rule="sharding-by-murmur" />
</schema>
<dataNode name="dn202_3316" dataHost="lh202_1" database="poc" />
<dataHost name="lh202_1" maxCon="2000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="master_host-m1" url="10.21.17.202:3316"
user="usr" password="pwd"></writeHost>
<writeHost host="savle_host-m1" url="10.21.17.201:3317"
user="usr" password="pwd"></writeHost>
</dataHost>
</mycat:schema>server.xml:定义用户以及系统相关变量,如端口等。没有太高要求的可以只修改数据库部分。
<user name="mycat"> <property name="password">usr</property> <property name="schemas">pwd</property> </user>经过以上配置就可以使用一致性hash了。
2.2 一致性Hash的数据迁移
开始迁移
进行一致性hash进行迁移的时候,假设你新增加一个节点,需要修改以下两个配置文件:
rule.xml
<function name="murmur" class="org.opencloudb.route.function.PartitionByMurmurHash"> <property name="seed">0</property>
<property name="count">3</property> <property name="virtualBucketTimes">160</property> <!-- <property name="weightMapFile">weightMapFile</property> <property name="bucketMapPath">/home/usr/mycat/bucketMapPath</property> --> </function>需要把节点的数量从2个节点扩为3个节点。
schema.xml
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="mycat" checkSQLschema="false" sqlMaxLimit="100">
<table name="T_CMS_ORDER" primaryKey="ORDER_ID" dataNode="dn202_3316,dn201_3316"
rule="sharding-by-murmur" />
</schema>
<dataNode name="dn202_3316" dataHost="lh202_1" database="poc" />
<dataNode name="dn201_3316" dataHost="lh201_1" database="poc" />
<dataHost name="lh202_1" maxCon="2000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="master_host-m1" url="10.21.17.202:3316"
user="usr" password="pwd"></writeHost>
<writeHost host="savle_host-m1" url="10.21.17.201:3317"
user="usr" password="pwd"></writeHost>
</dataHost>
<dataHost name="lh201_1" maxCon="2000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="master_host-m1" url="10.21.17.201:3316"
user="usr" password="pwd"></writeHost>
<writeHost host="savle_host-m1" url="10.21.17.202:3317"
user="usr" password="pwd"></writeHost>
</dataHost>
</mycat:schema>需要添加新节点的dataNode和dataHost信息,以及在schema中的table标签下把新增节点的dataNode的name增加到dataNode的值中。
2.3 开始迁移
使用org.opencloudb.util.rehasher.RehashLauncher类进行数据迁移。参数以命令行的形式进行载入。如
-jdbcDriver=xxxxx -jdbcUrl=.... -host=192.168.1.1:3316 -user=xxxx -password=xxxx -database=xxxx- jdbcDriver:数据库驱动。如com.mysql.jdbc.Driver。
