oracle 数据库体系结构
- - Oracle - 数据库 - ITeye博客 任何硬件平台或操作系统下的ORACLE体系结构都是相同的,包括如下四个方面:. 数据文件,日志文件,控制文件,参数文件. 表空间、段、区间、数据块. 共享池,数据缓冲区,日志缓冲区,PGA. 用户进程、服务器进程、后台进程.
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle如何比较两个表数据的差异?相关的知识,希望对你有一定的参考价值。
如有两张相同表结构的表:
test表:
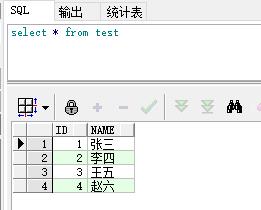
test1表:
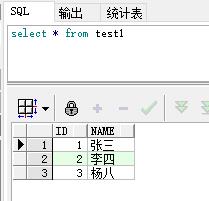
现在要找出两张表有差异的数据,需要用minus及union的方式查找出来,语句如下:
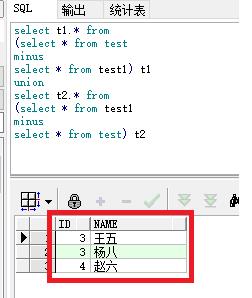
select t1.* from查询结果如下,红框部分的数据就是有差异的内容。
est表:
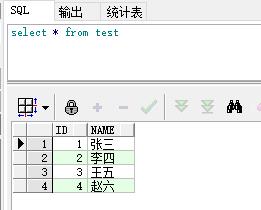
test1表:
现在要找出两张表有差异的数据,需要用minus及union的方式查找出来,语句如下:
select t1.* from(select * from testminusselect * from test1) t1union select t2.* from(select * from test1minusselect * from test) 1
select t1.* from
(select * from test
minus
select * from test1) t1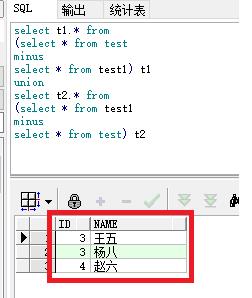
union
select t2.* from
(select * from test1
minus
select * from test) t2;
select t1.* from
(select * from test
minus
select * from test1) t1
union
select t2.* from
(select * from test1
minus
select * from test) t2;
红框部分的数据就是有差异的内容。
参考技术B select * from A minus select * from B;为了思考问题简单和方便测试,首先先建立两个测试表,并插入一些测试数据吧,sql如下:
create table t_A ( id VARCHAR2(36) not null, name VARCHAR2(100), age NUMBER, sex VARCHAR2(2) ); insert into t_A (id, name, age, sex) values (\'1\', \'1\', 1, \'1\'); insert into t_A (id, name, age, sex) values (\'2\', \'2\', 2, \'2\'); commit; create table t_B ( id VARCHAR2(36) not null, name VARCHAR2(100), age NUMBER, clazz VARCHAR2(36) ); insert into t_B (id, name, age, clazz) values (\'1\', \'1\', 1, \'1\'); insert into t_B (id, name, age, clazz) values (\'2\', \'2\', 1, \'3\'); insert into t_B (id, name, age, clazz) values (\'3\', \'3\', 3, \'3\'); commit;
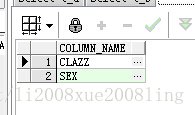
/*1.比较表结构 */
(select column_name
from user_tab_columns
where table_name = \'T_A\'
minus
select column_name
from user_tab_columns
where table_name = \'T_B\')
union
(select column_name
from user_tab_columns
where table_name = \'T_B\'
minus
select column_name
from user_tab_columns
where table_name = \'T_A\');
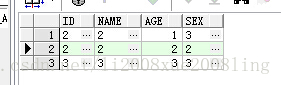
/* 2.比较表数据 */
(select *
from t_A
minus
select * from t_B)
union
(select *
from t_B
minus
select * from t_A)
看看sql的运行效果吧:
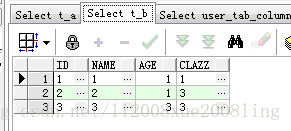
表t_A结构及数据:

表t_B结构及数据:
表结构差异:
数据差异:
反思:为什么我之前没想到用差集呢?
