性能监控实战(全栈性能测试修炼宝典JMeter实战-第九章)
Posted 落花无意溪自流
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能监控实战(全栈性能测试修炼宝典JMeter实战-第九章)相关的知识,希望对你有一定的参考价值。
用户响应时间=服务器响应时间+网络时间
系统性能分析思路
(1)整体系统CPU利用率
(2)内存利用率
(3)磁盘I/O的利用率和延迟
(4)网络利用率
cpu
CPU:top、vmstat、uptime、sar
一般我们期望会期望系统平均可用的CPU不少于20%
JVM自带监控命令:jstat、jmap、Jvisualvm、JConsole
mysql监控工具:Spolight、Monyog、及命令行工具
内存

total used free buffers cached
Mem 物理内存总量 使用的物理内存总量 空闲的物理内存总量 用作内核缓存的内存量 缓存的交换区总量
swap 交换区总量 使用的交换区总量 空闲交换区总量
可用物理内存=Mem(free+buffers+cached)
当物理内存不够时,会使用swap分区,所以性能测试过程中需要关注swap和mem的使用情况。物理内存不够,大量的内存置换到swap空间,可能导致CPU和I/O的瓶颈。
I/O
I/O比较频繁(读或者写)的时候,如果I/O得不到满足会导致应用的阻塞。
需要考虑I/O的TPS、平均I/O数据、平均队列长度、平均服务时间、平均等待时间、IO利用率(磁盘Busy Time%)等指标
总结
很多时候,这些因素彼此之间是相互依赖的,任何一个处于高负载状态,都可能导致其他资源受到影响,如:
(1)大量的网络吞吐量导致占用CPU的资源增大,此时系统要分出部分资源进行软件终端的处理
(2)大量的CPU开销会尝试更多的内存使用
理解并分析当前系统的特点很重要,多数系统对应的应用类型分为以下两种:
(1)IO范畴
大量数据处理的过程,不对CPU及网络发起更多请求。如数据库软件(mysql、Oracle)
(2)CPU范畴
批量处理CPU请求及数学计算的过程。如:webserver、mailserver等。
瓶颈分析
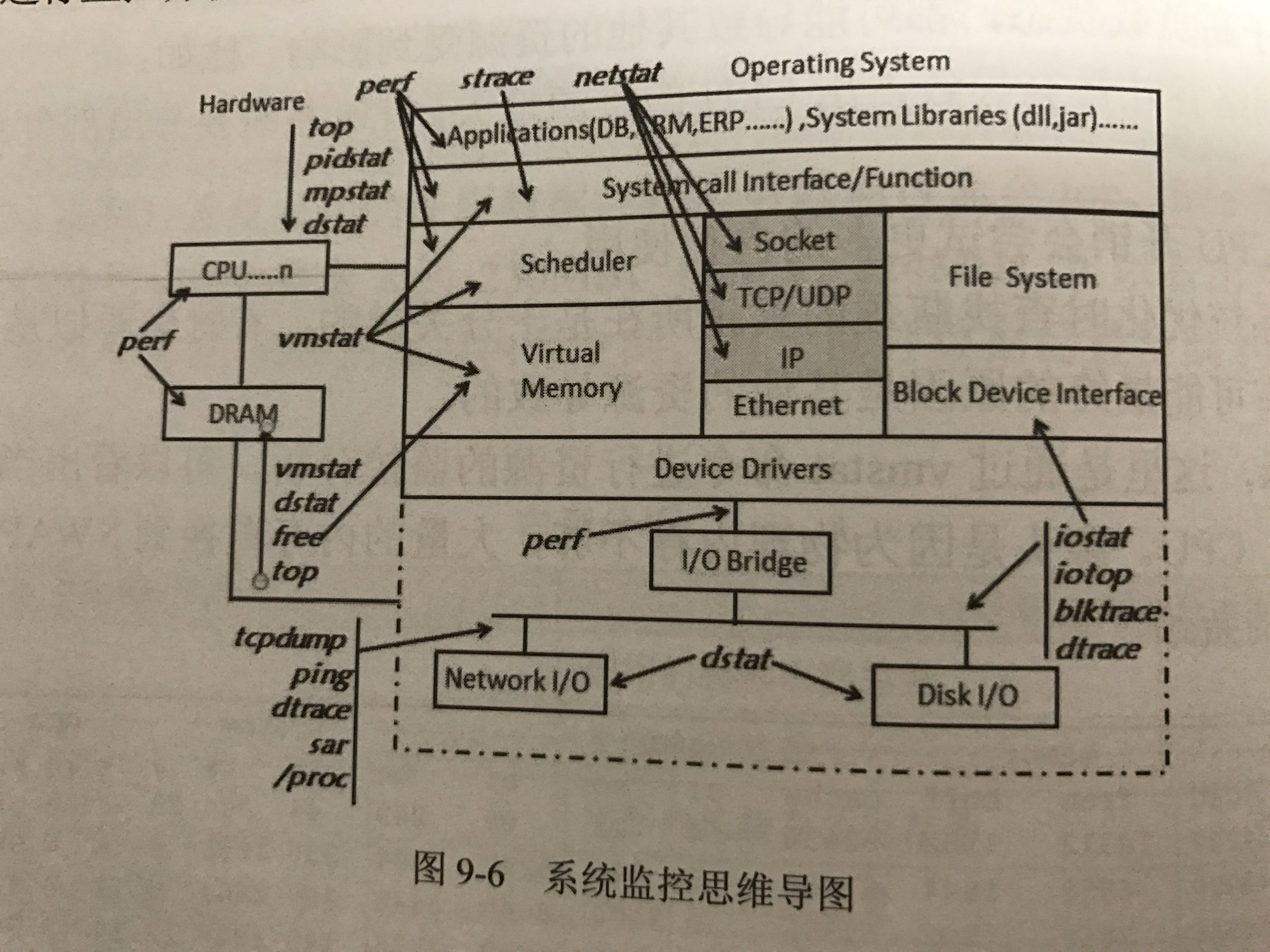
CPU定位分析
CPU利用率大于50%是,需要注意了;大于70%,需要密切关注;高于90%,情况比较严重了。
监控命令:vmstat、sar、dstat、mpstat、top、ps
