拆分:分解单块系统——《微服务设计》读书笔记
Posted 西门吹牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拆分:分解单块系统——《微服务设计》读书笔记相关的知识,希望对你有一定的参考价值。
系列文章目录:
通常,我们可能已有有一个巨大的单块系统,如何实现微服务,我们需要把它分解。
从哪里开始拆分:接缝
接缝:从接缝处可以抽取相对独立的一部分代码,对这部分代码的修改不会影响系统的其他部分。这些接缝就可以作为服务的边界。
那如何识别出接缝呢?我们可以使用前面所提到的限界上下文,也可通过程序中的命名空间来帮助我们,也可以通过工具来帮助我们,如structure101这样的工具来可视化包之间的依赖。
杂乱依赖的根源:数据库
为什么这么说?因为,通常情况下,我们在业务层的代码已经通过分层组织到相应的包中了,但是只有数据库是共用的,数据库对所有的代码都允许访问,是一个巨大的API。我们举例说明:有一张仓储表,它被“产品目录”、“仓库”、“财务”等服务所共用,那么在单块应用程序中,通常会是下面的结构:
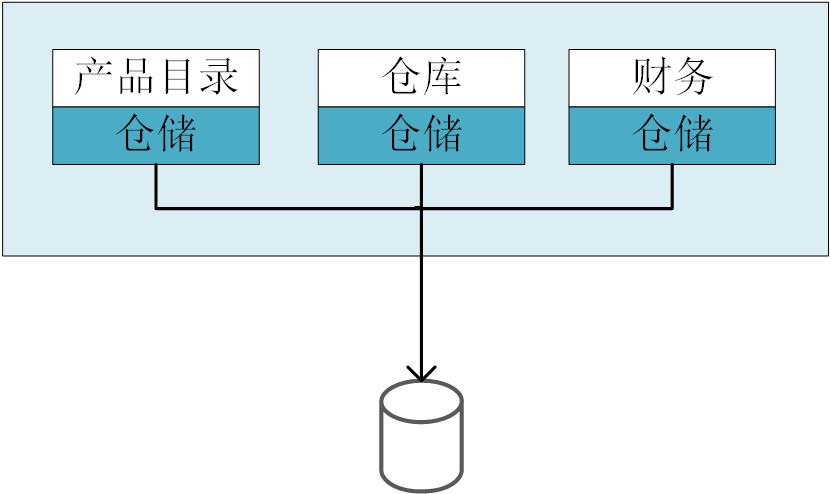
对于同一张表被多个限界上下文使用的场景,我们应该如何处理?以下是一些处理的步骤和原则 :
一.分清代码中对数据库进行读写的部分
我们需要厘清代码是如何访问数据库的,在什么地方读,在什么地方写?他们分别位于什么样的上下文中。
二.打破外键关系
对于表与表之间的外键关系,如果这两张表需要被拆分至两个微服务中,我们可能需要放弃外键关系,同时把这个约束关系放到代码中实现,我们可能还需要实现跨服务的一致性检查,或者周期性触发清理数据的任务。
我们可以通过类似于SchemeSpy这样的工具来分析数据库表之间的依赖关系。
三.共享静态数据
比如,国家、部门之类的数据都是各个微服务之间经常使用的,这些数据的特征是不会经常变,而且是通用性高。这些数据在微服务划分之后该如何处理呢?
方法一:我们可以为每个微服务复制一份这样的数据,但是这个会导致数据的一致性问题;
方法二:把共享的数据放入代码之中,比如放在属性文件 中,或者简单地放在一个枚举中,但数据一致性仍然存在。
方法三:把这些静态数据放在一个单独的服务中。
四.共享数据
如果不同的微服务都使用了同一张表,比如仓库和财务都用到了客户信息表,这种情况下该如何分享?其实这种情况很常见:领域概念不是在代码中建模,相反是在数据库中隐式地进行建模。这里缺失的领域概念是客户,因而我们需要提供一个新的服务:客户服务。
五.共享表
与共享数据不同的是:不同的微服务也会使用同一张表,但两者修改的部分不一样,这样的情况下,我们可以把这张表拆分出两张表,分别供两个微服务使用。
六.实施拆分
通常,我们推荐先分离数据库结构然后对代码进行拆分。表结构分离之后,对于原先的某个动作而言,对数据库的访问次数可能会变多。这也是我们需要考虑的问题,这里涉及到分布式事务的相关问题。
另外,先拆分数据库但不分离代码的好处在于,可以随时选择回退这些修改或是继续,而不影响服务的任何消费者。
分布式事务
一个事务可以帮助系统从一个一致性的状态迁移到另一个一致的状态,要么全部都做,要么什么都不做。
在单块结构中,所有的创建或者更新都可以在一个事务边界内完成,分离数据库之后,这种好处就没有了。在分布式事务中,我们有可能面临一个操作成功,而另一个操作失败的局而,我们该如何处理这些问题?
