计算机程序的思维逻辑 - 如何从乱码中恢复 (下)
Posted 张柯宇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机程序的思维逻辑 - 如何从乱码中恢复 (下)相关的知识,希望对你有一定的参考价值。
乱码
上节说到乱码出现的主要原因,即在进行编码转换的时候,如果将原来的编码识别错了,并进行了转换,就会发生乱码,而且这时候无论怎么切换查看编码的方式,都是不行的。
我们来看一个这种错误转换后的乱码,还是用上节的例子,二进制是(16进制表示):C3 80 C3 8F C3 82 C3 AD,无论按哪种编码解析看上去都是乱码:
| UTF-8 | ÀÏÂí |
| Windows-1252 | ÀÃÂà |
| GB18030 | 脌脧脗铆 |
| Big5 | ���穩 |
虽然有这么多形式,但我们看到的乱码形式很可能是"ÀÏÂí",因为在例子中UTF-8是编码转换的目标编码格式,既然转换为了UTF-8,一般也是要按UTF-8查看。
乱码恢复
"乱"主要是因为发生了一次错误的编码转换,恢复是要恢复两个关键信息,一个是原来的二进制编码方式A,另一个是错误解读的编码方式B。
恢复的基本思路是尝试进行逆向操作,假定按一种编码转换方式B获取乱码的二进制格式,然后再假定一种编码解读方式A解读这个二进制,查看其看上去的形式,这个要尝试多种编码,如果能找到看着正常的字符形式,那应该就可以恢复。
这个听上去可能比较模糊,我们举个例子来说明,假定乱码形式是"ÀÏÂí",尝试多种B和A来看字符形式。我们先使用编辑器,以UltraEdit为例,然后使用Java编程来看。
使用UltraEdit
UltraEdit支持编码转换和切换查看编码方式,也支持文件的二进制显示和编辑,所以我们以UltraEdit为例,其他一些编辑器可能也有类似功能。
新建一个UTF-8编码的文件,拷贝"ÀÏÂí"到文件中。使用编码转换,转换到windows-1252编码,功能在 "文件"->"转换到"->"西欧"->WIN-1252。
转换完后,打开十六进制编辑,查看其二进制形式,如下图所示:
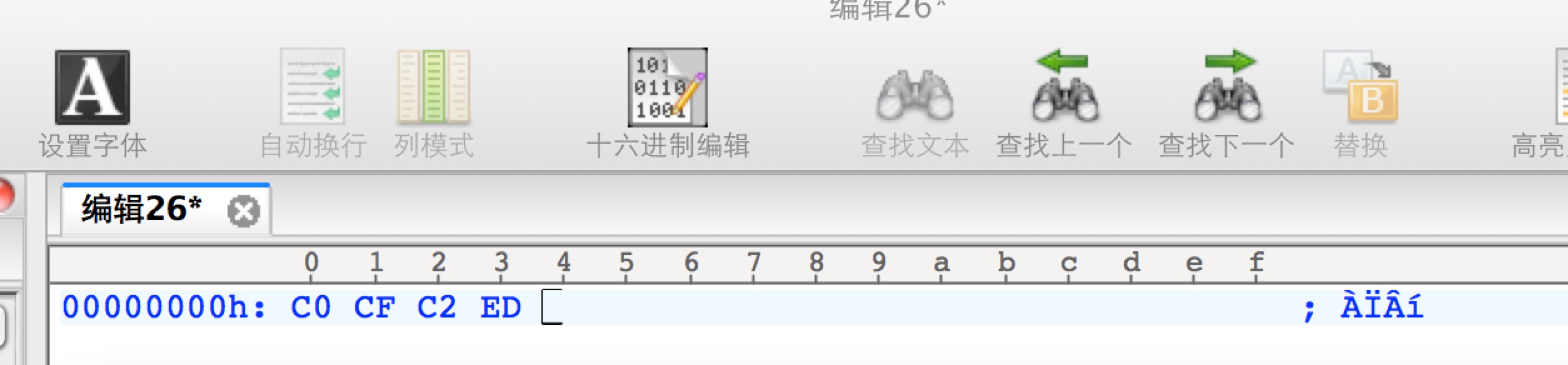
可以看出,其形式还是ÀÏÂí,但二进制格式变成了 C0 CF C2 ED。这个过程,相当于假设B是windows-1252。这个时候,再按照多种编码格式查看这个二进制,在UltraEdit中,关闭十六进制编辑,切换查看编码方式为GB18030,功能在 "视图"->"查看方式(文件编码)"->"东亚语言"->GB18030,切换完后,同样的二进制神奇的变为了正确的字符形式 "老马",打开十六进制编辑器,可以看出,二进制还是C0 CF C2 ED,这个GB18030相当于假设A是GB18030。
这个例子我们碰巧第一次就猜对了。实际中,我们可能要做多次尝试,过程是类似的,先进行编码转换(使用B编码),然后使用不同编码方式查看(使用A编码),如果能找到看上去对的形式,就恢复了。下图列出了主要的B编码格式,对应的二进制,按A编码解读的各种形式。
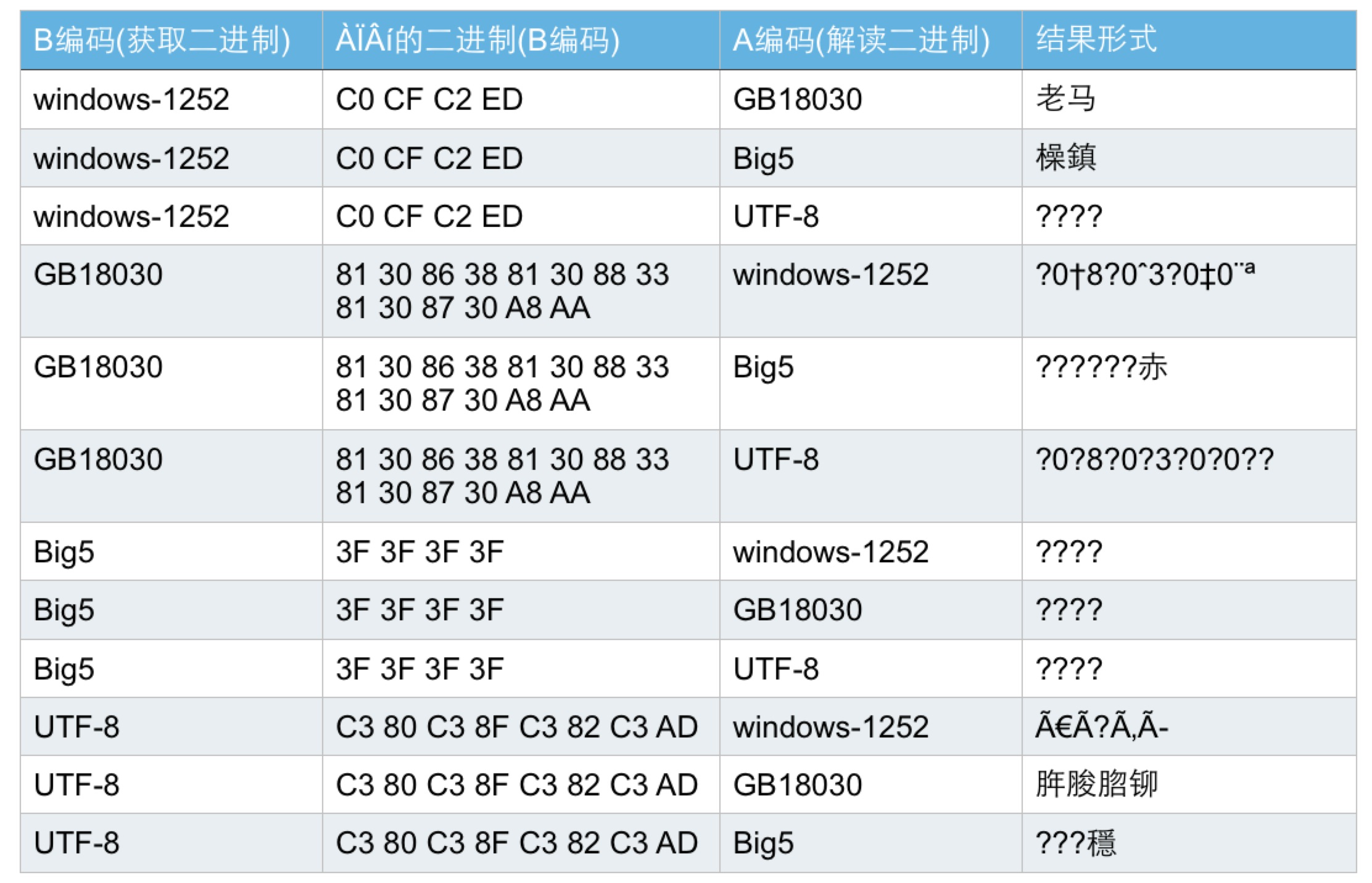
