HBase结合MapReduce批量导入(HDFS中的数据导入到HBase)
Posted ahu-lichang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase结合MapReduce批量导入(HDFS中的数据导入到HBase)相关的知识,希望对你有一定的参考价值。
HBase结合MapReduce批量导入
1 package hbase; 2 3 import java.text.SimpleDateFormat; 4 import java.util.Date; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.hbase.client.Put; 8 import org.apache.hadoop.hbase.mapreduce.TableOutputFormat; 9 import org.apache.hadoop.hbase.mapreduce.TableReducer; 10 import org.apache.hadoop.hbase.util.Bytes; 11 import org.apache.hadoop.io.LongWritable; 12 import org.apache.hadoop.io.NullWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Counter; 15 import org.apache.hadoop.mapreduce.Job; 16 import org.apache.hadoop.mapreduce.Mapper; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 19 20 public class BatchImport { 21 static class BatchImportMapper extends 22 Mapper<LongWritable, Text, LongWritable, Text> { 23 SimpleDateFormat dateformat1 = new SimpleDateFormat("yyyyMMddHHmmss"); 24 Text v2 = new Text(); 25 26 protected void map(LongWritable key, Text value, Context context) 27 throws java.io.IOException, InterruptedException { 28 final String[] splited = value.toString().split("\\t"); 29 try { 30 final Date date = new Date(Long.parseLong(splited[0].trim())); 31 final String dateFormat = dateformat1.format(date); 32 String rowKey = splited[1] + ":" + dateFormat;//设置行键:手机号码+日期时间 33 v2.set(rowKey + "\\t" + value.toString()); 34 context.write(key, v2); 35 } catch (NumberFormatException e) { 36 final Counter counter = context.getCounter("BatchImport", 37 "ErrorFormat"); 38 counter.increment(1L); 39 System.out.println("出错了" + splited[0] + " " + e.getMessage()); 40 } 41 }; 42 } 43 44 static class BatchImportReducer extends 45 TableReducer<LongWritable, Text, NullWritable> { 46 protected void reduce(LongWritable key, 47 java.lang.Iterable<Text> values, Context context) 48 throws java.io.IOException, InterruptedException { 49 for (Text text : values) { 50 final String[] splited = text.toString().split("\\t"); 51 52 final Put put = new Put(Bytes.toBytes(splited[0]));//第一列行键 53 put.add(Bytes.toBytes("cf"), Bytes.toBytes("date"), 54 Bytes.toBytes(splited[1]));//第二列日期 55 put.add(Bytes.toBytes("cf"), Bytes.toBytes("msisdn"), 56 Bytes.toBytes(splited[2]));//第三列手机号码 57 // 省略其他字段,调用put.add(....)即可 58 context.write(NullWritable.get(), put); 59 } 60 }; 61 } 62 63 public static void main(String[] args) throws Exception { 64 final Configuration configuration = new Configuration(); 65 // 设置zookeeper 66 configuration.set("hbase.zookeeper.quorum", "hadoop0"); 67 // 设置hbase表名称 68 configuration.set(TableOutputFormat.OUTPUT_TABLE, "wlan_log");//先在shell下创建一个表:create \'wlan_log\',\'cf\' 69 // 将该值改大,防止hbase超时退出 70 configuration.set("dfs.socket.timeout", "180000"); 71 72 final Job job = new Job(configuration, "HBaseBatchImport"); 73 74 job.setMapperClass(BatchImportMapper.class); 75 job.setReducerClass(BatchImportReducer.class); 76 // 设置map的输出,不设置reduce的输出类型 77 job.setMapOutputKeyClass(LongWritable.class); 78 job.setMapOutputValueClass(Text.class); 79 80 job.setInputFormatClass(TextInputFormat.class); 81 // 不再设置输出路径,而是设置输出格式类型 82 job.setOutputFormatClass(TableOutputFormat.class); 83 84 FileInputFormat.setInputPaths(job, "hdfs://hadoop0:9000/input");//将手机上网日志文件上传到HDFS中的input文件中 85 86 job.waitForCompletion(true); 87 } 88 }
在eclipse中将上面代码运行成功后,就可以去HBase shell中查看结果:
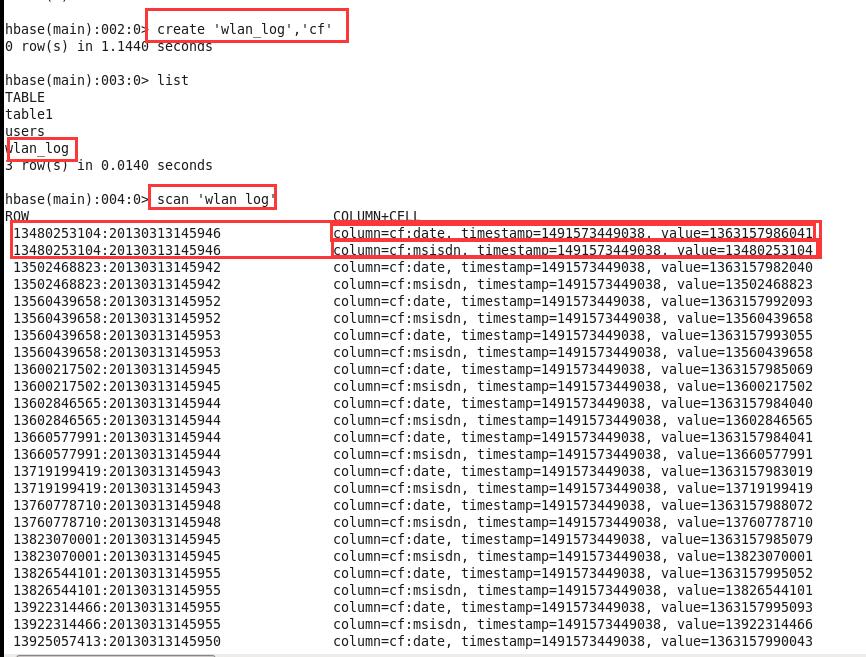
以上是关于HBase结合MapReduce批量导入(HDFS中的数据导入到HBase)的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop之——HBASE结合MapReduce批量导入数据