LINUX内核分析第二周学习总结:操作系统是如何工作的?
Posted potter的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LINUX内核分析第二周学习总结:操作系统是如何工作的?相关的知识,希望对你有一定的参考价值。
马启扬 + 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
一、函数调用堆栈
1. 小结:计算机是怎样工作的
三个法宝:存储程序计算机、函数调用堆栈、中断机制。- 存储程序计算机工作模型,计算机系统最最基础性的逻辑结构。
- 函数调用堆栈,高级语言得以运行的基础,只有机器语言和汇编语言的时候堆栈机制对于计算机来说并不那么重要,但有了高级语言及函数,堆栈成为了计算机的基础功能。(函数参数传递机制和局部变量存储)
- 中断,多道程序操作系统的基点,没有中断机制程序只能从头一直运行结束才有可能开始运行其他程序。
2. 堆栈
- 堆栈是C语言程序运行时必须的一个记录调用路径和参数的空间。
- 函数条用框架
- 传递参数
- 保存返回地址
- 提供局部变量空间...
- C语言编译器对堆栈的使用有一套的规则
-
了解对站存在的目的和编译器对堆栈使用的规则是理解操作系统一些关键性代码的基础。
-
堆栈相关寄存器:
esp:堆栈指针(stack pointer),指向系统栈最上面一个栈帧的栈顶 ebp: 基址指针(base pointer),指向系统栈最上面一个栈帧的底部 cs:eip:指令寄存器(extended instruction pointer),指向下一条等待执行的指令地址 -
ebp在C语言中用作记录当前函数调用基址。
3. 堆栈操作
- push:以字节为单位将数据(对于32位系统可以是4个字节)压入栈,从高到低按字节依次将数据存入ESP-1、ESP-2、ESP-3、ESP-4的地址单元。
- pop: 过程与PUSH相反。
- call: 用来调用一个函数或过程,此时,下一条指令地址会被压入堆栈,以备返回时能恢复执行下条指令。
- leave:当调用函数调用时,一般都有这两条指令
pushl %ebp和movl %esp,%ebp,leave是这两条指令的反操作。 - ret: 从一个函数或过程返回,之前call保存的下条指令地址会从栈内弹出到EIP寄存器中,程序转到CALL之前下条指令处执行。
call指令的两个作用:
- 将下一条指令的地址A保存在栈顶
- 设置eip指向被调用程序代码开始处4. 函数堆栈框架
-
执行call function
cs:eip原来的值指向call下一条指令,该值被保存到栈顶 cs:eip的值指向function的入口地址 -
进入function
pushl %ebp //意为保存调用者的栈帧地址 movl %esp, %ebp //初始化function的栈帧地址 然后函数体中的常规操作 -
退出function
movl %ebp,%esp popl %ebp ret
5. 注:函数调用约定
- 函数调用约定包括传递参数的顺序,谁负责清理参数占用的堆栈等。
| 函数调用约定 | 参数传递顺序 | 负责清理参数占用的堆栈 |
|---|---|---|
| __pascal | 从左到右 | 调用者 |
| __stdcall | 从右到左 | 被调函数 |
| __cdecl | 从右到左 | 调用者 |
-
调用函数的代码和被调函数必须采用相同的函数的调用约定,程序才能正常运行。
Windows中C/C++程序的缺省函数调用约定是__cdecl linux中gcc默认用的规则是__stdcall -
编译器在进入函数时,会将寄存器里的参数存入堆栈指定位置。参数和局部变量一样在堆栈中有一席之地。参数可以被理解为由调用函数指定初值的局部变量。