可以看出,第一行是正确的,也就是说原来的编码其实是A即GB18030,但被错误解读成了B即Windows-1252了。
使用Java
关于使用Java我们还有很多知识没有介绍,但一些读者已经有很好的Java知识,所以本文一并列出相关代码,初学者不明白的我们随后会进一步讲解。
Java中处理字符串的类有String,String中有我们需要的两个重要方法:
- public byte[] getBytes(String charsetName),这个方法可以获取一个字符串的给定编码格式的二进制形式
- public String(byte bytes[], String charsetName),这个构造方法以给定的二进制数组bytes按照编码格式charsetName解读为一个字符串。
将A看做GB18030,B看做Windows-1252,进行恢复的Java代码如下所示:
String str = "ÀÏÂí";
String newStr = new String(str.getBytes("windows-1252"),"GB18030");
System.out.println(newStr);
先按照B编码(windows-1252)获取字符串的二进制,然后按A编码(GB18030)解读这个二进制,得到一个新的字符串,然后输出这个字符串的形式,输出为"老马"。
同样,这个一次碰巧就对了,实际中,我们可以写一个循环,测试不同的A/B编码中的结果形式,代码如下所示:

public static void recover(String str)
throws UnsupportedEncodingException{
String[] charsets = new String[]{"windows-1252","GB18030","Big5","UTF-8"};
for(int i=0;i<charsets.length;i++){
for(int j=0;j<charsets.length;j++){
if(i!=j){
String s = new String(str.getBytes(charsets[i]),charsets[j]);
System.out.println("---- 原来编码(A)假设是: "+charsets[j]+", 被错误解读为了(B): "+charsets[i]);
System.out.println(s);
System.out.println();
}
}
}
}
以上代码使用不同的编码格式进行测试,如果输出有正确的,那么就可以恢复。
恢复的讨论
可以看出,这种尝试需要进行很多次,上面例子尝试了常见编码GB18030/Windows 1252/Big5/UTF-8共十二种组合。这四种编码是常见编码,在大部分实际应用中应该够了,但如果你的情况有其他编码,可以增加一些尝试。
不是所有的乱码形式都是可以恢复的,如果形式中有很多不能识别的字符如�?,则很难恢复,另外,如果乱码是由于进行了多次解析和转换错误造成的,也很难恢复。
以上是关于计算机程序的思维逻辑 - 如何从乱码中恢复 (下)的主要内容,如果未能解决你的问题,请参考以下文章