难免的尴尬:代码依赖
Posted foreach
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了难免的尴尬:代码依赖相关的知识,希望对你有一定的参考价值。
相关文章连接
动力之源:代码中的泵
高屋建瓴:梳理编程约定
编程之基础:数据类型(一)
编程之基础:数据类型(二)
可复用代码:组件的来龙去脉
重中之重:委托与事件
物以类聚:对象也有生命
难免的尴尬:代码依赖
- 12.1 从面向对象开始
- 12.1.1 对象基础:封装
- 12.1.2 对象扩展:继承
- 12.1.3 对象行为:多态
- 12.2 不可避免的代码依赖
- 12.2.1 依赖存在的原因
- 12.2.2 耦合与内聚
- 12.2.3 依赖造成的尴尬
- 12.3 降低代码依赖
- 12.3.1 认识抽象与具体
- 12.3.2 再看“依赖倒置原则”
- 12.3.3 依赖注入
- 12.4 框架中的“代码依赖”
- 12.4.1 控制转换
- 12.4.2 依赖注入对框架的意义
- 12.5 本章回顾
- 12.6 本章思考
在浩瀚的代码世界中,有着无数的对象,跟人和人之间有社交关系一样,对象跟对象之间也避免不了接触,所谓接触,就是指一个对象要使用到另外对象的属性、方法等成员。现实生活中一个人的社交关系复杂可能并不是什么不好的事情,然而对于代码中的对象而言,复杂的"社交关系"往往是不提倡的,因为对象之间的关联性越大,意味着代码改动一处,影响的范围就会越大,而这完全不利于系统重构和后期维护。所以在现代软件开发过程中,我们应该遵循"尽量降低代码依赖"的原则,所谓尽量,就已经说明代码依赖不可避免。
有时候一味地追求"降低代码依赖"反而会使系统更加复杂,我们必须在"降低代码依赖"和"增加系统设计复杂性"之间找到一个平衡点,而不应该去盲目追求"六人定理"那种设计境界。
注:"六人定理"指:任何两个人之间的关系带,基本确定在六个人左右。两个陌生人之间,可以通过六个人来建立联系,此为六人定律,也称作六人法则。
12.1 从面向对象开始
在计算机科技发展历史中,编程的方式一直都是趋向于简单化、人性化,"面向对象编程"正是历史发展某一阶段的产物,它的出现不仅是为了提高软件开发的效率,还符合人们对代码世界和真实世界的统一认识观。当说到"面向对象",出现在我们脑海中的词无非是:类,抽闲,封装,继承以及多态,本节将从对象基础、对象扩展以及对象行为三个方面对"面向对象"做出解释。
注:面向对象中的"面向"二字意指:在代码世界中,我们应该将任何东西都看做成一个封闭的单元,这个单元就是"对象"。对象不仅仅可以代表一个可以看得见摸得着的物体,它还可以代表一个抽象过程,从理论上讲,任何具体的、抽象的事物都可以定义成一个对象。
12.1.1 对象基础:封装
和现实世界一样,无论从微观上还是宏观上看,这个世界均是由许许多多的单个独立物体组成,小到人、器官、细胞,大到国家、星球、宇宙, 每个独立单元都有自己的属性和行为。仿照现实世界,我们将代码中有关联性的数据与操作合并起来形成一个整体,之后在代码中数据和操作均是以一个整体出现,这个过程称为"封装"。封装是面向对象的基础,有了封装,才会有整体的概念。
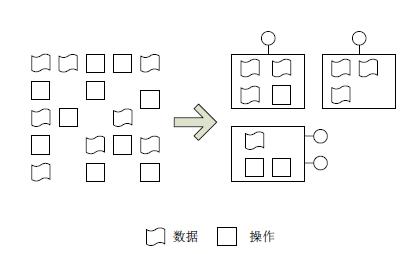
图12-1 封装前后
如上图12-1所示,图中左边部分为封装之前,数据和操作数据的方法没有相互对应关系,方法可以访问到任何一个数据,每个数据没有访问限制,显得杂乱无章;图中右边部分为封装之后,数据与之关联的方法形成了一个整体单元,我们称为"对象",对象中的方法操作同一对象的数据,数据之间有了"保护"边界。外界可以通过对象暴露在外的接口访问对象,比如给它发送消息。
通常情况下,用于保存对象数据的有字段和属性,字段一般设为私有访问权限,只准对象内部的方法访问,而属性一般设为公开访问权限,供外界访问。方法就是对象的表现行为,分为私有访问权限和公开访问权限两类,前者只准对象内部访问,而后者允许外界访问。

1 //Code 12-1
2 class Student //NO.1
3 {
4 private string _name; //NO.2
5 private int _age;
6 private string _hobby;
7 public string Name //NO.3
8 {
9 get
10 {
11 return _name;
12 }
13 }
14 public int Age
15 {
16 get
17 {
18 return _age;
19 }
20 set
21 {
22 if(value<=0)
23 {
24 value=1;
25 }
26 _age = value;
27 }
28 }
29 public string Hobby
30 {
31 get
32 {
33 return _hobby;
34 }
35 set
36 {
37 _hobby = value;
38 }
39 }
40 public Student(string name,int age,string hobby)
41 {
42 _name = name;
43 _age = age;
44 _hobby = hobby;
45 }
46 public void SayHello() //NO.4
47 {
48 Console.WriteLine(GetSayHelloWords());
49 }
50 protected virtual string GetSayHelloWords() //NO.5
51 {
52 string s = "";
53 s += "hello,my name is " + _name + ",\\r\\n",
54 s += "I am "+_age + "years old," + "\\r\\n";
55 s += "I like "+_hobby + ",thanks\\r\\n";
