看Lucene源码必须知道的基本概念
Posted 编程一生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了看Lucene源码必须知道的基本概念相关的知识,希望对你有一定的参考价值。
终于有时间总结点Lucene,虽然是大周末的,已经感觉是对自己的奖励,毕竟只是喜欢,现在的工作中用不到的。自己看源码比较快,看英文原著的技术书也很快。都和语言有很大关系。虽然咱的技术不敢说是部门第一的,说到日语和英语,倒是无人能出其右的。额~~,一个做技术的,感觉自己好弱啊。对语言,只是天赋而已。对技术,却是痴迷。虽然有人跟我说我不做管理白瞎了我这个人儿。但是我就一心想做技术,如果到了40岁,做技术没人要的话。我就去硅谷编代码去,毕竟硅谷的同事都说我技术挺好的,相信找个技术活儿还是不成问题的。话说现代人确实是比古人努力多了,那凿壁偷光的匡衡也没近视,现代不带眼镜才是稀有。多情应笑我早生华发的苏轼写《念奴娇》的时候至少也40岁了吧,现代却都是少白头。上班的人不易,公司也不易。所以之前公司晚上8点之后能打车报销的时候我也没打过车,加班餐也不怎么吃。毕竟我们乐视是一个有理想的公司,大家都是在为理想努力着。乐视不仅是一个生态的企业,而且是个讲求创新的企业,在人工智能方面也是一直领先和执着的。我其实挺看好乐视的前景的,就是,实在话,互联网技术上比BAT差距挺大的。
下面的一些基本概念不但有助于看源码,在使用像solr这样的搜索引擎框架的时候还可以知道自己的配置都做了些什么事情。我在定义这些概念的时候也都有自己的理解和思考。
反向索引:全文索引将半结构化或者全文数据进行结构化,保存为字符串到文件的映射。因为这是一个文件到字符串的反向过程,被称为反向索引。
倒排表:上面说的字符串到文件的映射,这个文件实际上在lucene中是一个文档链表,称为倒排表(Posting List)。
分词组件(Tokenizer):在调用lucene建索引的时候,要先new一个Field,然后添加到Document里去。这个Field要成为索引的第一步就是进入分词组件进行分词:Tokenizer主要做了三件事1>分成一个个单独的单词 2>取出标点符号 3>去除停用词(停用词是没有实际意义的词,如:的,儿。每一种语言的分词组件,都有自己的停用词库)
词元(Token):经过分词组件的三步处理,得到的结果就是词元了。
Stemming:对于英语来说,词元的下一步处理是通过语言处理组件Linguistic Processor来将其变成小写,然后通过某种算法将其变成词根,比如:复数形式变成词根形式,进行时和完成时变成词根形式(如果有不知道什么是词根的童鞋,可以去问英语老师哦~~)。这种变化过程叫做Stemming。
Lemmatization:这个也是应用于外语的,如果你做的是中文搜索,在配置的时候,发现你的搜索引擎走了这一步,你其实是在无用功哦~~。因为在英语中,有一些复数啊,完成时啊,进行时啊 变化是不规则的,不能通过算法来解决,就要基于词典了。这种基于词典的词根化过程叫做Lemmatization。但是基于算法的计算总归要快于基于匹配的算法,所以有些其实用Lemmatization也能达到最终效果,但是最好用Stemming。