| 类型 | 度量方法 | 衡量标准 |
| 使用情况 |
1、vmstat 统计1-%id的计数 2、sar -u 统计1-%idle的计数 3、dstat 统计1-%idl的计数 4、mpstat -P ALL 统计%idle的计数 5、ps 统计CPU的计数 |
注意>=50% 告警>=70% 严重>=90% |
| 满载 |
6、vmstat的r计数器> cpu逻辑颗数 7、sar -q ,“runq-sz”>cpu逻辑颗数 8、dstat -q ,“run”>cpu逻辑颗数 |
运行队列大于1时,证明已经有一定的负载了,不过这个计数也不绝对,需要进一步分期其他的资源情况来断定是否CPU已经满负荷运作 |
| 错误 | 9、perf工具捕获处理器的错误信息,需处理器支持 |
安装perf:yum install perf* 需处理器支持 |
内存定位分析
监控命令:vmstat、sar、dstat、free、top、ps等
| 类型 |
度量方法 |
衡量标注 |
| 使用情况 |
1、free 查看使用情况 2、vmstat 3、sar -r 4、ps |
注意>=50% 告警>=70% 严重>=80% |
| 满载 |
5、vmstat的si/so比例辅助swapd和free利用 6、sar -W 查看次缺页数 7、查看内核日志有误OOM机制kill进程 8、dmesg | grep killed |
1、so数值大,且swapd已经占比很高,内存肯定已经饱和 2、sar命令次缺页多意味已经在不定地和swap打交道,证明内存已经饱和 3、但内存不够用会出发内核的OOM机制 |
| 错误 |
9、查看内核有无physical failures 10、通过工具如valgrind等进行检查 |
有计数 |
网络定位分析
监控命令:sar、ifconfig、netstat,以及查看net的dev速率,通过查看发现收发包的吞吐率达到网卡的最大上限,网络数据报文有因为这类原因而引起的丢包、阻塞等现象都证明当前网络可能存在瓶颈。在进行性能测试是为了减小网络的影响,一般我们都在局域网中进行测试执行。
| 类型 | 度量方法 | 衡量标准 |
| 使用情况 |
1、sar -n DEV 的收发计数大于网卡上限 2、ifconfig RX/TX宽带超过网卡上限 3、cat /proc/net/dev的速率超过上限 4、nicstat的util基本满负荷 |
1、收发包的吞吐速率达到网卡上限 2、有延迟 3、有丢包 4、有阻塞 |