56 return s;
57 }
58 }
上面代码Code 12-1将学生这个人群定义成了一个Student类(NO.1处),它包含三个字段:分别为保存姓名的_name、保存年龄的_age以及保存爱好的_hobby字段,这三个字段都是私有访问权限,为了方便外界访问内部的数据,又分别定义了三个属性:分别为访问姓名的Name,注意该属性是只读的,因为正常情况下姓名不能再被外界改变;访问年龄的Age,注意当给年龄赋值小于等于0时,代码自动将其设置为1;访问爱好的Hobby,外界可以通过该属性对_hobby字段进行完全访问。同时Student类包含两个方法,一个公开的SyaHello()方法和一个受保护的GetSayHelloWords()方法,前者负责输出对象自己的"介绍信息",后者负责格式化"介绍信息"的字符串。Student类图见图12-2:

图12-2 Student类图
注:上文中将类的成员访问权限只分为两个部分,一个对外界可见,包括public;另一种对外界不可见,包括private、protected等。
注意类与对象的区别,如果说对象是代码世界对现实世界中各种事物的一一映射,那么类就是这些映射的模板,通过模板创建具体的映射实例:
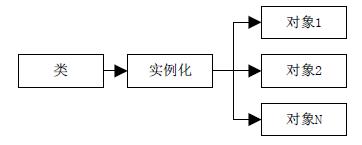
图12-3 对象实例化
我们可以看到代码Code 12-1中的Student类既包含私有成员也包含公开成员,私有成员对外界不可见,外界如需访问对象,只能调用给出的公开方法。这样做的目的就是将外界不必要了解的信息隐藏起来,对外只提供简单的、易懂的、稳定的公开接口即可方便外界对该类型的使用,同时也避免了外界对对象内部数据不必要的修改和访问所造成的异常。
封装的准则:
封装是面向对象的第一步,有了封装,才会有类、对象,再才能谈继承、多态等。经过前人丰富的实践和总结,对封装有以下准则,我们在平时实际开发中应该尽量遵循这些准则:
1)一个类型应该尽可能少地暴露自己的内部信息,将细节的部分隐藏起来,只对外公开必要的稳定的接口;同理,一个类型应该尽可能少地了解其它类型,这就是常说的"迪米特法则(Law of Demeter)",迪米特法则又被称作"最小知识原则",它强调一个类型应该尽可能少地知道其它类型的内部实现,它是降低代码依赖的一个重要指导思想,详见本章后续介绍;
2)理论上,一个类型的内部代码可以任意改变,而不应该影响对外公开的接口。这就要求我们将"善变"的部分隐藏到类型内部,对外公开的一定是相对稳定的;
3)封装并不单指代码层面上,如类型中的字段、属性以及方法等,更多的时候,我们可以将其应用到系统结构层面上,一个模块乃至系统,也应该只对外提供稳定的、易用的接口,而将具体实现细节隐藏在系统内部。
封装的意义:
封装不仅能够方便对代码对数据的统一管理,它还有以下意义:
1)封装隐藏了类型的具体实现细节,保证了代码安全性和稳定性;
2)封装对外界只提供稳定的、易用的接口,外部使用者不需要过多地了解代码实现原理也不需要掌握复杂难懂的调用逻辑,就能够很好地使用类型;
3)封装保证了代码模块化,提高了代码复用率并确保了系统功能的分离。
12.1.2 对象扩展:继承
封装强调代码合并,封装的结果就是创建一个个独立的包装件:类。那么我们有没有其它的方法去创建新的包装件呢?
在现实生活中,一种物体往往衍生自另外一种物体,所谓衍生,是指衍生体在具备被衍生体的属性基础上,还具备其它额外的特性,被衍生体往往更抽象,而衍生体则更具体,如大学衍生自学校,因为大学具备学校的特点,但大学又比学校具体,人衍生自生物,因为人具备生物的特点,但人又比生物具体。
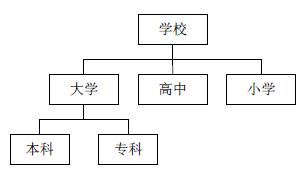
图12-4 学校衍生图
如上图12-4,学校相对来讲最抽象,大学、高中以及小学均可以衍生自学校,进一步来看,大学其实也比较抽象,因为大学还可以有具体的本科、专科,因此本科和专科可以衍生自大学,当然,抽象和具体的概念是相对的,如果你觉得本科还不够具体,那么它可以再衍生出来一本、二本以及三本。
在代码世界中,也存在"衍生"这一说,从一个较抽象的类型衍生出一个较具体的类型,我们称"后者派生自前者",如果A类型派生自B类型,那么称这个过程为"继承",A称之为"派生类",B则称之为"基类"。
注:派生类又被形象地称为"子类",基类又被形象地称为"父类"。
在代码12-1中的Student类基础上,如果我们需要创建一个大学生(College_Student)的类型,那么我们完全可以从Student类派生出一个新的大学生类,因为大学生具备学生的特点,但又比学生更具体:
1 //Code 12-2
2 class College_Student:Student //NO.1
3 {
4 private string _major;
5 public string Major
6 {
7 get
8 {
9 return _major;
10 }
11 set
12 {
13 _major = value;
14 }
15 }
16 public College_Student(string name,int age,string hobby,string major) :base(name,age,hobby) //NO.2
17 {
18 _major = major;
19 }
20 protected override string GetSayHelloWords() //NO.3
21 {
22 string s = "";
23 s += "hello,my name is " + Name + ",\\r\\n",
24 s += "I am "+ Age + "years old, and my major is " + _major + ",\\r\\n";
25 s += "I like "+ Hobby + ", thanks\\r\\n";
26 return s;
27 }
28 }