二、函数堆栈框架
-
一级调用
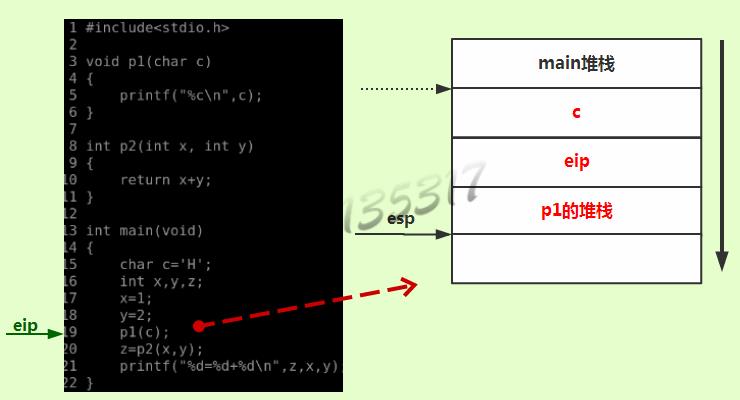
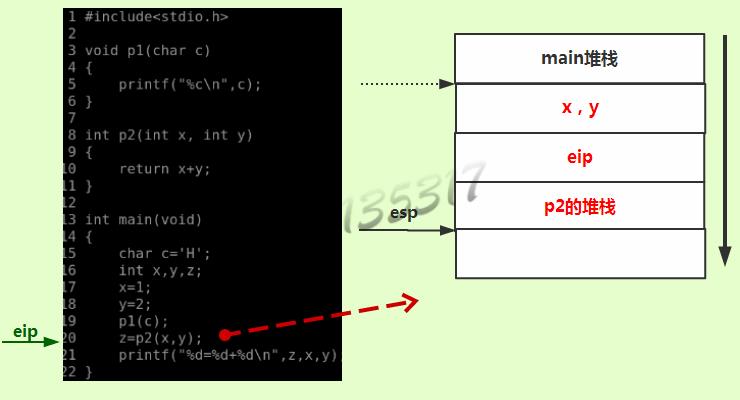
-
二级调用

-
调用函数时c语言会利用堆栈来做一个函数调用框架。压入栈中的每一个函数都有一个帧栈,每个帧栈都以ebp为分界线。(如下图)
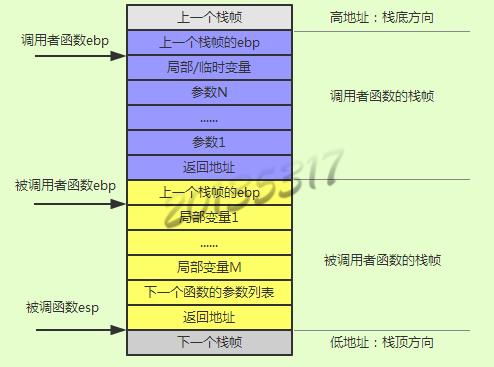
三、C代码中嵌入汇编代码的写法
0. 内嵌汇编语法
__asm__(汇编语句模板: 输出部分: 输入部分: 破坏描述部分)- 各部分使用“:”格开,汇编语句模板必不可少,其他三部分可选,如果使用了后面的部分,而前面部分为空,也需要用“:”格开,相应部分内容为空。
1. 汇编语句模板
汇编语句模板由汇编语句序列组成,语句之间使用“;”、“\n”或“\n\t”分开。指令中的操作数可以使用占位符引用C语言变量,操作数占位符最多10个,名称如下:%0,%1,…,%9。- 指令中使用占位符表示的操作数,总被视为long型(4个字节),但对其施加的操作根据指令可以是字或者字节,当把操作数当作字或者字节使用时,默认为低字或者低字节。
- 对字节操作可以显式的指明是低字节还是次字节。方法是在%和序号之间插入一个字母,“b”代表低字节,“h”代表高字节,例如:%h1。
2. 输出部分
输出部分描述输出操作数,不同的操作数描述符之间用逗号格开,每个操作数描述符由限定字符串和C语言变量组成。- 每个输出操作数的限定字符串必须包含“=”表示他是一个输出操作数。
- 描述符字符串表示对该变量的限制条件,这样GCC就可以根据这些条件决定如何分配寄存器,如何产生必要的代码处理指令操作数与C表达式或C变量之间的联系。
3. 输入部分
输入部分描述输入操作数,不同的操作数描述符之间使用逗号格开,每个操作数描述符由限定字符串和C语言表达式或者C语言变量组成。4. 破坏描述部分
破坏描述符用于通知编译器我们使用了哪些寄存器或内存,由逗号格开的字符串组成,每个字符串描述一种情况,一般是寄存器名;除寄存器外还有“memory”。5. 限制字符
限制字符有很多种,有些是与特定体系结构相关,它们的作用是指示编译器如何处理其后的C语言变量与指令操作数之间的关系。 | 常用限制字符 | ||
|---|---|---|
| 分类 | 限定符 | 描述 |
| 通用寄存器 | “a” | 将输入变量放入eax |
| “b” | 将输入变量放入ebx | |
| “c” | 将输入变量放入ecx | |
| “d” | 将输入变量放入edx | |
| “s” | 将输入变量放入esi | |
| “d” | 将输入变量放入edi | |
| “q” | 将输入变量放入eax,ebx,ecx,edx中的一个 | |
| “r” | 将输入变量放入通用寄存器,也就是eax,ebx,ecx,edx,esi,edi中的一个 | |
| “A” | 把eax和edx合成一个64 位的寄存器(use long longs) | |
| 内存 | “m” | 内存变量 |
| “o” | 操作数为内存变量,但是其寻址方式是偏移量类型,也即是基址寻址,或者是基址加变址寻址 | |
| “V” | 操作数为内存变量,但寻址方式不是偏移量类型 | |
| “ ” | 操作数为内存变量,但寻址方式为自动增量 | |
| “p” | 操作数是一个合法的内存地址(指针) | |
| 寄存器或内存 | “g” | 将输入变量放入eax,ebx,ecx,edx中的一个或者作为内存变量 |
| “X” | 操作数可以是任何类型 | |
| 立即数 | “I” | 0-31之间的立即数(用于32位移位指令) |