| 满载 |
5、ifconfig dropped 有计数 6、netstat -s "segments retransmited"有计数 7、sar -n EDEV,rxdrop/s txdrop/s有计数 |
统计的丢包有计数证明已经满了 |
| 错误 |
8、ifconfig,“errors” 9、netstat -i,RX-ERR TX-ERR 10 sar -n EDEV,rxerr/s txerr/s 11、ip -s link, “errors” |
错误有计数 |
IO定位分析
监控命令:sar、iostat、iotop
| 类型 | 度量方法 | 衡量标准 |
| 使用情况 |
1、iostat -xz,“%util” 2、sar -d,“%util” 3、iotop的利用率很高 4、cat /proc/pid/sched | grep iowait |
注意>=40% 告警>=60% 严重>=80% |
| 满载 |
5、iostat -xnz,“avgqu-sz ”>1 6、iostat await>70 |
IO已经有满载嫌疑 |
| 错误 |
7、dmseg 查看io错误 8、smartctl /dev/sda |
有信息 |
linux系统性能分析思路和实践
系统负载监控分析实践
可以通过uptime、top、w等命令分析
uptime
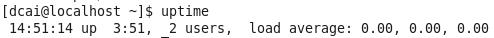
系统时间 up:主机运行时间 当前登录用户数 平均负载:过去1分钟、5分钟、15分钟
(1)运行时间越长,系统越稳定
(2)当前用户数,用w命令可以更详细

(3)系统的平均负载只在特定时间间隔内运行队列中的平均进程数。
一般建议每个CPU内核平均负载不大于0.8;若大于1~3之间,如果系统其他资源都很正常,可接受;若>5,则系统性能有问题
uptime是从文件/proc/loadavg文件里面读取的。统计过去1分钟、5分钟、15分钟平均负载:
[dcai@localhost ~]$ uptime | awk \'{print $(NF-2)}\'
0.00,
[dcai@localhost ~]$ uptime | awk \'{print $(NF-1)}\'
0.02,
[dcai@localhost ~]$ uptime | awk \'{print $NF}\'
0.12
系统监控分析实战
top之外,还有htop、dstat、nmon、glances等
