字符编码初识
Posted LeeeetMe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符编码初识相关的知识,希望对你有一定的参考价值。
对于刚学习Python同学,都应该绕不开一个字符编码的问题,让我们来搞一搞。
一.字符集与字符编码(字符编码和字符集是两个概念):
1)
字符只有按照一定规则编码,最终表现为0/1二进制序列的形式,才能被计算机处理,那么,大家只要按照相同规则,规定好字符和二进制序列之间的对应关系即可
例如:英语大写字母 A 对应数字 65,这样我们只要保存65的二进制位01000001就好。(ASCII编码,最初有127个编码编辑到计算机中)
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,各个国家就推出了自己的字符集,就是人们统计预先规定好的一系列字符与二进制序列(数字)之间的映射关系。而且各个国家的字符都是不同的,各国都各国的标准,就不可避免的出现冲突,结果就是不同的环境中显示出来就有可能出现乱码。(中国-GB2312,日本-Shift_JIS,韩国-Euc-kr).
2)
我们规定好了字符与数字之间的对应关系(字符集),但这并不代表计算机一定要按照字符对应的数字将数字本身直接存储!有时候,我们按照一定的规则,将字符的码元再次处理,以更加适应计算机存储、网络传输的需要。字符编码便是规定了如何编码、存储这些字符对应的二进制序列。
字符集是一种协议,而字符编码是对字符集的一种实现。当然,既然称之为"实现",也说明对同一种字符集可能有不同的编码方式。
Unicode
为了统一规则,世界某某组织,就推出了Unicode编码:
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。也即,UCS规定了怎么用多个字节表示各种文字,而怎样存储、传输这些编码,则是由UTF规定.
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符\'0\'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:

搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
2.各个环境中的编码:
1)操作系统默认编码方式:
这是操作系统的内部属性,比如大多Linux系统、Mac OS默认UTF-8编码,中文版Windows系统默认GBK编码。
2)终端编码方式:
终端包括cmd、shell、terminal等,在与终端交互时,字符是要在终端显示的,这必然涉及到终端采用的编码方式,事实上有不少bug是在这个层面产生的。对于单机系统而言,终端编码与操作系统编码一般是一致的,但在远程登录时,可能会遇到一些问题。
3)文本文件的编码方式:
这是我们接触最多的概念,即一个文本文件(如源代码文件)是以什么编码格式保存的(如PyCharm中的 # -*- Coding:UTF-8 -*-)。大多数编辑器可以显示文本的编码格式,以及更改编码方式重新存储。
4)程序中的字符、字符串变量的编码方式:
这与具体的编程语言相关,涉及到程序运行时变量在内存中的状态。
Python典型的encode/decode就是这个:
Python3.x的版本中是默认支持Unicode编码的,而Python2.2之前是不支持Unicode。因此是需要encode/decode转换.
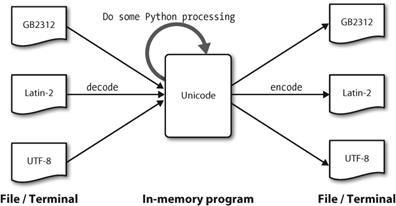
encode(char_set) :实现Unicode到其他编码方式的转换。
decode(char_set) : 实现其他编码方式到Unicode的转换。
Python3.x与2.x的差别就是3.x是默认支持Unicode编码,所以字符串不再区分\'abc\' 与 u\'abc\',字符串默认就是Unicode,不再代表本地编码,没必要在语言环境内做编码设置,也因此
Python3.x的代码和包管理上打破了Python 2.x的兼容。
再次提醒:只有字符到字节或者字节到字符的转换才存在编码转码的概念。
总结:
1.编码最初只有ASCII码,只用了1byte中的7bit(1byte = 8bit ,即00000000~11111111)ASCII便是字符集与字符编码相同的情况,直接将字符对应的8位二进制数作为最终形式储存,当我们提及ASCII,既表示了一种字符集,也代表了一种字符编码,即常说的“ASCII编码”。
2.然后欧洲人发现128个不够用,就把1byte中没用的最高位给用上了,然后各国都出版了属于自己不同的编码。(中国从GB2312(6千多字)->GBK->GB18030.)
3.为了统一,出现了Unicode,可以兼容全世界的文字,分为UCS-2和UCS-4,分别是2byte和4byte.
4.如果说文本中大部分都是英文(英文是要比ASCII码多占用一个字节),那么就浪费一倍的空间,为了更好的传输和存储,所以所以制定了UTF-8/UTF-16/UTF-32.
5.文本和编辑器最好都用UTF-8格式来编辑和存储(UTF-8(无BOM))
留坑:就算是UTF-32,也不是一个字符就表示一个字的。所以你觉得UTF-8的好处是因为兼容ANSI可以被旧代码处理,出事也是迟早的事。
参考资料:
以上是关于字符编码初识的主要内容,如果未能解决你的问题,请参考以下文章
初识Spring源码 -- doResolveDependency | findAutowireCandidates | @Order@Priority调用排序 | @Autowired注入(代码片段