词(Term):经过上面词根化后的词成为Term。
这里值得注意的是,英语中不管输入一个单词的什么形式,有了词根化,都可以把带有各种形式的都搜索出来。汉语虽然没有这一步,但是汉语中有近义词的概念,它的实现和Lemmatization大体相同,都是基于词典的。但是对它的处理要采用自己配置过滤器的方式。
索引组件(Indexer):Term要通过Indexer来最终添加到倒排表中。Indexer主要做了两件事:1>排序 2>合并。最后得到的倒排索引是一个大链表,链表里的每个Term都是一个小链表,链表里存了在各个文档中出现的词频。结构大体是下图的样子:

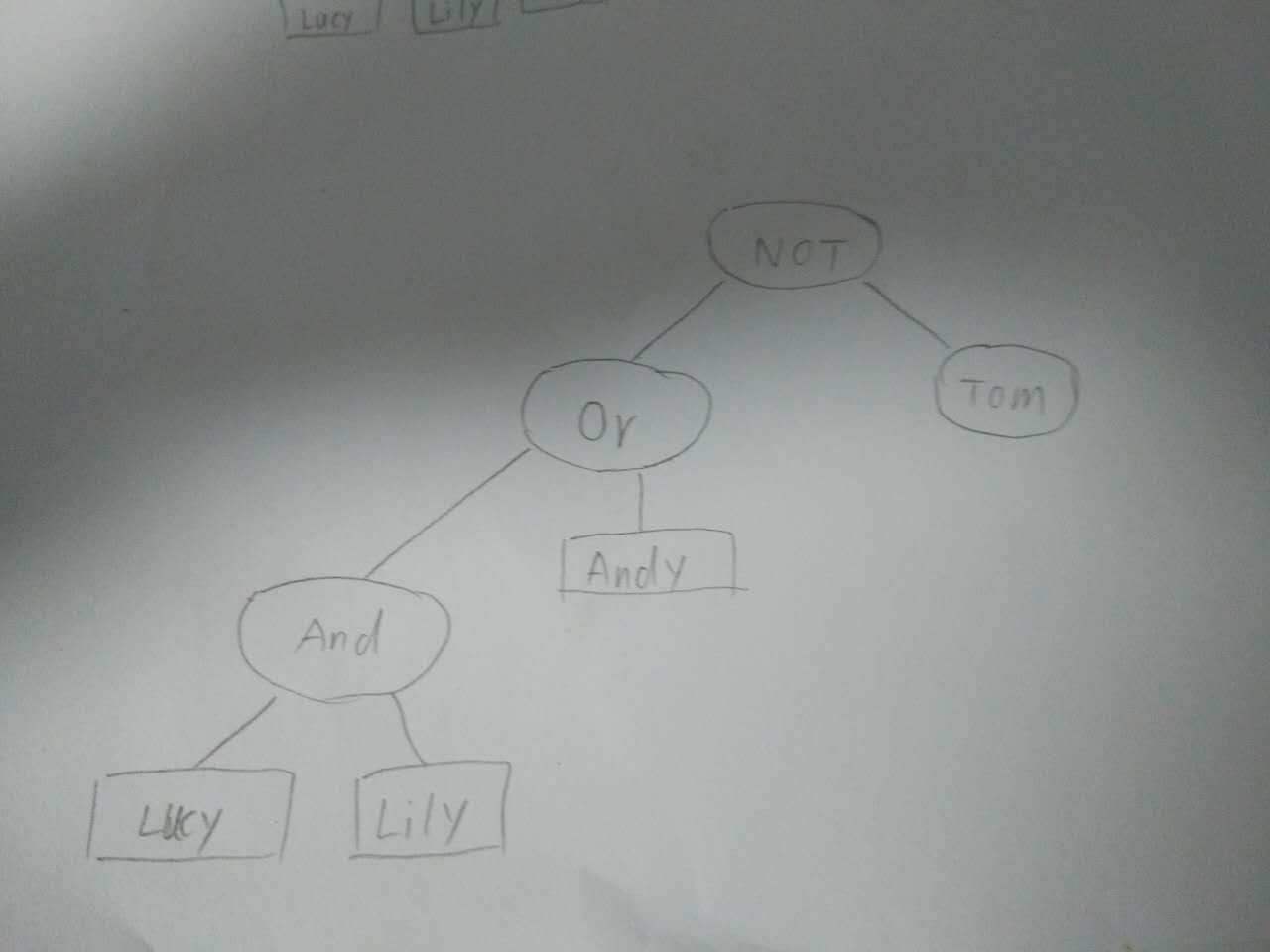
语法树:我们输入的查询内容是有语法的。在汉语中这种语法体现的不明显,但在英文中,比如 Lucy AND Lily OR Andy Not Tom就会形成一个由关键词和普通词组成的语法树,当然语法树中的单词也是需要词根化的。之后,将包含Lucy Lily的链表进行取交集(AND操作),得到文档再和包含Andy的合并(OR 操作),再将此链表与包含Tom的链表进行差(NOT操作),最后对得到的链表进行相关度排序,得到结果,语法树的逻辑上大概长成下面的样子:
将上面几个简单的概念串联起来其实就是索引和搜索的过程了。
索引过程:全文数据经过语法分析和语言处理形成词(Term),词再排序和合并成倒排链表进行存储(可以存内存,也可以持久化到硬盘)
搜索过程:将用户输入经过语法分析和语言处理形成词(Term),通过语法分析得到语法树,找出所有包含语法树的词的文档,进行交,并,差操作得到结果文档,相关度排序得到最终结果。

这是一个索引的文件的磁盘存储截图。文件夹下所有文件构成了lucene的索引(注意后面的文件大小)。索引中又有些必须知道的概念。
段(Segment):一个索引可以包含多个段,之间是独立的,可以合并。具有相同前缀的文件属于同一个段,图中显示了_1s和_b两个段。segments.gen和segments_1是段的元数据文件(保存属性的)
文档(Document)是建索引的基本单位,存在段中。新添加的文档单独保存在新生成的段中,随着段的合并可以将不同的文档合并到同一个段中。
segments_N文件:保存了此索引包含多少个Segment,每个段包含多少Document.
.fnm文件:保存了此段包含了多少field,每个field的名称及索引方式
.fdx,.fdt文件:保存了此段包含的Document, 每篇Document里的每个field存了什么。
.tvx,.tvd,.tvf文件:保存了此段包含多少Document,每篇包含多少Field,每个field包含了多少term,每个term具体信息。
.tis,.tii文件:保存了此段的Term按字典顺序的排序。
.frq文件:保存了倒排表,就是每个Term的文档ID列表。
.prx文件:保存了倒排表中每个词在包含词的文档中的位置
困了,碎觉,明天还要早起给男票做早餐~~
如需转载,请注上我的原文链接:http://www.cnblogs.com/xiexj/p/6679865.html 谢谢哦~~
以上是关于看Lucene源码必须知道的基本概念的主要内容,如果未能解决你的问题,请参考以下文章