如上代码Code 12-2所示,College_Student类继承Student类(NO.1处),College_Student类具备Student类的属性,比如Name、Age以及Hobby,同时College_Student类还增加了额外的专业(Major)属性,通过在派生类中重写GetSyaHelloWords()方法,我们重新格式化"个人信息"字符串,让其包含"专业"的信息(NO.3处),最后,调用College_Student中从基类继承下来的SayHello()方法,便可以轻松输出自己的个人信息。
我们看到,派生类通过继承获得了基类的全部信息,之外,派生类还可以增加新的内容(如College_Student类中新增的Major属性),基类到派生类是一个抽象到具体的过程,因此,我们在设计类型的时候,经常将通用部分提取出来,形成一个基类,以后所有与基类有种族关系的类型均可以继承该基类,以基类为基础,增加自己特有的属性。

图12-5 College_Student类继承图
有的时候,一种类型只用于其它类型派生,从来不需要创建它的某个具体对象实例,这样的类高度抽象化,我们称这种类为"抽象类",抽象类不负责创建具体的对象实例,它包含了派生类型的共同成分。除了通过继承某个类型来创建新的类型,.NET中还提供另外一种类似的创建新类型的方式:接口实现。接口定义了一组方法,所有实现了该接口的类型必须实现接口中所有的方法:
1 //Code 12-3
2 interface IWalkable
3 {
4 void Walk();
5 }
6 class People:IWalkable
7 {
8 //…
9 public void Walk()
10 {
11 Console.WriteLine("walk quickly");
12 }
13 }
14 class Dog:IWalkable
15 {
16 //…
17 public void Walk()
18 {
19 Console.WriteLine("walk slowly");
20 }
21 }
如上代码Code 12-3所示,People和Dog类型均实现了IWalkable接口,那么它们必须都实现IWalkable接口中的Walk()方法,见下图12-6:
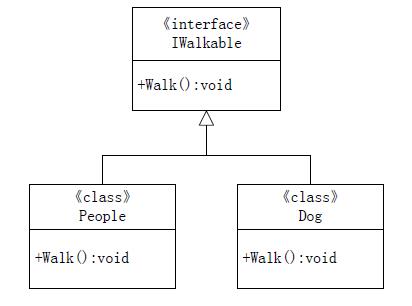
图12-6 接口继承
继承包括两种方式,一种为"类继承",一种为"接口继承",它们的作用类似,都是在现有类型基础上创建出新的类型,但是它们也有区别:
1)类继承强调了族群关系,而接口继承强调通用功能。类继承中的基类和派生类属于祖宗和子孙的关系,而接口继承中的接口和实现了接口的类型并没有这种关系。
2)类继承强调"我是(Is-A)"的关系,派生类"是"基类(注意这里的"是"代表派生类具备基类的特性),而接口继承强调"我能做(Can-Do)"的关系,实现了接口的类型具有接口中规定的行为能力(因此接口在命名时均以"able"作为后缀)。
3)类继承中,基类虽然较抽象,但是它可以有具体的实现,比如方法、属性的实现,而接口继承中,接口不允许有任何的具体实现。
继承的准则:
继承是面向对象编程中创建类型的一种方式,在封装的基础上,它能够减少工作量、提高代码复用率的同时,快速地创建出具有相似性的类型。在使用继承时,请遵循以下准则:
1)严格遵守"里氏替换原则",即基类出现的地方,派生类一定可以出现,因此,不要盲目地去使用继承,如果两个类没有衍生的关系,那么就不应该有继承关系。如果让猫(Cat)类派生自狗(Dog)类,那么很容易就可以看到,狗类出现的地方,猫类不一定可以代替它出现,因为它两根本就没有抽象和具体的层次关系。
2)由于派生类会继承基类的全部内容,所以要严格控制好类型的继承层次,不然派生类的体积会越来越大。另外,基类的修改必然会影响到派生类,继承层次太多不易管理,继承是增加耦合的最重要因素。
3)继承强调类型之间的通性,而非特性。因此我们一般将类型都具有的部分提取出来,形成一个基类(抽象类)或者接口。
12.1.3 对象行为:多态
"多态"一词来源于生物学,本意是指地球上的所有生物体现出形态和状态的多样性。在面向对象编程中多态是指:同一操作作用于不同类的实例,将产生不同的执行结果,即不同类的对象收到相同的消息时,得到不同的结果。
多态强调面向对象编程中,对象的多种表现行为,见下代码Code 12-4:
1 //Code 12-4
2 class Student //NO.1
3 {
4 public void IntroduceMyself()
5 {
6 SayHello();
7 }
8 protected virtual void SayHello()
9 {
10 Console.WriteLine("Hello,everyone!");
11 }
12 }
13 class College_Student:Student //NO.2
14 {
15 protected override void SayHello()
16 {
17 base.SayHello();
18 Console.WriteLine("I am a college student…");
19 }
20 }
21 class Senior_HighSchool_Student:Student //NO.3
22 {
23 protected override void SayHello()
24 {
25 base.SayHello();
26 Console.WriteLine("I am a senior high school student…");
27 }
28 }
29 class Program
30 {
31 static void Main()
32 {
33 Console.Title = "SayHello";
34 Student student = new Student();
35 student.IntroduceMyself(); //NO.4