任何硬件平台或操作系统下的ORACLE体系结构都是相同的,包括如下四个方面:
物理结构
数据文件,日志文件,控制文件,参数文件。
逻辑结构
表空间、段、区间、数据块。
内存结构
共享池,数据缓冲区,日志缓冲区,PGA。
进程
用户进程、服务器进程、后台进程。 
SGA是共享内存区,PGA是私有内存区,用户对数据库发起的无论查询还是更新的任何操作,都是PGA预先处理,然后接下来才进入实例区域,
由SGA和系列后台进程共同完成用户发起的请求。
PGA的作用主要是三点
保存用户的连接信息,如会话属性,绑定变量等;
保存用户权限等重要信息;
做部分排序操作,如果放不下,就到临时表中完成,就是在磁盘中完成排序。
SGA
library cache
最主要的功能就是存放用户提交的SQL语句及相关的解析树(解析树也就是对SQL语句中所涉及的所有对象的展现)、执行计划、用户提交的PL/SQL程序块(包括匿名程序块、存储过程、包、函数等)以及它们转换后能够被Oracle执行的代码等。
也存放了很多的数据库对象的信息,包括表、索引等。有关这些数据库对象的信息都是从dictionary cache中获得的。如果用户对library cache中的对象信息进行了修改,比如为表添加了一个列等,则这些修改会返回到dictionary cache中。
软解析实验
alter system flush shared_pool; --- 禁止在公司测试环境使用
select owner,name,type,kept,sharable_mem,pins,locks,LOADS from v$db_object_cache where name like \'%dba_data_files%\'
SQL> select * from dba_data_files t where t.file_id=2;
已用时间: 00: 00: 00.04
执行计划
----------------------------------------------------------
Plan hash value: 1869944940
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 812 | 4 (0)| 00:00:01 |
| 1 | VIEW | DBA_DATA_FILES | 2 | 812 | 4 (0)| 00:00:01 |
| 2 | UNION-ALL | | | | | |
| 3 | NESTED LOOPS | | 1 | 395 | 2 (0)| 00:00:01 |
| 4 | MERGE JOIN CARTESIAN | | 1 | 380 | 1 (0)| 00:00:01 |
| 5 | NESTED LOOPS | | 1 | 70 | 1 (0)| 00:00:01 |
|* 6 | TABLE ACCESS BY INDEX ROWID | FILE$ | 1 | 31 | 1 (0)| 00:00:01 |
|* 7 | INDEX UNIQUE SCAN | I_FILE1 | 1 | | 0 (0)| 00:00:01 |
|* 8 | FIXED TABLE FIXED INDEX | X$KCCFE (ind:1) | 1 | 39 | 0 (0)| 00:00:01 |
| 9 | BUFFER SORT | | 1 | 310 | 1 (0)| 00:00:01 |
|* 10 | FIXED TABLE FULL | X$KCCFN | 1 | 310 | 0 (0)| 00:00:01 |
| 11 | TABLE ACCESS CLUSTER | TS$ | 1 | 15 | 1 (0)| 00:00:01 |
|* 12 | INDEX UNIQUE SCAN | I_TS# | 1 | | 0 (0)| 00:00:01 |
| 13 | NESTED LOOPS | | 1 | 471 | 2 (0)| 00:00:01 |
| 14 | NESTED LOOPS | | 1 | 456 | 1 (0)| 00:00:01 |
| 15 | MERGE JOIN CARTESIAN | | 1 | 365 | 1 (0)| 00:00:01 |
| 16 | NESTED LOOPS | | 1 | 55 | 1 (0)| 00:00:01 |
