理解函数式编程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解函数式编程相关的知识,希望对你有一定的参考价值。
相信大家平时或多或少听过不少关于“函数式编程” (FP)相关的词语,有些Geek经常吹捧函数式的优点或者特性比如:纯函数无副作用、不变的数据、高阶函数、流计算模式、尾递归、柯里化等等,再加上目前的函数式理论越来越多的应用于工程中,OCaml,clojure, scala等FP语言日渐火爆。本编文章,笔者准备带领大家深入理解函数式编程的相关理论概念。
定义
首先引用维基百科对函数式编程的解释:在计算机科学里,函数式编程是一种编程范式,它将计算描述为表达式求值并避免了状态和数据改变。函数式编程里面的“函数”指的是数学函数,数学函数和我们平时工作中遇到的编程函数有什么区别呢?
编程函数和数学函数
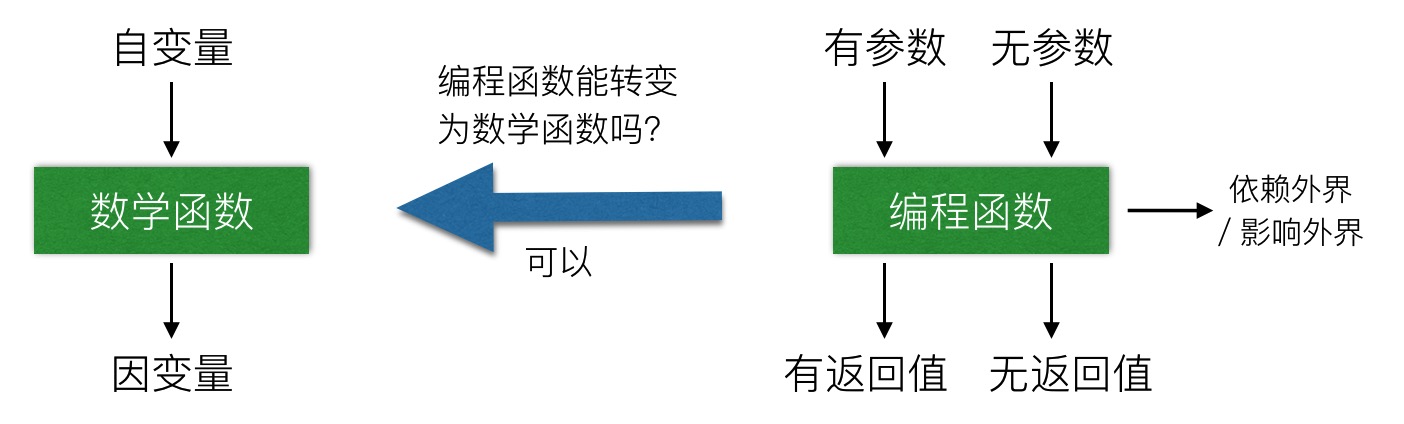
从上图不难发现:数学函数的特点是对于每一个自变量,存在唯一的因变量与之对应。而编程函数的特点是参数和返回值都不是必须的,函数可能依赖外界或者影响外界。那么编程函数能否转换成数学函数,或者说我们的编程函数能否变成“纯函数”?
如何转换?
对于任何一个编程函数,需要满足下面3个条件,即可转换成纯数学函数。
每个函数必须包含输入参数(作为自变量)
每个函数必须有返回值(作为因变量)
无论何时,给定参数调用函数时,返回值必须一致。
命令式和函数式的区别
以快排为例,过程式的版本,可以发现重视过程:
void Solution::quickSort(vecotr<int> &nums, int left, int right)
{ int i = left, j = right; int pviot = nums[(i + j) >> 1]; while (i <= j)
{ while (nums[i] < pviot)
i ++; while (nums[j] > pviot)
j --; if (i <= j)
{
swap(nums[i], nums[j]);
i ++;
j --;
}
} if (left < j)
quickSort(nums, left, j); if (right > i)
quickSort(nums, i, right);
}Haskell的快排实现,可以发现更加注重结果:
quickSort :: (Ord a) => [a] -> [a]-- If input list is emptyquickSort [] = []-- List isn‘t emptyquickSort (x : xs) = let smallerSorted = quickSort (filter (<= x) xs) biggerSorted = quickSort (filter (> x) xs) in smallerSorted ++ [x] ++ biggerSorted
所有的命令式语言都被设计来高效地使用冯诺依曼体系结构的计算机。实际上,最初的命令式语言的目的就是取代汇编语言,对机器指令进行进一步抽象。因此,命令式语言带有强烈的硬件结构特征。命令式语言的核心特性有:模拟存储单元的变量、基于传输操作的赋值语句,以及迭代形式的循环运算。命令式语言的基础是语句(特别是赋值),它们通过修改存储器的值而产生副作用(side effect)的方式去影响后续的计算。
函数式语言设计的基础是Lambda表达式,函数式程序设计把程序的输出定义为其输入的一个数学函数,在这里没有内部状态,也没有副作用。函数式语言进行计算的主要是将函数作用与给定参数之上。函数式语言没有命令式语言所必需的那种变量,可以没有赋值语句,也可以没有循环。一个程序就是函数定义和函数应用的说明;一个程序的执行就是对函数应用的求值。
高阶函数
高阶函数实际上就是函数的函数,它是所有函数式语言的性质。函数式语言中,函数作为第一等公民,这也意味着你像定义或调用变量一样去定义或调用函数。可以在任何地方定义,在函数内或函数外,可以将函数作为参数或者返回值。在数学和计算机科学中,高阶函数是至少满足下列一个条件的函数:
接受一个或多个函数作为输入
输出一个函数
在数学中它们也叫做算子(运算符)或泛函。微积分中的导数就是常见的例子,因为它映射一个函数到另一个函数。
以Haskell里面的Map和Filter为例子。