- jdbcUrl:连接数据库的url,不同数据库不一样。如jdbc:mysql://10.21.17.201:3316/mycat?rewriteBatchedStatements=true。
- host:包括主机名和端口,形如ip:port。如10.21.100.86:3316
- user:连接数据库的用户名。如usr
- database:数据库的名字。如mycat。
- password:连接数据库的密码。如pwd。
- tablesFile:记录数据表的文件,一个表一行。
- shardingField:数据库中进行分片的字段。
- rehashHostsFile:这个参数没有用到,按照当时的要求,这个类一次只处理一个节点,所以不需要配置
- hashType:是MURMUR hash还是mod hash。
- seed:生成一致性hash对象的参数。默认为0。
- virtualBucketTimes:虚拟节点的倍数。默认为160。
- weightMapFile:节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替。
- rehashNodeDir:一个linux目录,这个程序执行完了,把计算结果输出到这个目录,一个表一个文件存在这个目录里,文件名是表名。
如果你觉得使用命令行的方式去读取配置不是那么方便,你也可以自己定义读取配置文件的算法,只要能保证org.opencloudb.util.rehasher.RehashLauncher这个类能够读到所有的配置就可以了。比如使用properties文件保存配置文件(每次修改配置文件后都需要重新编译),本着怎么方便怎么写代码的原则,就是这么任性。
运行org.opencloudb.util.rehasher.RehashLauncher后生成的文件格式如下:
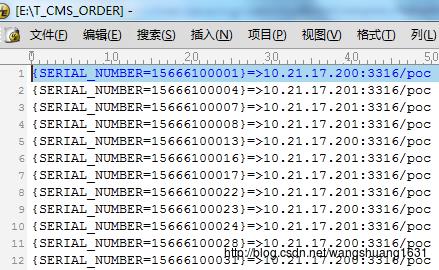
为了方便进行迁移,我们可以对代码进行适当的修改,如
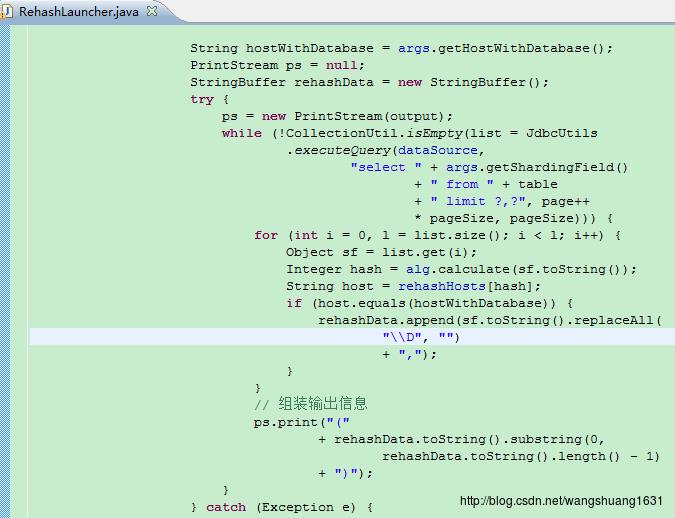
通过此种方式拼装,生成的文件如下:
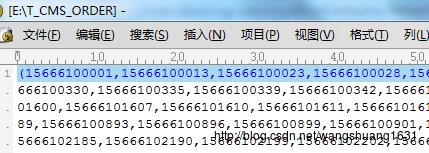
形如(15666100001,15666100013,15666100023,15666100028),这个就可以作为in条件了。 生成文件后,可以在linux环境下通过shell的方式进行数据迁移,当然前提是你得停机。
迁移脚本如下:
rehashNode=$1
expanNode=$2
order_fn="$3"
if [ "$#" = "0" ]; then
echo "Please input parameter, for example:"
echo "ReRouter.sh 192.168.84.13 192.168.84.14 /home/mycat/T_CMS_ORDER "
echo " "
exit fi;
echo "需要进行迁移的主机总量为:$#, 主机IP列表如下:"
for i in "$@"
do
echo "$i"
done
echo " "
#取出rehash需要的SerNum(已经用in拼接好)
for n in `cat $order_fn`
do
condOrder=$n
done echo "************* 导出 *************"
date
# 1) 首先调用mysqldump进行数据导出
echo "开始导出主机:$ 表:T_CMS_ORDER."
mysqldump -h$rehashNode -P3316 -upoc -ppoc123 poc T_CMS_ORDER --default-character-set=utf8 --extended-insert=false --no-create-info --add-locks=false --complete-insert --where=" SERIAL_NUMBER in $condOrder " > ./T_CMS_ORDER_temp.sql
echo "导出结束."
echo " "
echo "************* 导入 *************" date
# 2) 调用mycat接口进行数据导入
echo "开始导入T_CMS_ORDER表数据"
mysql -h$expanNode -P8066 -upoc -ppoc123 poc --default-character-set=utf8 < ./T_CMS_ORDER_temp.sql echo "导入结束."
echo " "
echo "************* 删除数据 *************" date
# 3) 当前两步都无误的情况下,删除最初的导出数据.
echo "开始删除已导出的数据表:."
mysql -h$rehashNode -P3316 -upoc -ppoc123 -e "use poc; DELETE FROM T_CMS_ORDER WHERE SERIAL_NUMBER in $condOrder ; commit; "
echo "删除结束."