方法1:补偿机制——最终一致性
对于失败的动作,我们进行重复触发,只要在系统可接受的时间范围内,最终一致性是可以接受的。
方法2:回滚机制
对于失败的动作,我们可以选择回滚。但是回滚也失败的呢?这个时间,要么我们在某个时间重试回滚操作,或者提供一些自动化的操作或界面操作来清除这些不一致的状态。
方法3:分布式事务
我们可以使用事务管理器来统一编排横跨多个服务的事务,分布式的事务会保证整个系统处于一致的状态,唯一不同的是,这里的事务会运行在不同系统的不同进程中,通常它们之间使用网络进行通信。
分布式事务的常见算法是两段提交,在这种方式中,首先是投票阶段,在这个阶段,每个参与者都会告诉事务管理器是否应该继续,如果事务管理器收到所有的投票都是成功,则事务管理器会告知各个参与者执行提交操作,只要收到一个否定的投标,事务管理器就会让所有的参与者回退。
但两段提交也有缺点,首先所有的参与者都等待中央协调进程的指令,从而很容易导致系统的中断,如果事务管理器宕机了,处于等待状态的事务就永远无法完成;如果有一个参与者在投票阶段发送消息失败,则所有的其他参与者都会被阻,投票之后的提交也可能会失败;另外中央协调进程也可能使用锁,这样会对系统的扩展带来影响。因而这种算法并不是万无一失的。
如果确实存在保持一致怀的场合,应该尽量避免把它们放在不同的地方。
又一个难点:报表数据库
报表通常需要来自组织内各个部分的数据,在以往的单块结构来说,这是很方便的。但也存在一些缺点:首先是修改表结构的风险增大;再者则是报表系统的优先手段有限,比如关系型数据库对于海量的数据不能呈现很好的支持,而MongoDB则地文档存储有其独特的优越性。
一.通过服务调用来获取数据
报表数据通常需要大量的数据,通过服务提供接口来一条条调用很显示是不太合适的,这样非常低效而且对服务来说负载过重。
我们可以一次性返回分页的多条记录,或者在本地将数据导出到文件文件的地址返回给调用方以供使用。
二.数据导出
我们也可以把报表数据周期性的导出,推送到报表数据库,但这样不同微服务的数据又集成到一起的,这时我们可以使用一些技术来屏蔽这些耦合,比如视图
三.事件数据导出
在每次数据发生变化时,数据提供方也会提供一些事件,数据订阅方可以将这些数据导出到报表数据库中,这样源数据与数据之间的耦合就消除掉了,我们只需要绑定到服务所发送的事件即可。
不同前面的周期性导出数据,这里的事件数据是实时,所以能让数据更快地流入报表系统。
另外,我们只需要对新事件产生的新数据进行处理,即处理增量数据,这样的操作会更加高效。
而缺点在于事件数据必须以事件的形式广播出去,同时在数据量时,不容易进行扩展,而前面的数据导出的方式,可以在数据库级别进行扩展。
四.数据导出的备份
这里是整库备份,因而也会造成不同微服务之间数据的耦合。
参考
《微服务设计》(Sam Newman 著 / 崔力强 张骏 译)
以上是关于拆分:分解单块系统——《微服务设计》读书笔记的主要内容,如果未能解决你的问题,请参考以下文章
《微服务架构设计模式》读书笔记 | 第2章 服务的拆分策略 #yyds干货盘点#