Scrapy见面第五天
Posted 九茶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy见面第五天相关的知识,希望对你有一定的参考价值。
这算是我第一次使用框架吧,说来惭愧。
此前用Request带上cookie实现、(稍微)完善了QQ空间的爬虫(传送门),接下来想实现分布式去爬。其实只要能实现待爬QQ队列的共享,分布式的主要问题也就解决了。但是觉得这样实现的爬虫项目有点“不正规”,所以想用Scrapy框架和Redis数据库来整顿现有爬虫。无奈公司里也没什么人指点,全凭一人摸爬滚打,过程有点痛苦,但自信只要敢啃,还是可以拿下的,不成问题。
然后就动手了。
(忽略安装过程,估计是以前用其他模块的时候已经吐血吐够了,环境都配好了,竟然直接用 pip install scrapy 就成功了)
第一步、当然是百度,看看传说中的“正规军”是什么样子的,快速了解了一下Scrapy工作机制,以及大家在使用scrapy的时候关注的点更多在哪里。然而看的都是似懂非懂,,然而并不重要,我只需要和它碰个面即可。
第二步、搜GitHub,找代码。搜了十几个demo,快速看了一下scrapy的代码结构。
第三步、从各种平台搜索和Scrapy有关的东西,特别是大家对它的看法,主要途径:新浪微博、知乎、推酷、Google。
第四步、调试、运行从GitHub上download下来的demo,大约了解scrapy具体的运行机制。
第五步、是时候静下心来啃Scrapy的官方文档了,受益良多。
第六步、糗事百科作靶子,模仿demo实战练习,再功能延生。
第七步、即现在,第五天。
其实遇到的问题还是挺多的,主要的原因是对Scrapy了解不够深入。想要入门Scrapy容易,但是想要单枪匹马快速入门,就很需要看重怎么走了。
我是想着先实现简单的Scrapy爬虫,再用Redis实现分布式。在此之后再进行功能拓展,例如Cookie登录,例如爬虫数据的增加,例如异常处理、性能优化等等。总体的思路是先纵向深入,再横向逐个拓展。
计划虽是这样,但终归还是没忍住花了一天时间动手实现了一下QQ空间和新浪微博的Scrapy爬虫。自增苦恼,不过有所收获。
首先是QQ空间,我之前是用Request的session带上Cookie去打开js的请求,返回来的是js文件,里面包含我所需要的信息。直接请求js文件的好处是数据量小,数据流通和数据处理的花销会小很多(反正我的小本本一个小时能抓17万条说说)。而如今,我用Scrapy带上Cookie却返回403(已带表头),我试着打开空间主页的URL,返回的是html文件,这很正常,没有JS文件。但为什么打开JS的请求却报错403了呢?这个问题暂先放着。其实空间更蛋疼的问题还没解决呢——Cookie,普通的登录(例如知乎)是发送个表单就行了,但QQ空间的表单,年轻的我没有找到(估计要一点点调试看它的加密算法了,之前的爬虫我是用phantomjs模拟浏览器获取到的)。百度和Google也没有搜到结果,甚至爬QQ空间人就很少,大伙对它没兴趣?
QQ空间爬不成,我试一下微博。很明显大伙对微博的兴趣就高很多了,已经有加密算法和构造表单的方法了。而且我在查看Cookie的时候看到新浪的Cookie有效期是六天左右(未检验)(QQ空间的Cookie有效期在几十分钟到十几个钟不等),如果是这样的话我们就算手动输入Cookie那也没什么呀。不过微博还有一个问题,JS加载。网上的说法是构造下载中间件,具体还有待解决。不过此时看到scrapy的那张架构图(如下)就另外一种感觉了呀,终于对各个部分有一点认识了!不过如果用Redis实现分布式的话Pipeline和Scheduler之间是不是应该要有个数据流通呀?
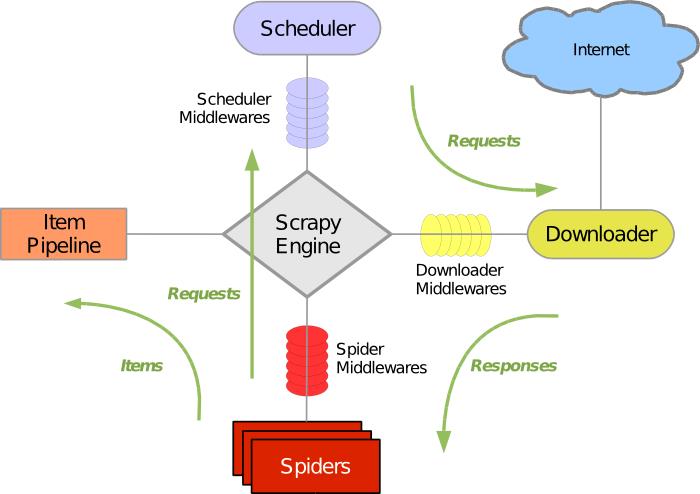
感觉当前的难点更多的还是在右半边,获取数据。
接下来,构造中间件。
继续勘探,尽快熟悉Scrapy与分布式!
转载请注明出处,谢谢!(原文链接:http://blog.csdn.net/bone_ace/article/details/50811004)
以上是关于Scrapy见面第五天的主要内容,如果未能解决你的问题,请参考以下文章