36 student = new College_Student();
37 student.IntroduceMyself(); //NO.5
38 student = new Senior_HighSchool_Student();
39 student.IntroduceMyself(); //NO.6
40 Console.Read();
41 }
42 }
如上代码Code 12-4所示,分别定义了三个类:Student(NO.1处)、College_Student(NO.2处)、Senior_HighSchool_Student(NO.3处),后面两个类继承自Student类,并重写了SayHello()方法。在客户端代码中,对于同一行代码"student.IntroduceMyself();"而言,三次调用(NO.4、NO.5以及NO.6处),屏幕输出的结果却不相同:

图12-7 多态效果
如上图12-7所示,三次调用同一个方法,不同对象有不同的表现行为,我们称之为"对象的多态性"。从代码Code 12-4中可以看出,之所以出现同样的调用会产生不同的表现行为,是因为给基类引用student赋值了不同的派生类对象,并且派生类中重写了SayHello()虚方法。
对象的多态性是以"继承"为前提的,而继承又分为"类继承"和"接口继承"两类,那么多态性也有两种形式:
1)类继承式多态;
类继承式多态需要虚方法的参与,正如代码Code 12-4中那样,派生类在必要时,必须重写基类的虚方法,最后使用基类引用调用各种派生类对象的方法,达到多种表现行为的效果:
2)接口继承式多态。
接口继承式多态不需要虚方法的参与,在代码Code 12-3的基础上编写如下代码:
1 //Code 12-5
2 class Program
3 {
4 static void Main()
5 {
6 Console.Title = "Walk";
7 IWalkable iw = new People();
8 iw.Walk(); //NO.1
9 iw = new Dog();
10 iw.Walk(); //NO.2
11 Console.Read();
12 }
13 }
如上代码Code 12-5所示,对于同一行代码"iw.Walk();"的两次调用(NO.1和NO.2处),有不同的表现行为:
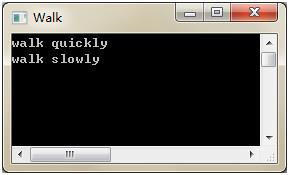
图12-8 接口继承式多态
在面向对象编程中,多态的前提是继承,而继承的前提是封装,三者缺一不可。多态也是是降低代码依赖的有力保障,详见本章后续有关内容。
12.2 不可避免的代码依赖
本书前面章节曾介绍过,程序的执行过程就是方法的调用过程,有方法调用,必然会促使对象跟对象之间产生依赖,除非一个对象不参与程序的运行,这样的对象就像一座孤岛,与其它对象没有任何交互,但是这样的对象也就没有任何存在价值。因此,在我们的程序代码中,任何一个对象必然会与其它一个甚至更多个对象产生依赖关系。
12.2.1 依赖存在的原因
"方法调用"是最常见产生依赖的原因,一个对象与其它对象必然会通信(除非我们把所有的代码逻辑全部写在了这个对象内部),通信通常情况下就意味着有方法的调用,有方法的调用就意味着这两个对象之间存在依赖关系(至少要有其它对象的引用才能调用方法),另外常见的一种产生依赖的原因是:继承,没错,继承虽然给我们带来了非常大的好处,却也给我们带来了代码依赖。依赖产生的原因大概可以分以下四类:
1)继承;
派生类继承自基类,获得了基类的全部内容,但同时,派生类也受控于基类,只要基类发生改变,派生类一定发生变化:
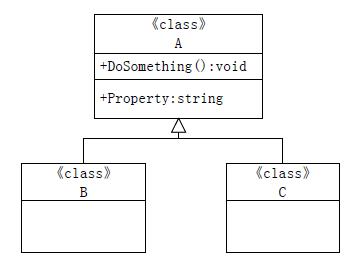
图12-9 继承依赖
上图12-9中,B和C继承自A,A类改变必然会影响B和C的变化。
2)成员对象;
一个类型包含另外一个类型的成员时,前者必然受控于后者,虽然后者的改变不一定会影响到前者:
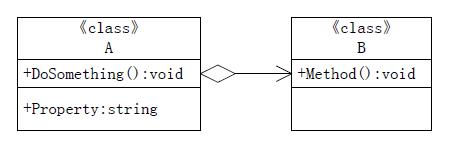
图12-10 成员对象依赖
如上图12-10,A包含B类型的成员,那么A就受控于B,B在A内部完全可见。
注:成员对象依赖跟组合(聚合)类似。
3)传递参数;
一个类型作为参数传递给另外一个类型的成员方法,那么后者必然会受控于前者,虽然前者的改变不一定会影响到后者:

图12-11 传参依赖
如上图12-11,A类型的方法Method()包含一个B类型的参数,那么A就受控于B,B在A的Method()方法可见。
4)临时变量。
任何时候,一个类型将另外一个类型用作了临时变量时,那么前者就受控于后者,虽然后者的改变不一定会影响到前者:
1 //Code 12-6
2 class A
3 {
4 public void DoSomething()
5 {
6 //…
7 }
8 }
9 class B
10 {
11 public void DoSomething()
12 {
13 //…
14 A a = new A();
15 a.DoSomething();
16 //…
17 }
18 }
如上代码Code 12-6,B的DoSomething()方法中使用了A类型的临时对象,A在B的DoSomething()方法中局部范围可见。
通常情况下,通过被依赖者在依赖者内部可见范围大小来衡量依赖程度的高低,原因很简单,可见范围越大,说明访问它的概率就越大,依赖者受影响的概率也就越大,因此,上述四种依赖产生的原因中,依赖程度按顺序依次降低。
12.2.2 耦合与内聚
为了衡量对象之间依赖程度的高低,我们引进了"耦合"这一概念,耦合度越高,说明对象之间的依赖程度越高;为了衡量对象独立性的高低,我们引进了"内聚"这一概念,内聚性越高,说明对象与外界交互越少、独立性越强。很明显,耦合与内聚是两个相互对立又密切相关的概念。