top
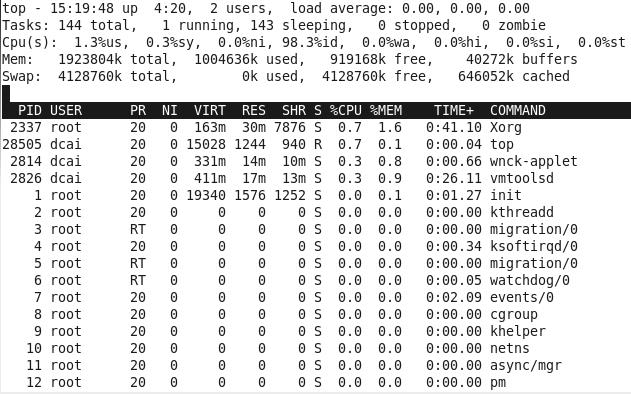
1、第一行:uptime一样
2、第二行:运行状态信息
运行、睡眠、中断、僵死
3、第三行:CPU信息
us:用户占用CPU百分比
sy:系统占用CPU百分比
ni:优先级(用户进程空间内改变过优先级的进程占用CPU百分比),范围-20(最低优先级)~19(最高优先级)
id:空闲CPU百分比
wa:等待输入输出的CPU时间百分比
hi:硬中断占用的CPU百分比
si:软中断占用的百分比
我们比较关注:us、sy、id、wa、hi、si这六个数值
(1)按下键盘1,可以显示每个逻辑CPU的使用情况
(2)id持续过低时,系统迫切需要解决CPU资源问题
(3)wa使用率过高,需要考虑IO性能是否有瓶颈,可以用iostat,sar等命令进一步分析
(3)hi使用率过高,可以分析文件 /proc/interrupts、/proc/irq/pid/smp_affinity、服务irqbalance是否配置、以及CPU的频率设置,通过这些可以帮系统大赛优化系统的硬中断
(4)si:内核通过一种软件的方法(可延迟函数)来模拟硬件的中断模式,通常叫软中断。常见的软中断都和网络有关,长时间的写日志也可能产生软中断。
系统有个进程ksoftirqd来处理软中断,每个CPU都有自己对应的ksoftirqd/n(n为CPU逻辑ID)。但网络出现阻塞的时候,ksoftirqd会出现瓶颈,此时可通过ps命令查看ps aux | grep ksoftirqd

(5)CPU利用率=1-%id
4、第四行+第五行:内存使用情况
buffer和cache的作用是缩短IO系统调用的时间。如果频繁地访问文件都能被命中,很明显会比读取磁盘调用快,磁盘的IO必定会减小。cache的命中率很关键,如果不能命中,对cache而言是极大的浪费,此时应考虑drop cache并提升相应的cache命中率。
5、第六行:进程信息
进程号(PID)、进程所有者(USER)、进程优先级(nice值、NI)、进程使用的虚拟内存(VIRT)、进程使用的实际物理内存(RES)、共享内存(SHR)、CPU占用百分比、进程使用的物理内存百分比(%MEM)、进程使用的CPU时间总计(1/100秒,TIME+)、命令行
(1)top显示的是进程信息,要看线程级,可用ps -ef
(2)TIME+表示的是进程使用的CPU时间总计,不是进程的存活时间