-- 比如我们有一组List,[1,2,3,4,5],我需要将他们都平方map (\x->x^2) [1,2,3,4,5]-- 找到大于3的所有数filter (>3) [1,2,3,4,5]
递归、尾调用和尾递归
由于变量不可变,纯函数编程语言里面无法实现循环,这是因为for循环使用可变的状态作为计数器,而while循环或者do-while循环需要可变的状态作为跳出循环的条件。因此函数式语言里面只能用递归来解决迭代问题,这使得函数式编程严重依赖递归。以阶乘函数的实现为例子:
factorial :: Int -> Intfactorial 0 = 1factorial n = n * factorial (n - 1)
这个时候的程序调用内部的计算表现形式为线性扩张(先扩张,后收缩):

回顾下函数调用的过程:
1,调用开始前,调用方(或函数本身)会往栈上压相关的数据,参数,返回地址,局部变量等。
2,执行函数
3,清理栈上相关的数据,返回
在函数 A 执行的时候,如果在第二步中,它又调用了另一个函数 B,B 又调用 C.... 栈就会不断地增长不断地装入数据,当这个调用链很深的时候,栈很容易就满 了,这就是一般递归函数所容易面临的大问题。稍有不慎,就会有爆栈的危险(比如经典的斐波那契数列,树形扩张)。
尾调用:指某个函数的最后一步是调用另一个函数。
尾递归:函数尾部调用自身。大部分函数式编程语言比如Scheme、Haskell里面要求实现尾递归优化,编译器会在编译期间会将尾递归优化为循环。
将上述普通递归函数用尾递归的方式重写:
factorial :: Int -> Intfactorial n = factiter 1 1 nfactiter :: Int -> Int -> Int -> Intfactiter product counter maxCount | counter > maxCount = product | otherwise = factiter (* counter product) (+ counter 1) maxCount
这个时候的程序调用内部的计算表现形式如图,内存消耗从O(n)到O(1):

偏函数应用(Partial application)与柯里化(currying)
偏函数解决这样的问题:如果我们有函数是多个参数的,我们希望能固定其中某几个参数的值。以Python为例子:
from functools import partialdef foo (a, b, c): return a + b + c foo21 = partial (foo, b=21) foo21(a = 1, c = 3) # => 25
函数式语言的currying特性来自于lambda calculus,lambda calculus只支持单参函数,但它可以返回一个函数来接受第二个参数。
关于柯里化,我们可以这么理解:柯里化就是一个函数在参数没给全时返回另一个函数,返回的函数的参数正好是余下的参数。比如:你制定了x和y, 如2的3次方,就返回8, 如果你只制定x为2,y没指定, 那么就返回一个函数:2的y次方, 这个函数只有一个参数:y。
它的 2 大特性:
匿名函数
每个函数只有1个参数
以javascript为例子,一个函数接受2个参数,返回它们的和:
function add (a, b) {
return a + b;}add(3, 4); returns 7采用柯里化后,变成一个函数接受1个参数,返回一个接受另外一个参数并且返回它们和的的函数:
function add (a) {
return function (b) {
return a + b;
}}// 调用add(3)(4);var add3 = add(3);add3(4);流计算模式
这个概念来自于SICP里面的第3章,可以理解为unix里面的pipline,使用它可以让代码具有申明式的语义化、模块化,更加富有表现力。
以javascript为例,设计好的风格的代码表现如下:
getAsyncStockData()
.filter(quote => quote.price > 30)
.map(quote => quote.price)
.forEach(price => console.log(`Prices higher than $30: ${price}`));实用建议
函数中不使用全局变量和IO,有入参和返回值
使用map and reduce对列表进行操作,不使用循环迭代
声明式,而不是命令式
不改变原始数据
以上是关于理解函数式编程的主要内容,如果未能解决你的问题,请参考以下文章