框架1
Posted escapist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了框架1相关的知识,希望对你有一定的参考价值。
目的
实现一个简单的web框架 只实现rest(有一整套严格的规范) 不实现模板渲染
常见框架有 : Rails pyramid bottle web.py flask
理解框架实现原理
动态网页的发展历程
最早的时候,web就是一些静态文件
最早的动态页面是CGI实现的(动态生成返回的内容)
CGI怎么工作?
当请求一个地址的时候,http服务器就会启动一个外部程序,并且把外部程序的输出返回给用户。
CGI协议规范了http和外部程序的通信方式
通信方式:
输入:通过环境变量 http设置环境变量
输出:通过标准输出 http服务器截获外部程序的输出作为输出的
CGI缺陷:并发模式是多进程(每一次请求都启动一个进程),而且进程由http服务器管理造成
效率低(http不仅要提供服务,还要提供进程管理),崩溃的时候处理起来很麻烦,造成性能低下。
使用CGI开发并不慢
CGI发展--->FastCGI(把进程管理交给其他的后台服务来处理)
所以http只需要和FastCGI 通信就行了
http服务器只需要把http协议转化成fastCGI协议,然后通过socket
发送给fastCGI daemon(后台进程)
例如:php fmp
使得并发模型变得多种多样(perl线程池,php进程池),进程管理由fastCGI实现
http服务器只需要管理http请求和响应就行了
单一原则:只做擅长的事情
PEP3333定义WSGI
另一个发展方向-->wsgi通用web服务网关接口 并没有把http服务器分离出来 和FastCGI的不同之处在于
分成两部分:容器(也有叫网关或服务器) 容器实现协议转换http-->WSGI
应用 处理业务逻辑
容器和应用怎么通信?
FastCGI --> 通过socket通信
uWSGI 是一个WSGI的容器
WSGI的容器和应用通过函数调用通信
什么时候?
同一个进程内才能经过函数调用来通信
也就是说WSGI容器和应用必须是跑在同一进程/线程内的
但是并不是说同一进程就不能实现多进程
类比
FastCGI:可以理解http服务器就是容器,Fast daemon就是应用
gunicorn uWSGI 容器 都可以实现多进程
多线程 协程 见WSGI官网或者PEP3333
一个WSGI application 应该是一个callable对象
1 def application(environ,start_response): # 传递的参数有规定:环境 回调函数 2 body=\'hello,world\' 3 status =\'200 ok\' ---http协议状态码的规范 4 headers=[ 5 (\'content-type\',\'text/plain\'), # 每一项都是一个二元组 6 (\'content-length\',str(len(body))) #头信息必须都是 str 7 ] 这些头不是必须的 但通常设置 工作的更好
8 start_response(status,headers) # 代表开始响应了 返回头部信息 9 return [body.encode()] 可以传递多行 ---WSGI解析的时候是迭代的,所以返回列表 10 要是bytes的可迭代对象
http是支持流式处理 使用yield也可以
此时是跑不起来的 因为没有容器
python标准库里面有容器的实现 wsgiref 传递的应用必须要是一个可调用对象


1 if __name__ == \'__main__\': 2 from wsgiref.simple_server import make_server 创建容器的实例 3 server=make_server(\'0.0.0.0\',3000,application) 4 try: 5 server.server_forver() 6 except KeyboardInterrupt: 7 server.shutdown()
environ 请求的内容 是一个字典 本地的和服务端的信息都在里面(包括环境变量)
start_response 必须是callable对象 代表开始响应 传递的是http的头部 这两个参数是位置参数 名字随意
output分为两部分 start_response是返回头部信息
return是返回body体
environ和start_response两个参数都是容器传进来的
gunicron -b 0.0.0.0 文件名:应用名 (必须是一个callable对象)
--threads INT
--help
开发的时候用wsgiref使用方便 生产的用gunicron性能好
QUERY_STRING 里面存储的是用户传递来的参数
127.0.0.1:5000/?name=wanglei&age=15 -->qs = name=wanglei&age=15 解析这些东西就可以得到参数了
environ.get(\'QUERY_STRING\') # 获得 qs
怎么解析?