|* 17 | TABLE ACCESS BY INDEX ROWID| FILE$ | 1 | 16 | 1 (0)| 00:00:01 |
|* 18 | INDEX UNIQUE SCAN | I_FILE1 | 1 | | 0 (0)| 00:00:01 |
|* 19 | FIXED TABLE FIXED INDEX | X$KCCFE (ind:1) | 1 | 39 | 0 (0)| 00:00:01 |
| 20 | BUFFER SORT | | 1 | 310 | 1 (0)| 00:00:01 |
|* 21 | FIXED TABLE FULL | X$KCCFN | 1 | 310 | 0 (0)| 00:00:01 |
|* 22 | FIXED TABLE FIXED INDEX | X$KTFBHC (ind:1) | 1 | 91 | 0 (0)| 00:00:01 |
| 23 | TABLE ACCESS CLUSTER | TS$ | 1 | 15 | 1 (0)| 00:00:01 |
|* 24 | INDEX UNIQUE SCAN | I_TS# | 1 | | 0 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - filter("F"."SPARE1" IS NULL)
7 - access("F"."FILE#"=2)
8 - filter("FE"."FENUM"=2)
10 - filter("FNNAM" IS NOT NULL AND "FNFNO"=2 AND "FNTYP"=4 AND
"INST_ID"=USERENV(\'INSTANCE\') AND BITAND("FNFLG",4)<>4)
12 - access("F"."TS#"="TS"."TS#")
17 - filter("F"."SPARE1" IS NOT NULL)
18 - access("F"."FILE#"=2)
19 - filter("FE"."FENUM"=2)
21 - filter("FNNAM" IS NOT NULL AND "FNFNO"=2 AND "FNTYP"=4 AND
"INST_ID"=USERENV(\'INSTANCE\') AND BITAND("FNFLG",4)<>4)
22 - filter("HC"."KTFBHCAFNO"=2)
24 - access("HC"."KTFBHCTSN"="TS"."TS#")
统计信息
----------------------------------------------------------
151 recursive calls
1 db block gets
32 consistent gets
0 physical reads
0 redo size
1179 bytes sent via SQL*Net to client
338 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> /
已用时间: 00: 00: 00.00
执行计划
----------------------------------------------------------
Plan hash value: 1869944940
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 812 | 4 (0)| 00:00:01 |
| 1 | VIEW | DBA_DATA_FILES | 2 | 812 | 4 (0)| 00:00:01 |
| 2 | UNION-ALL | | | | | |
| 3 | NESTED LOOPS | | 1 | 395 | 2 (0)| 00:00:01 |
| 4 | MERGE JOIN CARTESIAN | | 1 | 380 | 1 (0)| 00:00:01 |
| 5 | NESTED LOOPS | | 1 | 70 | 1 (0)| 00:00:01 |
|* 6 | TABLE ACCESS BY INDEX ROWID | FILE$ | 1 | 31 | 1 (0)| 00:00:01 |
|* 7 | INDEX UNIQUE SCAN | I_FILE1 | 1 | | 0 (0)| 00:00:01 |