echo " "
echo "************* 清空临时文件 *************" date
# 4) 清空临时文件 rm ./t_cms_order_temp.sql
echo "清空临时文件"
echo "#####################主机:$rehashNode 处理完成#####################"
date
echo " " echo "ReHash运行完毕."假设文件名是:ReHashRouter.sh
- 授权:chmod +x ReHashRouter.sh
- 运行:./ReHashRouter.sh 10.21.17.200 10.21.17.201
/home/mycat/T_CMS_ORDER
3 案例二:使用范围分片
在使用范围分片算法进行路由分片时,配置非常简单。如下:
3.1 配置使用
rule.xml:定义分片规则
<tableRule name="auto-sharding-long">
<rule>
<columns>user_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long"
class="org.opencloudb.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>tableRule定义分片规则
- name:分片规则的名字。在schema.xml文件中调用。
- columns:根据数据库中此字段进行分片。
- algorithm:值是分片算法定义处的name属性。比如:rang-long。
function定义范围分片的参数
可以看到根据范围自动分片的配置文件非常简单,只有一个mapFile(要赋予读的权限),此mapFile文件定义了每个节点中user_id的范围,如果user_id的值超过了这个范围,那么则使用默认节点。当前版本代码中默认节点的值是-1,表示不配置默认节点,超过当前范围就会报错。当然你也可以在property中增加defaultNode的默认值,如:
<property name="defaultNode">0</property>mapFile节点配置文件
当前版本提供了一个mapFile配置文件供大家参考和使用,如下
# range start-end ,data node index
# K=1000,M=10000. 0-500M=0 500M-1000M=1所有的节点配置都是从0开始,及0代表节点1,此配置非常简单,即预先制定可能的id范围到某个分片。
(tips:K和M的定义是在org.opencloudb.route.function.NumberParseUtil中定义的,如果感兴趣的同学可以自己定义其他字母。)
扩容
如果业务需要或者数据超过当前定义的范围,需要新增节点,则可以在文件中追加 1000M-1500M=2 即可。当然新增的节点需要在schema.xml中进行定义。
# range start-end ,data node index
# K=1000,M=10000. 0-500M=0
500M-1000M=1 1000M-1500M=24 数据迁移的注意点
4.1 迁移时间的确定
在进行迁移之前,我们得先确定迁移操作发生的时间。停机操作需要尽可能的让用户感知不到,你可以观察每段时间系统的吞吐量,以此作为依据。一般来说,我们选择在凌晨进行升级操作。
4.2 数据迁移前的测试
需要做一些相关的性能测试,在条件允许的情况下在类似的环境中完全模拟,得到一些性能数据,然后不断的改进,看能够否有大的提升。
我们在做数据迁移的时候,就是在备份库中克隆的一套环境,然后在上面做的性能测试,在生产上的步骤方式都一样,之后在正式升级的时候就能够做到心中有数。什么时候需要注意什么,什么时候需要做哪些相关的检查。
4.3 数据备份
热备甚至冷备,在数据迁移之前进行完整的备份,一定要是全量的。甚至在允许的情况下做冷备都可以。数据的备份越充分,出现问题时就有了可靠的保证。
lob数据类型的备份,做表级的备份(create table nologging….),对于lob的数据类型,在使用imp,impdp的过程中,瓶颈都在lob数据类型上了,哪怕表里的lob数据类型是空的,还是影响很大。自己在做测试的时候,使用Imp基本是一秒钟一千条的数据速度,impdp速度有所提升,但是parallle没有起作用,速度大概是1秒钟1万条的样子。
如果在数据的导入过程中出了问题,如果有完整快速的备份,自己也有了一定的数据保证,要知道出问题之后再从备份库中导入导出,基本上都是很耗费时间的。
4.4 数据升级前的系统级检查
- 内存检查。可以使用top,free -m来做一个检查,看内存的使用情况是否正常,是否有足够的内存空间。
- 检查cpu,io情况。查看iowait是否稳定,保持在较低的一个幅度。
- 检查进程的情况。检查是否有高cpu消耗的异常进程,检查是否有僵尸进程,排查后可以杀掉。
- 是否有crontab的设置。如果在升级的时候有什么例行的job在运行,会有很大的影响,可以使用crontab -l来查看crontab的情况。
- vxfs下的odm是否已经启用。如果使用的veritas的文件系统,需要检查一下odm是否正常启用。
- IO 简单测试。从系统角度来考虑,需要保证io的高效性。可以使用iostat,sar等来评估。
- 网络带宽。数据迁移的时候肯定会从别的服务器中传输大量的文件,dump等,如果网络太慢,无形中就是潜在的问题。可以使用scp来进行一个简单的测试。
4.5 异常情况
网络临时中断。网络的问题需要格外重视,可能在运行一些关键的脚本时,网络突然中断,那对于升级就是灾难,所以在准备脚本的时候,需要考虑到这些场景,保留完整的日志记录。
可以使用nohup来做外后台运行某些关键的脚本。这样网络断了以后,还有一线希望。在数据迁移,数据升级的时候,一定要保留完整的日志记录,这样如果稍候有问题,也可以及时查验,也可以避免很多不必要的纷争。如果有争议,可以找出日志来,一目了然。