注:从广义上讲,"耦合"与"内聚"不仅适合对象与对象之间的关系,也适合模块与模块、系统与系统之间的关系,这跟前面讲"封装"时强调"封装"不仅仅指代码层面上的道理一样。
"模块功能集中,模块之间界限明确"一直是软件设计追求的目标,软件系统不会因为需求的改变、功能的升级而不得不大范围修改原来已有的源代码,换句话说,我们在软件设计中,应该严格遵循"高内聚、低耦合"的原则。下图12-12显示一个系统遵循该原则前后:
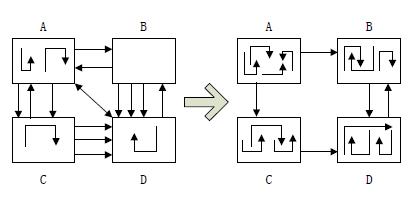
图12-12 高内聚、低耦合
如上图12-12所示,"高内聚、低耦合"强调对象与对象之间(模块与模块之间)尽可能多地降低依赖程度,每个对象(或模块,下同)尽可能提高自己的独立性,这就要求它们各自负责的功能相对集中,代码结构由"开放"转向"收敛"。
"职责单一原则(SRP)"是提高对象内聚性的理论指导思想之一,它建议每个对象只负责某一个(一类)功能。
12.2.3 依赖造成的"尴尬"
如果在软件系统设计初期,没有合理地降低(甚至避免)代码间的耦合,系统开发后期往往会遇到前期不可预料的困难。下面举例说明依赖给我们造成的"尴尬"。
假设一个将要开发的系统中使用到了数据库,系统设计阶段确定使用SQL Server数据库,按照"代码模块化可以提高代码复用性"的原则,我们将访问SQL Server数据库的代码封装成了一个单独的类,该类只负责访问SQLServer数据库这一功能:
1 //Code 12-7
2 class SQLServerHelper //NO.1
3 {
4 //…
5 public void ExcuteSQL(string sql)
6 {
7 //…
8 }
9 }
10 class DBManager //NO.2
11 {
12 //…
13 SQLServerHelper _sqlServerHelper; //NO.3
14 public DBManager(SQLServerHelper sqlServerHelper)
15 {
16 _sqlServerHelper = sqlServerHelper;
17 }
18 public void Add() //NO.4
19 {
20 string sql = "";
21 //…
22 _sqlServerHelper.ExcuteSQL(sql);
23 }
24 public void Delete() //NO.5
25 {
26 string sql = "";
27 //…
28 _sqlServerHelper.ExcuteSQL(sql);
29 }
30 public void Update() //NO.6
31 {
32 string sql = "";
33 //…
34 _sqlServerHelper.ExcuteSQL(sql);
35 }
36 public void Search() //NO.7
37 {
38 string sql = "";
39 //…
40 _sqlServerHelper.ExcuteSQL(sql);
41 }
42 }
如上代码Code 12-7所示,定义了一个SQL Server数据库访问类SQLServerHelper(NO.1处),该类专门负责访问SQL Server数据库,如执行sql语句(其它功能略),然后定义了一个数据库管理类DBManager(NO.2处),该类负责一些数据的增删改查(NO.4、NO.5、NO.6以及NO.7处),同时该类还包含一个SQLServerHelper类型成员(NO.3处),负责具体SQL Server数据库的访问。SQLServerHelper类和DBManager类的关系见下图12-13:
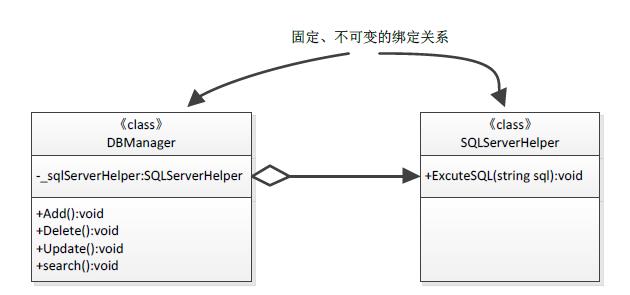
图12-13 依赖于具体
如上图12-13所示,DBManager类依赖于SQLServerHelper类,后者在前者内部完全可见,当DBManager需要访问SQL Server数据库时,可以交给SQLServerHelper类型成员负责,到此为止,这两个类型合作得非常好,但是,现在如果我们对数据库的需求发生变化,不再使用SQL Server数据库,而要求更改使用mysql数据库,那么我们需要做些什么工作呢?和之前一样,我们需要定义一个MySQLHelper类来负责MySQL数据库的访问,代码如下:
1 //Code 12-8
2 class MySQLHelper
3 {
4 //…
5 public void ExcuteSQL(string sql)
6 {
7 //…
8 }
9 }
如上代码Code 12-8,定义了一个专门访问MySQL数据库的类型MySQLHelper,它的结构跟SQLServerHelper相同,接下来,为了使原来已经工作正常的系统重新适应于MySQL数据库,我们还必须依次修改DBManager类中所有对SQLServerHelper类型的引用,将其全部更新为MySQLHelper的引用。如果只是一个DBManager类使用到了SQLServerHelper的话,整个更新工作量还不算非常多,但如果程序代码中还有其它地方使用到了SQLServerHelper类型的话,这个工作量就不可估量,除此之外,我们这样做出的所有操作完全违背了软件设计中的"开闭原则(OCP)",即"对扩展开放,而对修改关闭"。很明显,我们在增加新的类型MySQLHelper时,还修改了系统原有代码。
出现以上所说问题的主要原因是,在系统设计初期,DBManager这个类型依赖了一个具体类型SQLServerHelper,"具体"就意味着不可改变,同时也就说明两个类型之间的依赖关系已经到达了"非你不可"的程度。要解决以上问题,需要我们在软件设计初期就做出一定的措施,详见下一小节。
12.3 降低代码依赖
上一节末尾说到了代码依赖给我们工作带来的麻烦,还提到了主要原因是对象与对象之间(模块与模块,下同)依赖关系太过紧密,本节主要说明怎样去降低代码间的依赖程度。