| “J” | 0-63之间的立即数(用于64位移位指令) | |
| “N” | 0-255之间的立即数(用于out指令) | |
| “n” | 立即数 | |
| “p” | 立即数,有些系统不支持除字以外的立即数,这些系统应该使用“n”而不是“i” | |
| 匹配 | & | 该输出操作数不能使用过和输入操作数相同的寄存器 |
| 操作数类型 | “=” | 操作数在指令中是只写的(输出操作数) |
| “+” | 操作数在指令中是读写类型的(输入输出操作数) | |
| 浮点数 | “f” | 浮点寄存器 |
| “t” | 第一个浮点寄存器 | |
| “u” | 第二个浮点寄存器 | |
| “G” | 标准的80387浮点常数 | |
| 其它 | % | 该操作数可以和下一个操作数交换位置 |
| # | 部分注释,从该字符到其后的逗号之间所有字母被忽略 | |
| * | 表示如果选用寄存器,则其后的字母被忽略 | |
6. 例子
(1)例一
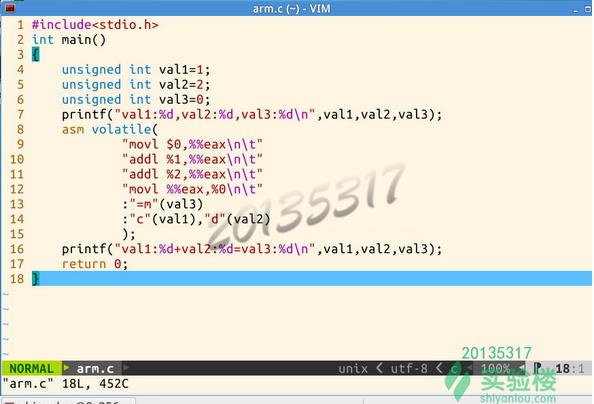
- 第13行:输出部分:val3只写。
- 第14行:输入部分:val1放入%ecx,val2放入%edx。
- 第9行:将eax的值置为0。
- 第10行:将%1(val1)中的值加在eax中,eax=1。
- 第11行:将%2(val2)中的值加在eax中,eax=3。
-
第12行:将eax中的值3赋给%0(val3)。
结果: 第一个printf:val1=1,val2=2,val3=0 第二个printf:val1=1,val2=2,val3=3 -
运行验证
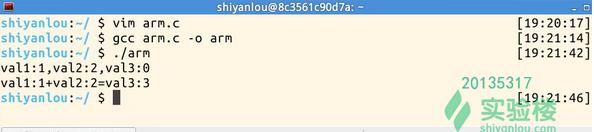
(2)例二

- output、temp只写,input放入任意一个通用寄存器。
- 第6行:将eax的值置为0。
- 第7行:把eax中的0赋给%1(temp)。
- 第8行:把%2(input)的值1赋给eax。
- 第9行:把eax赋给%0(output)。
结果:temp=0,output=1。四、mykernel实验
1. 部分内核代码模拟
-
使用实验楼的虚拟机启动mykernel
cd LinuxKernel/linux-3.9.4 qemu -kernel arch/x86/boot/bzImage -
在QEMU窗口,不停的输出字符串:
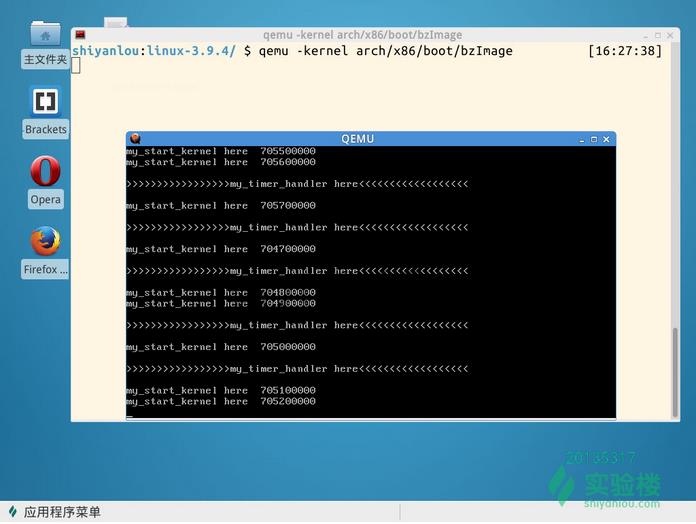
-
源代码mymain.c和myinterrupt.c
-
在mymain.c的my_start_kernel函数中有一个循环,不停的输出
my_start_kernel here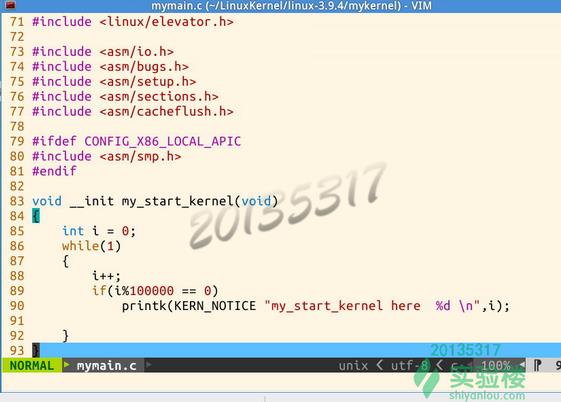
-
在myinterrupt.c中,可以看到一个会被时钟中断周期调用的函数my_timer_handler ,在这个函数里,输出
>>>>>my_timer_handler here <<<<<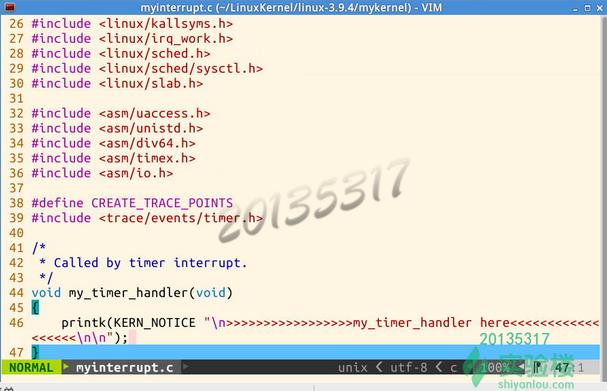
-
-
即:mykernel系统启动后,调用my_start_kernel函数,周期性的调用my_timer_handler函数,它们完成了系统进程的初始化和进程的轮转调度,这就是一个简单的操作系统模拟。
2. 一个简单的时间片轮转多道程序
(1)主要改写文件
mypcb.h : 进程控制块PCB结构体定义。
mymain.c: 初始化各个进程并启动0号进程。
myinterrupt.c:时钟中断处理和进程调度算法。(2)mypcd.h源代码
/*
* linux/mykernel/mypcb.h
* Kernel internal PCB types