现在分开了
from html import escape
解析出来的值是list,因为可能存在多个值
from urllib.parse import parse_qs def application(environ, start_response): parm = parse_qs(environ.get(\'QUERY_STRING\')) # 解析出来的是字典 name = parm.get(\'name\', [\'unknown\'])[0] # 因为得到的是一个列表 body = "hello,world {}".format(name) status = \'200 ok\' headers = [(\'content-type\', \'text/html\'), (\'content-length\', str(len(body))) ] start_response(status, headers) return [body.encode()]
http://127.0.0.1:9000/hell0/?name=wanglei&age=22
parse_qs(\'name=wanglei&age=13&name=duan\')
{\'age\':[13],\'name\':[\'wanglei\',\'duan\']}
结果---> hello,world wanglei
这样是比较危险的 可能产生XSS攻击
http://127.0.0.1:9000/hell0/?name=<script type=\'text/javascript\'>alert(\'fuck it\');</script>

这样就可以实现客户端和服务端通信 用 text/html 是比较危险的
1 from urllib.parse import parse_qs 2 from html import escape 3 4 5 def application(environ, start_response): 6 parm = parse_qs(environ.get(\'QUERY_STRING\')) 7 name = parm.get(\'name\', \'unknown\')[0] 8 body = "hello,world {}".format(escape(name)) # 进行转义 9 status = \'200 ok\' 10 headers = [(\'content-type\', \'text/html\'), 11 (\'content-length\', str(len(body))) 12 ] 13 start_response(status, headers) 14 return [body.encode()]
网页结果:
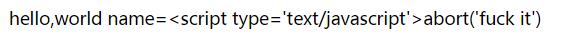
就会进行转义把它当做普通的文本处理
通过qs 就可以实现客户端和服务端通信
可以将environ 抽象成 request对象
将start_response和return抽象成response对象
封装Request对象
import os class Request: def __init__(self, environ): self.params = parse_qs(environ.get(\'QUERY_STRING\')) # 参数 self.path = environ.get(\'PATH_INFO\') self.method = environ.get(\'REQUEST_METHOD\') # 请求方法 self.body = environ.get(\'wsgi.input\') # body内容 self.headers = {} server_env = os.environ for k, v in environ.items(): # headers if k not in server_env.keys(): # 过滤掉服务器端的信息 self.headers[k.lower()] = v
def application(environ, start_response): request = Request(environ)所以简写为以下 面向对象的方式封装Request
name = request.params.get(\'name\', [\'unknown\'])[0] body = "hello,world {}".format(escape(name)) status = \'200 ok\' headers = [(\'content-type\', \'text/html\'), (\'content-length\', str(len(body))) ] start_response(status, headers) return [body.encode()]
封装Response对象
class Response: STATUS={ 200:\'ok\' 404:\'Not found\' } def __init__(self, body=None): if body is None: self.body=\'\' self.body = body self.status=\'200 ok\' self.headers={ \'content-type\':\'text/html\', \'content-length\':\'str(len(body))\' } def set_body(self,body): self.body=body self.headers[\'content-length\']=str(len(self.body))
def set_header(self,name,value):
self.headers[name]=value
def set_status(self,status_code): if status_code in self.STATUS.keys(): self.status=\'{} {}\'.format(status_code,self.STATUS[status_code])
def __call__(self,start_response): start_response(self.status,[(k,v) for k,v in self.headers.items()]) # 列表解析生成 headers return [self.body.encode()]
def application(environ, start_response): request=Request(environ) name = request.parms.get(\'name\', [\'None\'])[0] body = "hello,world %s" % escape(name) return Response(body)(start_response) # 返回给容器
def set_status(self,status_code,status_text=\'\'): self.status=\'{} {}\'.format(status_code,self.STATUS.get(status_code,status_text)) 允许非标准的状态码
为什么要用__call__? 最后返回给容器要是一个可调用对象
很显然不能这么简单的封装
使用webob 类似 flask里面的werzeug都是对请求和响应的封装
webob 现在是 pylons的一个子项目 国外流行
非标状态码 nginx 499
request.parms.getall() 返回所有的 而get 返回最后一个
from webob import Request, Response def application(environ, start_response): request = Request(environ) name = request.params.get(\'name\', \'unknown\') # 有多个值返回最后一个 body = "hello,world {}".format(name) return Response(body)(environ,start_response) # 使用webob 返回的时候要加入 environ 和start_response 两个参数
webob提供了一个装饰器
以前:
from webob import Request, Response def application(environ, start_response): request = Request(environ) name = request.params.get(\'name\', \'unknown\') body = "hello,world {}".format(name) return Response(body)(environ,start_response)
现在:
from webob import Request, Response from webob.dec import wsgify @wsgify def app1(request: Request) -> Response: name = request.params.get(\'name\', \'unknown\') body = "hello,world {}".format(name) return Response(body)
处理小图标问题
@wsgify def app1(request: Request) -> Response: if request.path == \'/favicon.ico\': resp = Response(content_type=\'img/x-icon\') # 小图标的content_type resp.body_file = open(\'./favicon.ico\', \'rb\') # 图片不能使用 utf8来解析 所以图片一定要是rb模式 return resp name = request.params.get(\'name\', \'unknown\') body = "hello,world {}".format(escape(name)) return Response(body)
或者
@wsgify def app1(request: Request) -> Response: if request.path == \'/favicon.ico\': with open(\'./favicon.ico\',\'rb\') as f: resp = Response(body=f.read(),content_type=\'img/x-icon\') return resp name = request.params.get(\'name\', \'unknown\') body = "hello,world {}".format(escape(name)) return Response(body)
怎么处理路由
显然以这种方式来匹配url不靠谱 每次增加一个path都要修改app