(3)默认不会显示进程分布在那颗CPU上,如想分析CPU对应的应用程序,可修改top默认配置,添加字段Last used CPU即可。
(4)H:top配置帮助页
d:刷新间隔
f:添加进程字段显示列
1:显示平均/各颗CPU的利用率信息
W:保存配置信息
6、top参数
-d 批处理模式
-c 命令/程序名 触发
-d 设置延迟间隔(刷新频率)
-n 设置迭代数量(退出前监控次数)
-p 监控特定的PID
-u或-U: 用户名 或 UID
top -b -d 1 -n 3 > top.log
tomcat监控之probe
目前流行的中间件有tomcat、jetty、Jboss、weblogic、WebSphere等,基本原理相似,都遵循servlet规范。对容器的监控实际上是对JVM的监控,容器运行在JVM纸上。JVM的监控分析工具有jvisualVM、jconsole、jprofiler、zabbix、nagios、cacti等。下面介绍tomcat监控工具probe,probe只需要一个war包就可以完成监控任务,完全不用设置,下面是tomcat常规监控项:
| 类别 | 计数器 | 描述 |
| tomcat | JVM内存 | 关注GC回收频率,Full GC次数越少越好 |
| 最大线程数 | 线程池连接数长期大于80%以上,建议优化 | |
| 数据库连接数 | 活动连接数长期大于80%以上,建议优化连接池 | |
|
请求数 请求状态 |
线程数,线程状态,大量blocked状态线程可以dump线程栈信息进行优化 |
probe
安装probe之后,打开浏览器访问probe:127.0.0.1:8089/probe
线程池的监控:
current_threads_count:线程池中ready好的数量,我的在运行状态,我的在等待状态
current_threads_busy:当前活动状态的线程数量,正处在活动状态
max_threads:最大线程池数量
我们需要关注current_threads_count和current_threads_busy是否接近max_threads,如果是,则需要加大max_threads数量;如果服务器硬件支撑不了更多线程数,就需要更换更强的硬件或做集群来分担负载。
JVM监控
除了probe之外,自带监控工具也比较好用
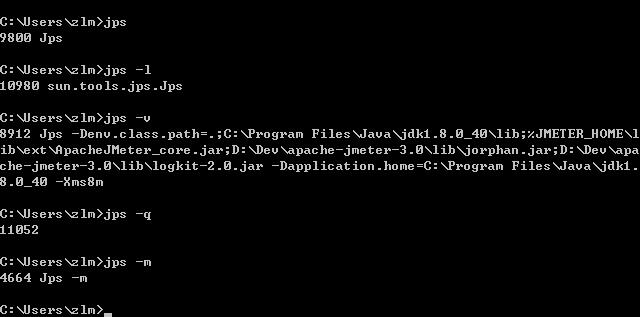
jps
jps是jdk提供的一个查看当前java进程的小工具, 可以看做是JavaVirtual Machine Process Status Tool的缩写。非常简单实用。