|* 8 | FIXED TABLE FIXED INDEX | X$KCCFE (ind:1) | 1 | 39 | 0 (0)| 00:00:01 |
| 9 | BUFFER SORT | | 1 | 310 | 1 (0)| 00:00:01 |
|* 10 | FIXED TABLE FULL | X$KCCFN | 1 | 310 | 0 (0)| 00:00:01 |
| 11 | TABLE ACCESS CLUSTER | TS$ | 1 | 15 | 1 (0)| 00:00:01 |
|* 12 | INDEX UNIQUE SCAN | I_TS# | 1 | | 0 (0)| 00:00:01 |
| 13 | NESTED LOOPS | | 1 | 471 | 2 (0)| 00:00:01 |
| 14 | NESTED LOOPS | | 1 | 456 | 1 (0)| 00:00:01 |
| 15 | MERGE JOIN CARTESIAN | | 1 | 365 | 1 (0)| 00:00:01 |
| 16 | NESTED LOOPS | | 1 | 55 | 1 (0)| 00:00:01 |
|* 17 | TABLE ACCESS BY INDEX ROWID| FILE$ | 1 | 16 | 1 (0)| 00:00:01 |
|* 18 | INDEX UNIQUE SCAN | I_FILE1 | 1 | | 0 (0)| 00:00:01 |
|* 19 | FIXED TABLE FIXED INDEX | X$KCCFE (ind:1) | 1 | 39 | 0 (0)| 00:00:01 |
| 20 | BUFFER SORT | | 1 | 310 | 1 (0)| 00:00:01 |
|* 21 | FIXED TABLE FULL | X$KCCFN | 1 | 310 | 0 (0)| 00:00:01 |
|* 22 | FIXED TABLE FIXED INDEX | X$KTFBHC (ind:1) | 1 | 91 | 0 (0)| 00:00:01 |
| 23 | TABLE ACCESS CLUSTER | TS$ | 1 | 15 | 1 (0)| 00:00:01 |
|* 24 | INDEX UNIQUE SCAN | I_TS# | 1 | | 0 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - filter("F"."SPARE1" IS NULL)
7 - access("F"."FILE#"=2)
8 - filter("FE"."FENUM"=2)
10 - filter("FNNAM" IS NOT NULL AND "FNFNO"=2 AND "FNTYP"=4 AND
"INST_ID"=USERENV(\'INSTANCE\') AND BITAND("FNFLG",4)<>4)
12 - access("F"."TS#"="TS"."TS#")
17 - filter("F"."SPARE1" IS NOT NULL)
18 - access("F"."FILE#"=2)
19 - filter("FE"."FENUM"=2)
21 - filter("FNNAM" IS NOT NULL AND "FNFNO"=2 AND "FNTYP"=4 AND
"INST_ID"=USERENV(\'INSTANCE\') AND BITAND("FNFLG",4)<>4)
22 - filter("HC"."KTFBHCAFNO"=2)
24 - access("HC"."KTFBHCTSN"="TS"."TS#")
统计信息
----------------------------------------------------------
0 recursive calls
1 db block gets
7 consistent gets
0 physical reads
0 redo size
1179 bytes sent via SQL*Net to client
338 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
1 rows processed
DICTIONARY CACHE