* Copyright (C) 2013 Mengning
*/
#define MAX_TASK_NUM 4
#define KERNEL_STACK_SIZE 1024*8
/* CPU-specific state of this task */
struct Thread {
unsigned long ip;//保存eip
unsigned long sp;//保存esp
};
typedef struct PCB{
int pid;
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
char stack[KERNEL_STACK_SIZE];
/* CPU-specific state of this task */
struct Thread thread;
unsigned long task_entry;
struct PCB *next;
}tPCB;
void my_schedule(void);//调度器- 本文件中定义了Thread结构体,用于存储当前进程中正在执行的线程的eip和esp。
- PCB结构体中:
- pid:进程号
- state:进程状态,在模拟系统中,所有进程控制块信息都会被创建出来,其初始化值就是-1,如果被调度运行起来,其值就会变成0
- stack:进程使用的堆栈
- thread:当前正在执行的线程信息
- task_entry:进程入口函数(就像一般我们用的进程定义的是main)
- next:指向下一个PCB,模拟系统中所有的PCB是以链表的形式组织起来的。
- 函数的声明my_schedule:调度器。它在my_interrupt.c中实现,在mymain.c中的各个进程函数会根据一个全局变量的状态来决定是否调用它,从而实现主动调度。
(3)mymain.c:内核初始化和0号进程启动
/*
* linux/mykernel/mymain.c
* Kernel internal my_start_kernel
* Copyright (C) 2013 Mengning
*/
#include <linux/types.h>
#include <linux/string.h>
#include <linux/ctype.h>
#include <linux/tty.h>
#include <linux/vmalloc.h>
#include "mypcb.h"
tPCB task[MAX_TASK_NUM];
tPCB * my_current_task = NULL;
volatile int my_need_sched = 0;//用来判断是否需要调度的标识
void my_process(void);
void __init my_start_kernel(void)
{
int pid = 0;
int i;
/* Initialize process 0 (初始化0号进程)*/
task[pid].pid = pid;
task[pid].state = 0;/* -1 unrunnable, 0 runnable, >0 stopped */
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;//定义0号进程的入口:myprocess
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].next = &task[pid];//由于0号进程初始化时只有这一个进程,所以next指向自己
/*fork more process (创建更多其他的进程)*/
for(i=1;i<MAX_TASK_NUM;i++)
{
memcpy(&task[i],&task[0],sizeof(tPCB));