jps –l:输出主类或者jar的完全路径名
jps –v :输出jvm参数
jps –q :仅仅显示java进程号
jps -m : 输出main method的参数
jps -mlv 10.134.68.173 (如果需要查看其他机器上的jvm进程,需要在待查看机器上启动jstatd。)
jstat
FGC(Full gc)会暂停用户相应,也就是不处理用户请求,等待Full gc完成后响应用户请求,这个等待时间过大会影响用户体验,所以Full gc是JVM调优的重点
jstat -gcutil [PID]
jmap
分析程序内存占用其实是分析堆(Heap)内存,堆快照使用jamp获取
典型获取方式:
jmao dump:format=b,file=d:\\heap.hprof [pid]
heap.hprof是快照文件,可以使用JVisualvm来打开
JVisualvm
JDK自带的JVM可视化监控工具
在%JAVA_HOME%\\bin下找到 ,双击启动
,双击启动
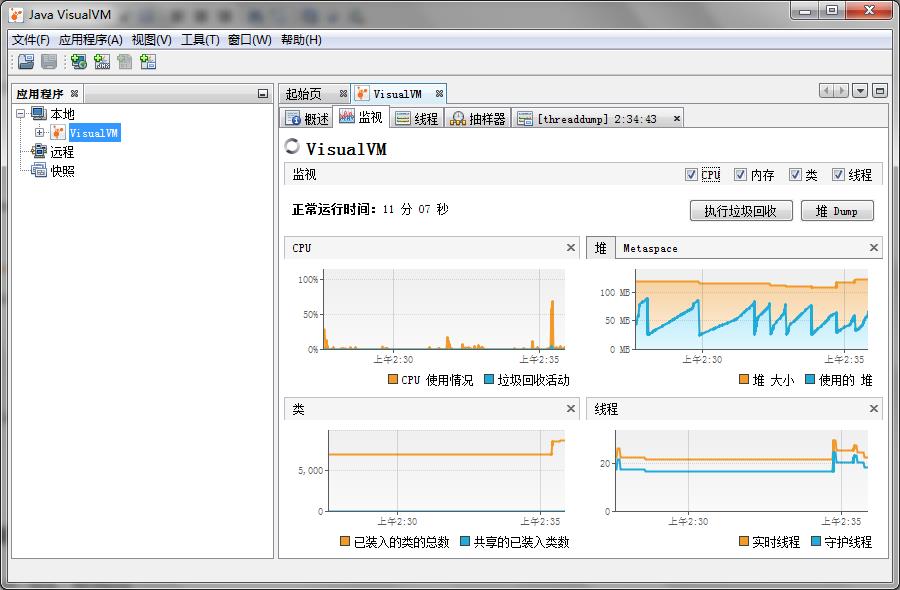
下图:可以做堆Dump操作,查看堆内存明细。堆的回收曲线能够直观反映堆内存回收频率,是否有内存溢出等问题。
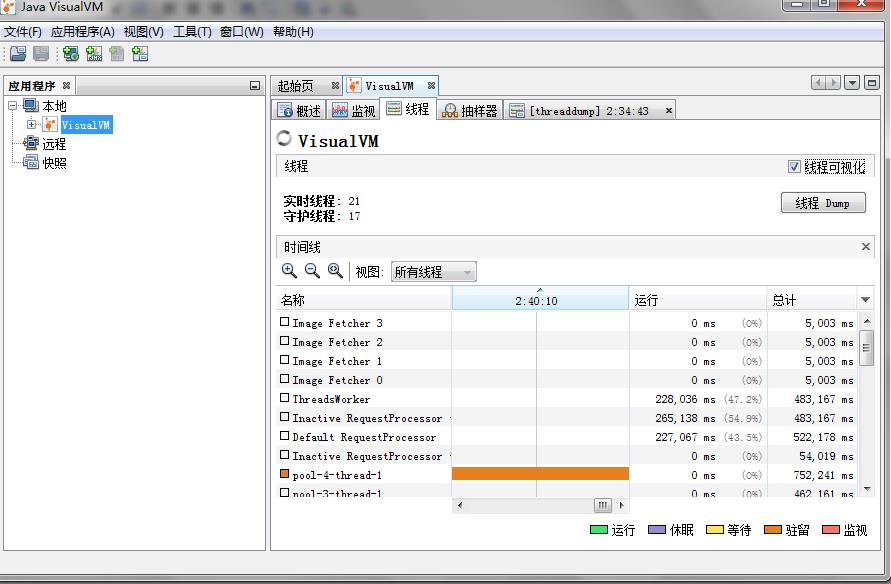
下图:点击“线程Dump”导出JVM当前线程栈信息,通过分析这些信息来定位到程序问题
总结:对于Java的应用来讲,JVM的性能反映了Java程序的性能,JVM的监控分两大类,一是堆内存,二是线程;从堆内存可以分析大对象与内存溢出等问题,从线程状态及线程信息分析出低效程序,解决的是CPU资源占用的问题。
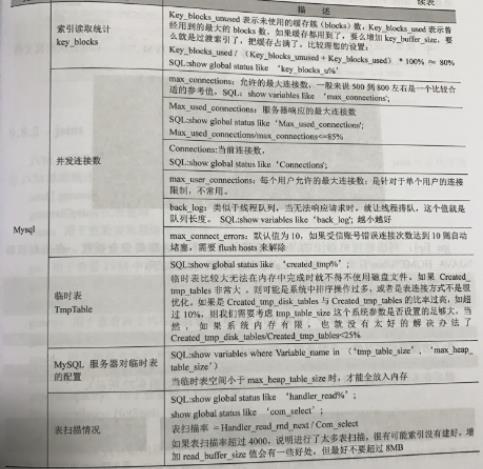
MySql监控之MONyog
MySql监控方法:官方客户端、命令行、SQL、MONyog
1、下载MONyog.地址:https://www.webyog.com/
2、安装完成后,启动MONyog进行连接配置
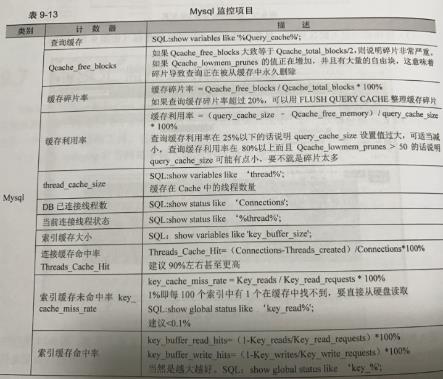
3、MONyog绝大多数指标都进行了详细说明
最后
当性能测试环境复杂的情况下,可以借助zabbix、nagios、cacti等监控平台
以上是关于性能监控实战(全栈性能测试修炼宝典JMeter实战-第九章)的主要内容,如果未能解决你的问题,请参考以下文章