在内存中存放ORACLE数据库中常用的数据字典的信息,若此区域太小,当ORACLE需要某些数据字典信息,如对某用户的权限设置等信息时, 如果该信息不能在DICTIONARY CACHE中找到,则必须先通过物理读从ORACLE数据库的数据文件中得到该信息,然后再将该内存区域的部分信息替换出去
DB Buffer Cache
存放Oracle系统最近使用过的数据块。让他们能够在内存中进行操作。在这个级别里没有系统文件,用户数据文件,临时数据文件,回滚段文件之分。也就是任何文件的数据块都有可能被缓冲。数据库的任何修改都在该缓冲里完成,并由DBWR进程将修改后的数据写入磁盘。
刷新DB Buffer Cache实验
SQL> create table test_buffer as select * from dba_objects;
表已创建。
SQL> exec dbms_stats.gather_table_stats(user,\'test_buffer\');
表已分析。
SQL> select blocks,empty_blocks from dba_tables where table_name=\'TEST_BUFFER\' and owner=\'SYS\';
BLOCKS EMPTY_BLOCKS
---------- ------------
688 79
SQL> select count(*) from x$bh;
COUNT(*)
----------
8835
SQL> select count(*) from x$bh where state = 0;
COUNT(*)
----------
29
SQL> alter system set events = \'immediate trace name flush_cache\';
系统已更改。
SQL> select count(*) from x$bh where state = 0;
COUNT(*)
----------
8832
SQL> set autotrace traceonly
SQL> select count(*) from test_buffer;
执行计划
----------------------------------------------------------
Plan hash value: 2550671572
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 154 (2)| 00:00:02 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| TEST_BUFFER | 50081 | 154 (2)| 00:00:02 |
--------------------------------------------------------------------------
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
693 consistent gets
689 physical reads
0 redo size
410 bytes sent via SQL*Net to client
385 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> /
执行计划
----------------------------------------------------------
Plan hash value: 2550671572
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 154 (2)| 00:00:02 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| TEST_BUFFER | 50081 | 154 (2)| 00:00:02 |
--------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
693 consistent gets
0 physical reads
0 redo size
410 bytes sent via SQL*Net to client
385 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
Redo Log Buffer