task[i].pid = i;
task[i].state = -1;
task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE-1];
task[i].next = task[i-1].next;
task[i-1].next = &task[i];
}
/* start process 0 by task[0] */
pid = 0;
my_current_task = &task[pid];
asm volatile(
//%0表示参数thread.ip,%1表示参数thread.sp。
"movl %1,%%esp\n\t" /* set task[pid].thread.sp to esp 把参数thread.sp放到esp中*/
"pushl %1\n\t" /* push ebp 由于当前栈是空的,esp与ebp指向相同,所以等价于push ebp*/
"pushl %0\n\t" /* push task[pid].thread.ip */
"ret\n\t" /* pop task[pid].thread.ip to eip */
"popl %%ebp\n\t"
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp)
/* input c or d mean %ecx/%edx*/
);
}
void my_process(void)
{
int i = 0;
while(1)
{
i++;
if(i%10000000 == 0)
{
printk(KERN_NOTICE "this is process %d -\n",my_current_task->pid);
if(my_need_sched == 1)
{
my_need_sched = 0;
my_schedule();
}
printk(KERN_NOTICE "this is process %d +\n",my_current_task->pid);
}
}
}- 函数my_start_kernel是系统启动后,最先调用的函数,在这个函数里完成了0号进程的初始化和启动(状态是正在运行、入口是myprocess,进程刚启动时next指向自己)。
- 创建了其它的多个进程,在初始化这些进程的时候可以直接利用0号进程的代码。
- my_process函数:在模拟系统里,每个进程的函数代码都是一样的。my_process 在执行时,打印出当前进程的id,能够看到当前哪个进程正在执行。每循环10000000次检查全局标志变量
my_need_sched判断是否需要调度,一旦发现其值为1,就调用my_schedule完成进程的调度。
(4)myinterrupt.c
/*
* linux/mykernel/myinterrupt.c
* Kernel internal my_timer_handler
* Copyright (C) 2013 Mengning
*/
#include <linux/types.h>
#include <linux/string.h>
#include <linux/ctype.h>
#include <linux/tty.h>
#include <linux/vmalloc.h>
#include "mypcb.h"
extern tPCB task[MAX_TASK_NUM];
extern tPCB * my_current_task;
extern volatile int my_need_sched;
volatile int time_count = 0;
/*
* Called by timer interrupt.