12.3.1 认识"抽象"与"具体"
其实本书之前好些地方已经出现过"具体"和"抽象"的词眼,如"具体的类型"、"依赖于抽象而非具体"等等,到目前为止,本书还并没有系统地介绍这两者的具体含义。
所谓"抽象",即"不明确、未知、可改变"的意思,而"具体"则是相反的含义,它表示"确定、不可改变"。我们在前面讲"继承"时就说过,派生类继承自基类,就是一个"抽象到具体"的过程,比如基类"动物(Animal)"就是一个抽象的事物,而从基类"动物(Animal)"派生出来的"狗(Dog)"就是一个具体的事物。抽象与具体的关系如下图12-14:
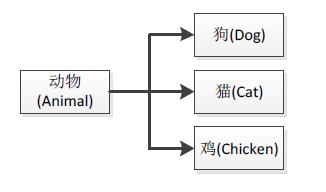
图12-14 抽象与具体的相对性
注:抽象与具体也是一个相对的概念,并不能说"动物"就一定是一个抽象的事物,它与"生物"进行比较,就是一个相对具体的事物,同理"狗"也不一定就是具体的事物,它跟"哈士奇"进行比较,就是一个相对抽象的概念。
在代码中,"抽象"指接口、以及相对抽象化的类,注意这里相对抽象化的类并不特指"抽象类"(使用abstract关键字声明的类),只要一个类型在族群层次中比较靠上,那么它就可以算是抽象的,如上面举的"动物(Animal)"的例子;"具体"则指从接口、相对抽象化的类继承出来的类型,如从"动物(Animal)"继承得到的"狗(Dog)"类型。代码中抽象与具体的举例见下表12-1:
表12-1 抽象与具体举例
|
序号 |
抽象 |
具体 |
说明 |
|
1 |
Interface IWalkable { void Walk(); } |
class Dog:IWalkable { public void Walk() { //… } } |
IWalkable接口是"抽象",实现IWalkable接口的Dog类是"具体"。 |
|
2 |
class Dog:IWalkable { public void Walk() { //… } } |
class HaShiQi:Dog { //… } |
Dog类是"抽象",继承自Dog类的HaShiQi类则是"具体"。 |
如果一个类型包含一个抽象的成员,比如"动物(Animal)",那么这个成员可以是很多种类型,不仅可以是"狗(Dog)",还可以是"猫(Cat)"或者其它从"动物(Animal)"派生的类型,但是如果一个类型包含一个相对具体的成员,比如"狗(Dog)",那么这个成员就相对固定,不可再改变。很明显,抽象的东西更易改变,"抽象"在降低代码依赖方面起到了重要作用。
12.3.2 再看"依赖倒置原则"
本书前面章节在讲到"依赖倒置原则"时曾建议我们在软件设计时:
1)高层模块不应该直接依赖于低层模块,高层模块和低层模块都应该依赖于抽象;
2)抽象不应该依赖于具体,具体应该依赖于抽象。
抽象的事物不确定,一个类型如果包含一个接口类型成员,那么实现了该接口的所有类型均可以成为该类型的成员,同理,方法传参也一样,如果一个方法包含一个接口类型参数,那么实现了该接口的所有类型均可以作为方法的参数。根据"里氏替换原则(LSP)"介绍的,基类出现的地方,派生类均可以代替其出现。我们再看本章12.2.3小节中讲到的"依赖造成的尴尬",DBManager类型依赖一个具体的SQLServerHelper类型,它内部包含了一个SQLServerHelper类型成员,DBManager和SQLServerHelper之间产生了一个不可变的绑定关系,如果我们想将数据库换成MySQL数据库,要做的工作不仅仅是增加一个MySQLHelper类型。假设在软件系统设计初期,我们将访问各种数据库的相似操作提取出来,放到一个接口中,之后访问各种具体数据库的类型均实现该接口,并使DBManager类型依赖于该接口:
1 //Code 12-9
2 interface IDB //NO.1
3 {
4 void ExcuteSQL(string sql);
5 }
6 class SQLServerHelper:IDB //NO.2
7 {
8 //…
9 public void ExcuteSQL(string sql)
10 {
11 //…
12 }
13 }
14 class MySQLHelper:IDB //NO.3
15 {
16 //…
17 public void ExcuteSQL(string sql)
18 {
19 //…
20 }
21 }
22 class DBManager //NO.4
23
24 {
25 //…
26 IDB _dbHelper; //NO.5
27 public DBManager(IDB dbHelper)
28 {
29 _dbHelper = dbHelper;
30 }
31 public void Add() //NO.6
32 {
33 string sql = "";
34
35 //…
36
37 _dbHelper.ExcuteSQL(sql);
38
39 }
40
41 public void Delete() //NO.7
42 {
43 string sql = "";
44 //…
45 _dbHelper.ExcuteSQL(sql);
46 }
47 public void Update() //NO.8
48 {
49 string sql = "";
50 //…
51 _dbHelper.ExcuteSQL(sql);
52 }
53 public void Search() //NO.9
54 {
55 string sql = "";
56 //…
57 _dbHelper.ExcuteSQL(sql);
58 }
59 }
如上代码Code 12-9所示,我们将访问数据库的方法放到了IDB接口中(NO.1处),之后所有访问其它具体数据库的类型均需实现该接口(NO.2和NO.3处),同时DBManager类中不再包含具体SQLServerHelper类型引用,而是依赖于IDB接口(NO.5处),这样一来,我们可以随便地将SQLServerHelper或者MySQLHelper类型对象作为DBManager的构造参数传入,甚至我们还可以新定义其它数据库访问类,只要该类实现了IDB接口,