重做日志文件的缓冲区,对数据库的任何修改都按顺序被记录在该缓冲,然后由LGWR进程将它写入Redo log files。这些修改信息包含DML语句以及DDL语句。 重做日志缓冲区的存在是因为内存到内存的操作比较内存到硬盘的速度快很多,所以重作日志缓冲区可以加快数据库的操作速度,但是考虑的数据库的一致性与可恢复性,数据在重做日志缓冲区中的滞留时间不会很长。
PMON(processes Mointor)
是进程监视器。如果执行某些更新语句,未提交时进程崩溃,这时PMON会自动回滚该操作,无需人工执行rollback命令。除此之外还可以干预后台进程,比如RECO异常失败了,此时PMON会重启RECO进程,如果遇到LGWR进程失败这种严重的问题,PMON会做出中止实例这个激烈的动作,用于防止数据错乱。
SMON(System Monitor)
系统监视器,与PMON不同的是,SMON关注的是系统级的操作而非单个进程,重点工作在于实例恢复,除此以外还有清理临时表空间、清理回滚段空间、合并空闲空间等。
CKPT(Checkpoint Process)
检查点进程。由Oracle的fast_start_mttr_target参数控制,用于触发DBWR从数据缓冲中写出数据到磁盘。CKPT执行越频繁,DBWR写出最频繁,性能越低,但数据库异常恢复的时候会越快。
RECO(Distributed Database Recovery)
用于分布式数据库恢复
DBWRn(Database Block Writer)
数据库块写入器是Oracle最核心的进程之一,负责把数据从数据缓存区写到磁盘,改进程和CKPT相辅相成,因为是CKPT促成DBWR去写的。不过DBWR也和LGWR密切相关,因为DBWR要想把数据缓存区数据写到磁盘时,必须通知LGWR先完成日志缓存区写到磁盘的动作后,方可开工。
1. PGA是用来排序的,当PGA空间不够时只有用磁盘排序,如果一个大排序不仅非常耗CPU,而且会影响其他的排序,就是影响其他的功能慢。想想我们系统中的排序,排序在设计或开发阶段就很随意,大的排序也不避讳。
2. DBWR写磁盘的前提条件是保证对应的redo已经写到磁盘,我们可以把最繁忙的进程LGWR写redo log放到最快的磁盘上,同时也可以提高commit的速度。
3. 避免循环commit提交。LGWR是单线程的顺序写,如果有大量的循环提交,那log buffer基本没有用处,大量commit排队提交,commit慢了造成锁释放慢,在系统大并发下,性能是不是有问题。
4. 如有一个很大的数据库,数据量庞大,访问量非常高,而共享池很小,会产生很多SQL硬解析,因为解析的SQL很快就被挤出共享池。
5. 如果你诊断一个数据库共享池总不够用,进一步发现硬解析很高,那就要用变量。
6. 上班时间导入数据和大量操作数据有什么影响?产生大量的redo,会影响其他功能慢。导出也会影响性能,以后再讲。
7. 在用as of timestap恢复数据的时候,发生快照失效,原因是什么,undo中没有改记录的改动了。如何解决,可以增大undo_retention,也可以增大undo表空间大小。
oracle数据库的整体结构
数据库的结构关系
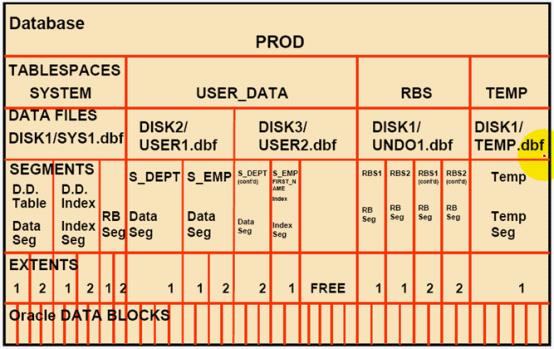
其实,我前面一篇讲表空间的时候就介绍了数据库的结构,只是那个图只是简单的层次关系,这张图片看上去挺封复杂的,只要关注几个概念就行了。
Database(数据库) :数据库是按照数据结构来组织、存储和管理数据的仓库。
Tablespaces(表空间) :表空间是数据库的逻辑划分,一个表空间只能属于一个数据库。所有的数据库对象都存放在指定的表空间中。但主要存放的对象是表, 所以称作表空间。
Segments (段): 段是表空间的重要组织结构,段是指占用数据文件空间的通称,或数据库对象使用的空间的集合;段可以有表段、索引段、回滚段、临时段和高速缓存段等。
extents (盘区):是数据库存储空间分配的一个逻辑单位,它由连续数据块所组成。第一个段是由一个或多个盘区组成。当一段中间所有空间已完全使用,oracle为该段分配一个新的范围。
Data Block (数据块):是oralce 管理数据文件中存储空间的单位,为数据库使用的I/O的最小单位,其大小可不同于操作系统的标准I/O块大小。
(Storage Clause Precedence)存储规范优先
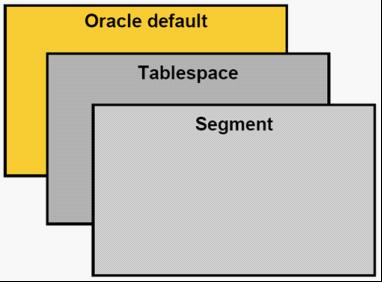