* it runs in the name of current running process,
* so it use kernel stack of current running process
*/
void my_timer_handler(void)//用于设置时间片的大小,时间片用完时设置调度标志。
{
#if 1
if(time_count%1000 == 0 && my_need_sched != 1)
{
printk(KERN_NOTICE ">>>my_timer_handler here<<<\n");
my_need_sched = 1;
}
time_count ++ ;
#endif
return;
}
void my_schedule(void)
{
tPCB * next;
tPCB * prev;
if(my_current_task == NULL //task为空,即发生错误时返回
|| my_current_task->next == NULL)
{
return;
}
printk(KERN_NOTICE ">>>my_schedule<<<\n");
/* schedule */
next = my_current_task->next;//把当前进程的下一个进程赋给next
prev = my_current_task;//当前进程为prev
if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */
{
/* switch to next process */
/*如果下一个进程的状态是正在执行的话,就运用if语句中的代码表示的方法来切换进程*/
asm volatile(
"pushl %%ebp\n\t" /* save ebp 保存当前进程的ebp*/
"movl %%esp,%0\n\t" /* save esp 把当前进程的esp赋给%0(指的是thread.sp),即保存当前进程的esp*/
"movl %2,%%esp\n\t" /* restore esp 把%2(指下一个进程的sp)放入esp中*/
"movl $1f,%1\n\t" /* save eip $1f是接下来的标号“1:”的位置,把eip保存下来*/
"pushl %3\n\t" /*把下一个进程eip压栈*/
"ret\n\t" /* restore eip 下一个进程开始执行*/
"1:\t" /* next process start here */
"popl %%ebp\n\t"
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid);
}
else//用于下一个进程为未执行过的新进程时。首先将这个进程置为运行时状态,将这个进程作为当前正在执行的进程。
{
next->state = 0;
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid);
/* switch to new process */
asm volatile(
"pushl %%ebp\n\t" /* save ebp */
"movl %%esp,%0\n\t" /* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl %2,%%ebp\n\t" /* restore ebp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t" /*把当前进程的入口保存起来*/
"ret\n\t" /* restore eip */
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
}
return;
}- my_timer_handler当时钟中断发生1000次,并且my_need_sched不等于1时,把my_need_sched赋为1。当进程发现my_need_sched=1时,就会执行my_schedule。
五、总结
操作系统“两剑”:中断上下文、进程上下文的切换- 操作系统的核心功能就是:进程调度和中断机制,通过与硬件的配合实现多任务处理,再加上上层应用软件的支持,最终变成可以使用户可以很容易操作的计算机系统。
- Linux是一个多进程的操作系统,所以,其他的进程必须等到正在运行的进程空闲CPU后才能运行。当正在运行的进程等待其他的系统资源时,Linux内核将取得CPU的控制权,并将CPU分配给其他正在等待的进程,这就是进程切换。
- 进程切换机制中包含esp的切换、堆栈的切换。从esp可以找到进程的描述符;堆栈中ebp的切换,确定了当前变量空间属于哪个进程。
以上是关于LINUX内核分析第二周学习总结:操作系统是如何工作的?的主要内容,如果未能解决你的问题,请参考以下文章