1 //Code 12-10
2 class OracleHelper:IDB //NO.1
3 {
4 //…
5 public void ExcuteSQL(string sql)
6 {
7 //…
8 }
9 }
10 class Program
11 {
12 static void Main()
13 {
14 DBManager dbManager = new DBManager(new OracleHelper()); //NO.2
15 }
16 }
如上代码Code 12-10,如果系统需要使用Oracle数据库,只需新增OracleHelper类型即可,使该类型实现IDB接口,不用修改系统其它任何代码,新增加的OracleHelper能够与已有代码合作得非常好。
修改后的代码中,DBManager不再依赖于任何一个具体类型,而是依赖于一个抽象接口IDB,见下图12-15:
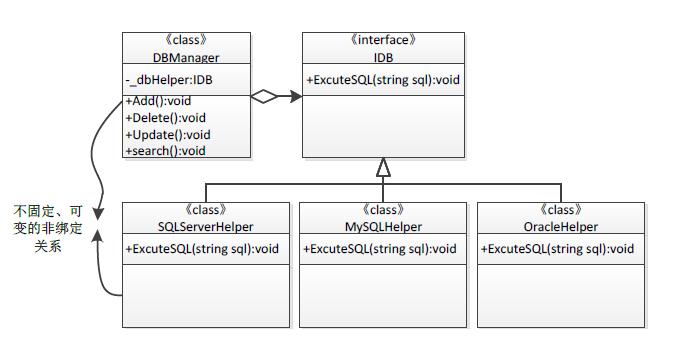
图12-15 依赖于抽象
如上图12-15,代码修改之前,DBManager直接依赖于具体类型SQLServerHelper,而代码修改后,DBManager依赖于一个"抽象",也就是说,被依赖者不确定是谁,可以是SQLServerHelper,也可以是其它实现了IDB的任何类型,DBManager与SQLServerHelper之间的依赖程度降低了。
理论上讲,任何一个类型都不应该包含有具体类型的成员,而只应该包含抽象类型成员;任何一个方法都不应该包含有具体类型参数,而只应该包含抽象类型参数。当然这只是理论情况,软件系统设计初期就已确定不会再改变的依赖关系,就不需要这么去做。
注:除了上面说到的将相同部分提取出来放到一个接口中,还有时候需要将相同部分提取出来,生成一个抽象化的基类,如抽象类。接口强调相同的行为,而抽象类一般强调相同的属性,并且用在有族群层次的类型设计当中。
12.3.3 依赖注入(DI)
当两个对象之间必须存在依赖关系时,"依赖倒置"为我们提供了一种降低代码依赖程度的思想,而"依赖注入(Dependency Injection)"为我们提供了一种具体产生依赖的方法,它强调"对象间产生依赖"的具体代码实现,是对象之间能够合作的前提。"依赖注入"分以下三种(本小节代码均以12.3.2小节中的代码为前提):
(1)构造注入(Constructor Injection);
通过构造方法,让依赖者与被依赖者产生依赖关系,
1 //Code 12-11
2 class DBManager
3 {
4 //…
5 IDB _dbHelper;
6 public DBManager(IDB dbHelper) //NO.1
7 {
8 _dbHelper = dbHelper;
9 }
10 public void Add()
11 {
12 string sql = "";
13 //…
14 _dbHelper.ExcuteSQL(sql);
15 }
16 //…
17 }
18 class Program
19 {
20 static void Main()
21 {
22 DBManager manager = new DBManager(new SQLServerHelper()); //NO.2
23 DBManager manager2 = new DBManager(new MySQLHelper()); //NO.3
24 DBManager manager3 = new DBManager(new OracleHelper()); //NO.4
25 }
26 }
如上代码Code 12-11所示,DBManager中包含一个IDB类型的成员,并通过构造方法初始化该成员(NO.1处),之后可以在创建DBManager对象时分别传递不同的数据库访问对象(NO.2、NO.3以及NO.4处)。
通过构造方法产生的依赖关系,一般在依赖者(manager、manager2以及manager3)的整个生命期中都有效。
注:虽然不能创建接口、抽象类的实例,但是可以存在它们的引用。
(2)方法注入(Method Injection);
通过方法,让依赖者与被依赖者产生依赖关系,
1 //Code 12-12
2 class DBManager
3 {
4 //…
5 public void Add(IDB dbHelper) //NO.1
6 {
7 string sql = "";
8 //…
9 dbHelper.ExcuteSQL(sql);
10 }
11 //…
12 }
13 class Program
14 {
15 static void Main()
16 {
17 DBManager manager = new DBManager();
18 //…
19 manager.Add(new SQLServerHelper()); //NO.2
20 //…
21 manager.Add(new MySQLHelper()); //NO.3
22 //…
23 manager.Add(new OracleHelper()); //NO.4
24 }
25 }
如上代码Code 12-12所示,在DBManager的方法中包含IDB类型的参数(NO.1处),我们在调用方法时,需要向它传递一些访问数据库的对象(NO.2、NO.3以及NO.4处)。
通过方法产生的依赖关系,一般在方法体内部有效。
(3)属性注入(Property Injection)。
通过属性,让依赖者与被依赖者产生依赖关系,
1 //Code 12-13
2 class DBManager
3 {
4 //…
5 IDB _dbHelper;