Oracle 在存储控制上可以分为三个方式。oracle缺省级别、表空间级别、段级别,可以理解中央、省级、县级。从中央到地方的法规条例。比如为了发展经济,对于招商引资的规范。中央规定可以实行招商引资,某省比较穷,为了吸引投资商,规定降低企业所得税。某县为了吸引资源,可以规定对于投资商土地免费使用5年,不征收土地使用税。那么某投资商来本县后首先适用县级规定。
具体规定:
1、不管你在哪个层面上修改存储方式,修改的参数是对未来要分配的存储extents (盘区)起作用。
2、一些参数只能在指定的级别上进行修改。有些参数只能表空间级别设置,有些参数只能在段级别设置。
Types of segments (段的类型)
因为关于表空间的一些基本知识我在另一节里做过专门介绍,这里我们认识一下段都有哪些常见类型。

Table :
对于一个只有几百条几千条数据,一个学校的学生成绩表,那么一张表就是一个segments 。
Table partition :
如果一张表非常大,里面存储了几千万条、上亿条记录,那么对这一张表进行操作,效率就非常低了。分区表是将大表的数据分成称为分区的许多小的子集。假如一张表是存放中国13亿人口信息的表,那么这么多条记录是有规律的,可以基于某一个字段将其分开。那么可以根据省级行政区可以划分34个分区,每个分区实际上就是一个独立的表,但在逻辑上这些分区又同属于一张表。
如果一张表是普通的表,只点一个segments;如果一张表是partition的表,可能占多个segments。
Cluster :
Oracle中普通的表称为堆表(heap table),堆表中的数据是无序存放的,往往在使用一段时间后,数据就变得非常无序。如下图所示,索引中相同的key对应的数据存放在不同的block中,这时,如果要通过索引查询某个key的数据,就需要访问很多不同的block,代价非常高。
我们发现很多表与表,他们的数据有相关性,因为我们访问一个表里的数据,往往要访问另一些表里的数据。我们可以把这些数据物理上存储在一块。
Index
索引是与表和聚集相关的一种选择结构,就当于我们一本书的目录,可以快快速的定位某章某节的页数。索引可以建立在一个表的一列或多列上,那就可以大大提高对表的查询。那么一个index也可能会占一个多个segments 。
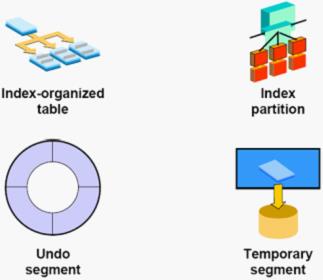
Index-organized table :
索引组织表(IOT),就是存储在一个索引结果中的表。存储在堆中的表是无组织的(也就是说,只要有可用的空间,数据可放在任何地方),IOT中 暗则按主键存储和排序。对你的应用来说,IOT表和一个“常规”表并无差别。使用堆组织表时,我们必须为表和表主键上的索引分别留出空间。而IOT不存在主键的空间开销,因为所引就是数据,数据就是所引。
IOT带来的好处不仅节约磁盘空间的占用,更重要的是大幅度降低了I/O,减少了访问缓冲区缓存(尽管从缓冲区缓存获取数据比硬盘要快得多,但缓冲区缓存并不是免费,而且也绝不是廉价的。第个缓冲区缓存获取都需要缓冲区缓存的多个闩,而闩是串行化设备,会限制应用的扩展能力)
Index partition
对于table有partition ,那么对一个大的index有也partition 。
分区所引可以分为全局分区索引与本地分区索引,其中本地索引又可以分为本地前缀索引和本地非前缀索引。
本地索引的分区和其对应的表分区数量相等,因此每个表分区都对应着相应的索引分区。使用本地索引,不需要指定分区范围因为索引对于表而言是本地的,当本地索引创建时,Oracle会自动为表中的每个分区创建独立的索引分区。
全局索引以整个表的数据为对象建立索引,索引分区中的索引条目既可能是基于相同的键值但是来自不同的分区,也可能是多个不同键值的组合。 全局索引既允许索引分区的键值和表分区键值相同,也可以不相同。全局索引和表之间没有直接的联系,这一点和本地索引不同。
Undo segment
回滚段用于存放数据修改之前的值(包括数据修改之前的位置和值)。回滚段的头部包含正在使用的该回滚段事务的信息。一个事务只能使用一个回滚段来存放它的回滚信息,而一个回滚段可以存放多个事务的回滚信息。
Temporary segment
当Oracle处理一个查询时,经常需要为 SQL语句的解析与执行的中间结果(intermediate stage)准备临时空间。Oracle会自动地分配被称为临时段(temporary segment)的磁盘空间。例如,Oracle在进行排序操作时就需要使用临时段。当排序操作可以在内存中执行,或Oracle设法利用索引就执行时,就不必创建临时段。