当然,这样会有大量的日志产生,一定需要保证归档空间足够大,及时的转移归档文件。排除归档爆了以后数据的问题,使用sqlloader,impdp等数据迁移策略的时候,如果归档出了问题,是很头疼的问题。
5 load data批量导入
load data infile语句可以从一个文本文件中以很高的速度读入一个表中。性能大概是insert语句的几十倍。通常用来批量数据导入。目前只支持mysql数据库且dbDriver必须为native。Mycat支持load data自动路由到对应的分片。Load data和压缩协议mycat从1.4开始支持。
5.1 语法和注意事项
标准示例:
load DATA local INFILE 'd:\\88\\qq.txt' IGNORE INTO TABLE test CHARACTER SET 'gbk' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\\n'(id,sid,asf) ;注意:如果数据中可能包含一些特殊字符,比如分割符转义符等,建议用引号扩起来,通过OPTIONALLY ENCLOSED BY ‘”’指定。如果这样还不行,可以把字段值中的引号替换成\\”。
如果指定local关键词,则表明从客户端主机读文件。如果local没指定,文件必须位于mycat所在的服务器上。
可以通过fields terminated by指定字符之间的分割符号,默认值为\\t
通过lines terminated by可以指定行之间的换行符。默认为\\n,这里注意有些windows上的文本文件的换行符可能为\\r\\n,由于是不可见字符,所以请小心检查。
character set 指定文件的编码,建议跟mysql的编码一致,否则可能乱码。其中字符集编码必须用引号扩起来,否则会解析出错。
还可以通过replace | ignore指定遇到重复记录是替换还是忽略。
目前列名必须指定,且必须包括分片字段,否则没办法确定路由。
其他参数参考mysql的load data infile官方文档说明。
注意其他参数的先后顺序不能乱,比如列名比较在最后的,顺序参考官方说明。
标准load data语句: LOAD DATA语句,同样被记录到binlog,不过是内部的机制.
例子: 导出:
select * from tblog_article into outfile '/test.txt' FIELDS TERMINATED BY '\\t' OPTIONALLY ENCLOSED BY '' ESCAPED BY '\\\\' LINES TERMINATED BY '\\n'; 导入:
load data local infile '/var/lib/mysql/blog/test.txt' INTO TABLE tblog_article FIELDS TERMINATED BY '\\t' OPTIONALLY ENCLOSED BY '' ESCAPED BY '\\\\' LINES TERMINATED BY '\\n' (id,title,level,create_time,create_user,create_user,article_type_id,article_content,istop,status,read_count );5.2 客户端配置
如果是mysql命令行连接的mycat,则需要加上参数–local-infile=1。Jdbc则无需设置。
Load data测试性能
在一台win8下 ,jvm 1.7 参数默认,jdbc连接mycat。

测试结果load data local导入1百万数据到5个分片耗时10秒,1千万数据到5个分片耗时145秒。
6 使用mysqldump进行数据迁移
mysqldump是mysql自带的命令行工具。可以用它完成全库迁移(从一个mysql库完整迁移到mycat),也可以迁移某几个表,还可以迁移某个表的部分数据。
6.1 全库迁移
迁移前准备
迁移前确保mysql库和mycat库中的表名一样(mycat库中只需要有表名配置在schema.xml文件中即可)
从mysql导出
从mysql库上全库导出 mysqldump -c -–skip-add-locks databaseName> /root/databaseName.sql
注意:(上面的语句没有-uroot -ppassword参数,是因为mysql服务器设置了本机免密码等。
如果设置了密码:通过以下命名导出(用户名为root,密码为123456): mysqldump -uroot -p123456 -c -–skip-add-locks databaseName> /root/databaseName.sql
)
说明:两个参数不可少,如下:
-c参数不可少,-c, 全称为–complete-insert 表示使用完整的insert语句(用列名字)。
-–skip-add-locks表示导数据时不加锁,如果加锁涉及多分片时容易导致死锁。
导入到mycat
将databaseName.sql拷贝到mycat集群中的一台mysql服务器上/root目录下。
连接mycat:
mysql -uusername -ppassword -h172.17.xxx.xxx -P8066
切换到指定的数据库: use databaseName;
导入脚本: source /root/databaseName.sql;
6.2 迁移一个库中的某几个表
只是导出命令不同,其他与全库迁移一样
mysqldump -c -–skip-add-locks databaseName table1 table2> /root/someTables.sql7 迁移一个表中的部分数据
迁移一个表中的部分数据,加参数–where实现。
命令如下:
mysqldump -c -–skip-add-locks databaseName tableName --where=" id > 900 " > /root/onetableDataWithCondition.sql以上是关于Mycat生产实践---数据迁移与扩容实践的主要内容,如果未能解决你的问题,请参考以下文章