6 public IDB DBHelper //NO.1
7 {
8 get
9 {
10 return _dbHelper;
11 }
12 set
13 {
14 _dbHelper = value;
15 }
16 }
17 public void Add()
18 {
19 string sql = "";
20 //…
21 _dbHelper.ExcuteSQL(sql);
22 }
23 //…
24 }
25 class Program
26 {
27 static void Main()
28 {
29 DBManager manager = new DBManager();
30 //…
31 manager.DBHelper = new SQLServerHelper(); //NO.2
32 //…
33 manager.DBHelper = new MySQLHelper(); //NO.3
34 //…
35 manager.DBHelper = new OracleHelper(); //NO.4
36 //…
37 }
38 }
如上代码Code 12-13所示,DBManager中包含一个公开的IDB类型属性,在必要的时候,可以设置该属性(NO.2、NO.3以及NO.4处)的值。
通过属性产生的依赖关系比较灵活,它的有效期一般介于"构造注入"和"方法注入"之间。
注:在很多场合,三种依赖注入的方式可以组合使用,即我们可以先通过"构造注入"让依赖者与被依赖者产生依赖关系,后期再使用"属性注入"的方式更改它们之间的依赖关系。"依赖注入(DI)"是以"依赖倒置""为前提的。
12.4 框架的"代码依赖"
12.4.1 控制转换(IoC)
"控制转换(Inversion Of Control)"强调程序运行控制权的转移,一般形容在软件系统中,框架主导着整个程序的运行流程,如框架确定了软件系统主要的业务逻辑结构,框架使用者则在框架已有的基础上扩展具体的业务功能,为此编写的代码均由框架在适当的时机进行调用。
"控制转换"改变了我们对程序运行流程的一贯认识,程序不再受开发者控制,
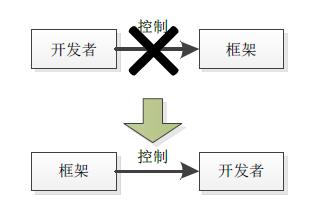
图12-16 程序控制权的转移
如上图12-16所示,框架负责调用开发者编写的代码,框架控制整个程序的运转。
注:"控制转换(IoC)、依赖倒置(DIP)以及依赖注入(DI)是三个不同性质的概念,"控制转换"强调程序控制权的转移,注重软件运行流程;"依赖倒置"是一种降低代码依赖程度的理论指导思想,它注重软件结构;"依赖注入"是对象之间产生依赖关系的一种具体实现方式,它注重编程实现。笔者认为有的书籍将三者做相等或者相似的比较是不准确的。
通常,又称"控制转换(IoC)"为"好莱坞原则(Hollywood Principle)",它建议框架与开发者编写代码之间的关系是:"Don\'t call us,we will call you.",即整个程序的主动权在框架手中。
12.4.2 依赖注入(DI)对框架的意义
框架与开发者编写的代码之间有"调用"与"被调用"的关系,所以避免不了依赖的产生,"依赖注入"是框架与开发者编写代码之间相结合的一种方式。任何一个框架的创建者不仅仅要遵循"依赖倒置原则",使创建出来的框架与框架使用者之间的依赖程度最小,还应该充分考虑两者之间产生依赖的方式。
注:"框架创建者"指开发框架的团队,"框架使用者"指使用框架开发应用程序的程序员。
12.5 本章回顾
本章首先介绍了面向对象的三大特征:封装、继承和多态,它们是面向对象的主要内容。之后介绍了面向对象的软件系统开发过程中不可避免的代码依赖,还提到了不合理的代码依赖给我们系统开发带来的负面影响,有问题就要找出解决问题的方法,随后我们从认识"具体"和"抽象"开始,逐渐地了解可以降低代码依赖程度的具体方法,在这个过程中,"依赖倒置(DIP)"是我们前进的理论指导思想,"高内聚、低耦合"是我们追求的目标。
12.6 本章思考
1.简述"面向对象"的三大特征。
A:从对象基础、对象扩展以及对象行为三个方面来讲,"面向对象(OO)"主要包含三大特征,分别是:封装、继承和多态。封装是前提,它强调代码模块化,将数据以及相关的操作组合成为一个整体,对外只公开必要的访问接口;继承是在封装的前提下,创建新类型的一种方式,它建议有族群关系的类型之间可以发生自上而下地衍生关系,处在族群底层的类型具备高层类型的所有特性;多态强调对象的多种表现行为,它是建立在继承的基础之上的,多态同时也是降低代码依赖程度的关键。
2.简述"面向抽象编程"的具体含义。
A:如果说"面向对象编程"教我们将代码世界中的所有事物均看成是一个整体——"对象",那么"面向抽象编程"教我们将代码中所有的依赖关系都建立在"抽象"之上,一切依赖均是基于抽象的,对象跟对象之间不应该有直接具体类型的引用关系。"面向接口编程"是"面向抽象编程"的一种。
3."依赖倒置原则(DIP)"中的"倒置"二字作何解释?
A:正常逻辑思维中,高层模块依赖底层模块是天经地义、理所当然的,而"依赖倒置原则"建议我们所有的高层模块不应该直接依赖于底层模块,而都应该依赖于一个抽象,注意这里的"倒置"二字并不是"反过来"的意思(即底层模块反过来依赖于高层模块),它只是说明正常逻辑思维中的依赖顺序发生了变化,把所有违背了正常思维的东西都称之为"倒置"。
4.在软件设计过程中,为了降低代码之间的依赖程度,我们遵循的设计原则是什么?我们设计的目标是什么?
A:有两大设计原则主要是为了降低代码依赖程度,即:单一职责原则(SRP)和依赖倒置原则(DIP)。我们在软件设计时追求的目标是:高内聚、低耦合。
作者:周见智
出处:http://www.cnblogs.com/xiaozhi_5638/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
以上是关于难免的尴尬:代码依赖的主要内容,如果未能解决你的问题,请参考以下文章