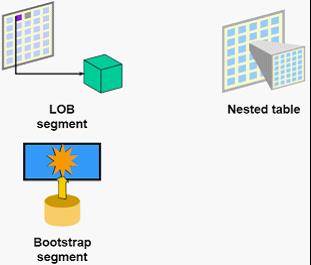
LOB segment
Large object (LOB) 大大的对象,我们知道数据库不但可以存数据,有些可以存储视频声音图片等文件,对于这种类型的文件一个大小几MB,几十MB很正常。当然,有些数据库是不支持LOB数据块的,可以在表里存一个指针,来指向某个文件下的视频声音文件。
Nested table
嵌套表,表中表,和LOB思想很类似,就是在表里存一个指针,指针指向另外一张表。
Bootstrap segment
关于引导段,暂时没找到相关解释。^_^
Extent alloc & dealloc (盘区分配与释放)
盘区是段下面的一个存储单位,一个盘区在物理上是一段连续的数据块。
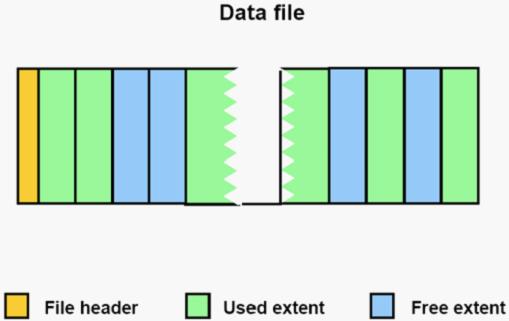
一个数据文件有一个文件头,点用了若干个数据块,这这个文件头里记录着盘区的分配与释放的信息。在这个文件中有些盘区是被使用的,有些盘区是空闲的。
什么时候创建盘区:
创建
扩展
改变(改大)
什么时候释放盘区:
删除
改变(改小)
Database Block(数据库块)
最小单位的输入/输出
数据块由操作系统中的一个或多个块组成
数据块是表空间的基本单位
DB_BLOCK_SIZE 文件来表示缺省块的大小
查看oracle 块的大小:
在早期的数据库中,oracle只支持一种数据块的大小。从9i版本支持了改变大小的设置。但也不是任用户随便改动的,规定范围在2KB到32KB之间,必须是倍数增加的,也就是2KB\\4KB\\8KB\\16KB\\32KB 五种大小。
需要注意的是,块大小的设置是在数据库创建时候设置的,一旦设置好是不可更改的。类似于我们磁盘的存储格式,FAT16、FAT32、NTFS.... ,要想改变存储格式只能数数据全部格式化掉。
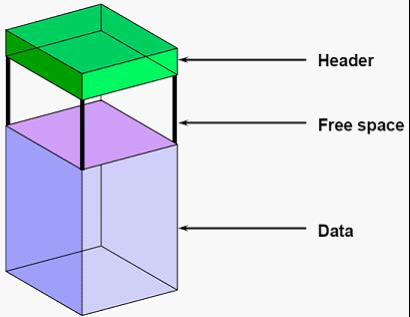
Hearder : 块头记录一些控制信息,帮助oracle定位这个块,块与块之间的串联信息。
Free space :处于重现状态的这空间。
Data :已经写入数据的空间。数据存放数据的方式是自底往上的,就像现实中的一个箱子。
Orcale 是如何管理数据的存储的
High-Water Mark

对一一个新建立的表,表中包含很多数据块,water mark 原始指向表中的第一个数据块。
water mark随着插入的数据“向前”移动。当把插入的数据删除掉一些,water mark 并不会“向后”移动。也就是water mark 的位置表示历史的最高水位。
那么我们要想插入一些数据时,oralce是按什么样的规则输选择插入位置呢?

首先会先查找灰色的,灰色部分表示就已经插入数据的块,但这些块并不是已经被完全占满了,有些或多或少的都会留下一些空间,关于留空间的规则,后面细说。如果插入一个很小的数据,灰色被占的数据块中可以完全插入的,就会被插在这一部分。
如果数据比较大,查找了所有被占用块都无法插入,那么将会选择“曾经”插入过数据的空白块进行插入,也就是上图浅灰色部分。
如果数据非常大,曾经插入数据的空白块都无法插入,那么只好动用从未被插入过数据的空白块进行插入。当然water mark 也就会“向前”移动。
OK下面就来具体分析,每个数据块,是否允许插入数据的规则。
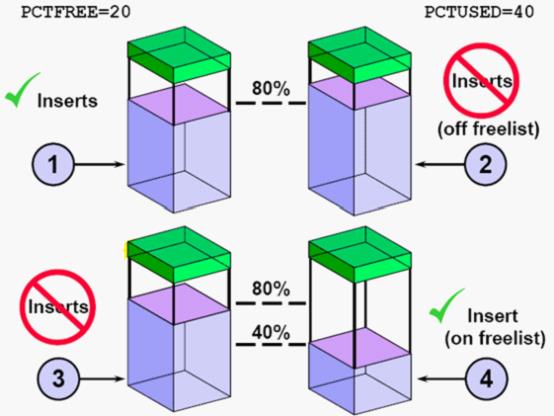
块头(数据块的头)不在百分比的范围内,当剩余空间大于20%的时候,那这个块就是纳入freelist中,当我要插入一条数据时,freelist是会扫描这个块的,检查其它是否可以存放要插入的数据。当小于20%的这间时,说明这个块已经满了,会从freelist中去掉,插入数据时不作为扫描的对象。
一个小于20%空闲的块会从freelist上摘除,那么一个块在什么情况下会被重新挂到freelist上呢?对于一个已经从freelist上摘除的块,可以能由于删除更新操作,其空间会得到释放,当占用空间小于40%时,也就是空闲空间大于60%时,这个块被有认为是空间的块又会被重现挂到freelist上。
原创文章,转载请注明: 文章地址 Oracle数据库分析函数详解
以上是关于oracle如何比较两个表数据的差异?的主要内容,如果未能解决你的问题,请参考以下文章