@wsgify def app(request: Request) -> Response: if request.path == \'/favicon.ico\': return favicon(request) # 不同的处理放在不同的函数里面 if request.path.endswith() == \'/hello\': return hello(request) if request.path.startswith() == \'/\': return index(request) def index(request): return Response("index page") def hello(request): name = request.params.get(\'name\', \'unknown\') body = "hello,world {}".format(escape(name)) return Response(body)
@wsgify # 使用正则 问题还是没有解决 还是要修改app的代码 def app(request: Request) -> Response: if re.match(r\'^/favicon$\', request.path): return favicon(request) if re.match(r\'^/hello/$\', request.path): return hello(request) if re.match(r\'/$\', request.path): return index(request)
用类来重写application 好处是可以不用再修改app里面的代码
from webob import Response from webob.dec import wsgify import re class Application: def __init__(self): self.routes = [] def route(self, rules, handler): self.routes.append((rules, handler)) @wsgify def __call__(self, request): for rule,handler in self.routes: if re.match(rule,request.path): return handler(request) def index(request): return Response("index page") def hello(request): name = request.params.get(\'name\', \'unknown\') body = "hello,world {}".format(ename) return Response(body) def favicon(request): with open(\'./favicon.ico\', \'rb\') as f: resp = Response(body=f.read(), content_type=\'img/x-icon\') return resp if __name__ == \'__main__\': from wsgiref.simple_server import make_server
application=Application() application.route(r\'/favicon.ico\',favicon) # 注册路由 application.route(r\'/hello\',hello) application.route(r\'/$\',index) server = make_server(\'0.0.0.0\', 9000, application) try: server.serve_forever() except KeyboardInterrupt: server.shutdown()
实现装饰器来注册路由
from webob import Response from collections import namedtuple from webob.dec import wsgify import re Route = namedtuple(\'Route\', (\'pattern\', \'methods\', \'handler\')) class Application: def __init__(self): self.routes = [] def _route(self, rules, methods, handler): self.routes.append(Route(rules, methods, handler)) def router(self, pattern, methods=None): if methods is None: # 不传递该参数表示可以是任意方法 methods = [\'GET\', \'POST\', \'HEAD\', \'OPTION\', \'DELETE\',\'HEAD\',\'PUT\'] def dec(handler): self._route(pattern, methods, handler) return handler return dec @wsgify def __call__(self, request): for route in self.routes: if request.method in route.methods or request.method==route.methods: if re.match(route.pattern, request.path): return route.handler(request) app = Application() @app.router(r\'/\', methods=\'GET\') def index(request): return Response("index page") @app.router(r\'hello\', methods=\'GET\') def hello(request): name = request.params.get(\'name\', \'unknown\') body = "hello,world {}".format(escape(name)) return Response(body) @app.router(r\'favicon\') def favicon(request): with open(\'./favicon.ico\', \'rb\') as f: resp = Response(body=f.read(), content_type=\'img/x-icon\') return resp if __name__ == \'__main__\': from wsgiref.simple_server import make_server server = make_server(\'0.0.0.0\', 9000, app) try: server.serve_forever() except KeyboardInterrupt: server.shutdown()
预先将正则表达式编译好
from webob import Response from collections import namedtuple from webob.dec import wsgify import re Route = namedtuple(\'Route\', (\'pattern\', \'methods\', \'handler\')) class Application: def __init__(self): self.routes = [] def _route(self, rules, methods, handler): self.routes.append(Route(re.compile(rules), methods, handler)) def router(self, pattern, methods=None): if methods is None: methods = [\'GET\', \'POST\', \'HEAD\', \'OPTION\', \'DELETE\', \'HEAD\'] def dec(fn): self._route(pattern, methods, fn) return fn return dec @wsgify def __call__(self, request): for route in self.routes: if request.method in route.methods or request.method == route.methods: if route.pattern.match(request.path): return route.handler(request) app = Application() @app.router(r\'^/$\', methods=\'GET\') def index(request): return Response("index page") @app.router(r\'^/hello$\', methods=\'GET\') def hello(request): name = request.params.get(\'name\', \'unknown\') body = "hello,world {}".format(name) return Response(body) @app.router(r\'favicon\') def favicon(request): with open(\'./favicon.ico\', \'rb\') as f: resp = Response(body=f.read(), content_type=\'img/x-icon\') return resp if __name__ == \'__main__\': from wsgiref.simple_server import make_server server = make_server(\'0.0.0.0\', 9000, app) try: server.serve_forever() except KeyboardInterrupt: server.shutdown()
是不是多单线程 多进程 看容器而不是看应用 gunicorn -w 8 多进程
所以应用不用关心并发问题
如果想要将app一些全局的东西传递进来
from webob import Response from collections import namedtuple from webob.dec import wsgify import re Route = namedtuple(\'Route\', (\'pattern\', \'method\', \'handler\')) class Application: def __init__(self, **options): self.routes = [] self.options =