[Bayes] Hist & line: Reject Sampling and Importance Sampling
Posted 机器学习水很深
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Bayes] Hist & line: Reject Sampling and Importance Sampling相关的知识,希望对你有一定的参考价值。
吻合度蛮高,但不光滑。
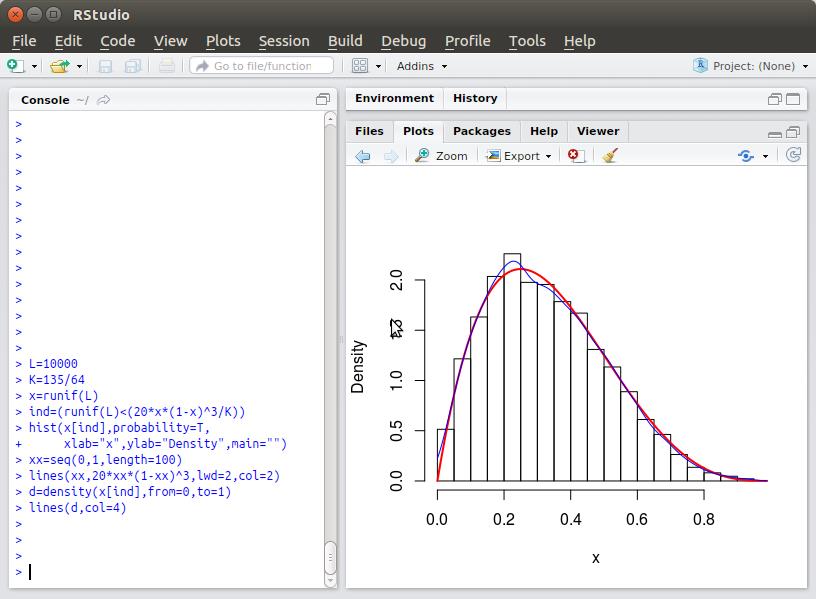
> L=10000
> K=135/64
> x=runif(L)
> ind=(runif(L)<(20*x*(1-x)^3/K))
> hist(x[ind],probability=T,
+ xlab="x",ylab="Density",main="")
/* 应用了平滑数据的核函数 */
> d=density(x[ind],from=0,to=1) // 只对标记为true的x做统计 --> 核密度估计
> lines(d,col=4) // (BLUE)
> xx=seq(0,1,length=100)
> lines(xx,20*xx*(1-xx)^3,lwd=2,col=2) //lwd: line width, col: color number (Red)
API DOC: https://stat.ethz.ch/R-manual/R-devel/library/stats/html/density.html
参见:
http://blog.csdn.net/yuanxing14/article/details/41948485 基于核函数的目标跟踪算法 (貌似淘汰的技术)
https://www.zhihu.com/question/27301358/answer/105267357?from=profile_answer_card
Importance Sampling (Green line) 更为光滑:

> L=10000
> K=135/64
> x=runif(L)
> ind=(runif(L)<(20*x*(1-x)^3/K))
> hist(x[ind],probability=T, xlab="x",ylab="Density",main="")
>
> d=density(x[ind],from=0,to=1)
> lines(d,col=4)
>
> y=runif(L)
> w=20*y*(1-y)^3 // 可见,权重大小与实际分布吻合。
> W=w/sum(w) // 每个x轴的sample point的权重值W。
> d=density(y,weights=W,from=0,to=1)
> lines(d,col=3)
>
> xx=seq(0,1,length=100)
> lines(xx,20*xx*(1-xx)^3,lwd=2,col=2)
无论是拒绝抽样还是重要性采样,都是属于独立采样,即样本与样本之间是独立无关的,这样的采样效率比较低,
如拒绝采样,所抽取的样本中有很大部分是无效的,这样效率就比较低,MCMC方法是关联采样,即下一个样本与这个样本有关系,从而使得采样效率高。
以上是关于[Bayes] Hist & line: Reject Sampling and Importance Sampling的主要内容,如果未能解决你的问题,请参考以下文章