volatile synschonized的区别
Posted MakiseKurisu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了volatile synschonized的区别相关的知识,希望对你有一定的参考价值。
volatile synschonized的区别
synchronized
同步块大家都比较熟悉,通过 synchronized 关键字来实现,所有加上synchronized 和 块语句,在多线程访问的时候,同一时刻只能有一个线程能够用
synchronized 修饰的方法 或者 代码块。
volatile
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。volatile很容易被误用,用来进行原子性操作。
面试,被问到volatile与synschonized的区别
本文参考http://www.cnblogs.com/dolphin0520/p/3920373.html,
valitile这个关键词,不局限于java中,其实很多语言中都有这个关键词。由于自己之前对于多线程的编程接触比较少,而且对于java的内存模型不是很了解,所以今天做一个总结。
内存模型
现在想想大学那会学的操作系统真是太有用了,可惜当时没有认真学,很多编程的问题,都可以归结到操作系统,而且很多优秀的设计都是从操作系统来的。不说了,一把心酸泪。还是努力弥补吧。
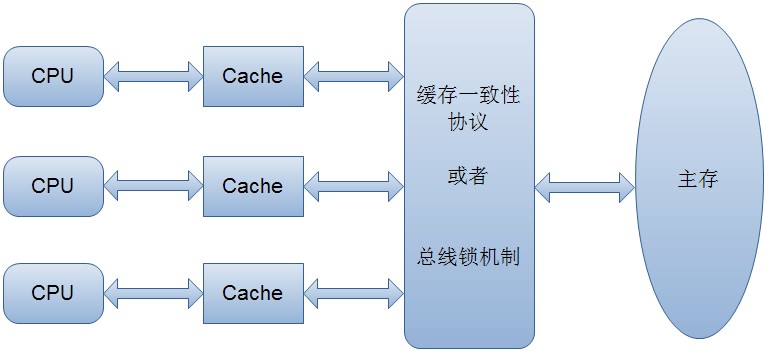
计算机的主要运算是由cpu,内存之间交互的,而他们之间的交互靠的是总线。但是由于cpu的速度远远大于内存的,所以在cpu旁边往往会设计一级二级缓冲,作用就是中和cpu与内存之间的速度。
但是让我们想想,如果程序是单线程的,基本没啥问题,因为数据不会存放着多个缓冲中,也就不涉及一致性的问题,但是当我们的程序里面有多线程的时候,可能不同的cpu会执行不同的线程,这样可能不同cpu的缓冲会持有同一个变量的不同副本,这样就有问题了。不同线程操作同一个变量,如何做到同步。
为了解决这个问题,那篇文章里面提到有两种方式。
1.在访问的时候,总线加锁,也就是相当于人为将多线程,变为单线程,这样不会出现数据不一致的问题,但是这样带来了很大问题,就是效率大打折扣,体现不出多线程的优势。
2.缓存一致性协议:
这里我就引用别人的一段话:“缓存一致性协议,最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变
量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的
缓存行是无效的,那么它就会从内存重新读取。”
最后附上一张图,来总结下上面说的。
多线程编程的概念
1.原子性:
这个概念在数据库里面也有,意思就是保证一个操作,要么完成,要不不做,而不能是做了一半。想必大家对这个最熟悉的应该就是银行的例子了吧。转账的时候,从我账户
扣款和给对方账户加款,应该是原子操作,不能说从我账户扣了,但是对方账户没有增加。这是在多线程里面必须要避免的问题。
2.可见性:
这个词的意思就是当一个线程在修改了某一个变量之后,可以马上将改变刷新到别的线程,也就是说如果别的线程需要访问的时候,是访问的修改过后的值。
3.有序性:
程序执行的顺序,不一定会按照代码书写的顺序进行执行。而是编译器会对代码进行指令的优化,这样做的目的是为了保证程序执行的效率。这样做基本上对于单线程没啥问
题,编译器保证做过优化后的代码和没做优化的代码,执行的结果是一样的。但是如果是多线程呢,这点编译器就无法保证。
综上所述,一个多线程如果要正确的执行,就必须满足上面三个条件。如果不满足,则执行的结果就有可能出错。
那么java里面通过什么样的方式来确保符合三种原则呢?
java保证多线程(java内存模型)
1.原子性:
在java中,对基本数据类型的读取与赋值是原子操作的,要不操作成功,要么失败。
那么怎么样的操作算原子操作呢,下面举两个例子:
int x = 3; int y = x; y++;
第一条语句,是直接将值复制给x变量。第二条语句,首先读取x的值,然后再赋值给y。第三条语句,首先读取y的值,然后加一操作后,再赋值给y。
所以上面三条语句只有第一条语句是原子操作。这也就解释了下面这段代码结果为啥不是人们的预期。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public volatile static int count = 0;public static void main(String[] args) { for(int i=0;i<10000;i++) { new Thread(new Runnable() { @Override public void run() { count++; } }).start(); } try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(count); } |
这段代码执行的结果有时候会小于10000,原因就是count++不是原子操作,虽然用volatile修饰,但是也不起作用。
那么上面这段代码如何正确运行呢,答案很显然,把count++变成原子操作即可,那么修改count的类型,如下
public static AtomicInteger count =new AtomicInteger(0);
将count++变为count.getAndIncrement();
这样保证了原子操作。结果也就是10000了。
2.可见性:
对于可见性,java提供了volatile关键词来修饰,上面已经用到过了。这个关键词保证他修改后的值,会马上更新到java的主存中,当其他线程再要读取的时候,就是读取的
新的值,但是用这个关键词的时候,也得多多注意,就跟上面说的那种情况,也是不行的。当然上面的情况可以用加锁,或者 synchronized方式进行同步。保证结果。
3.有序性:
Java里面也是通过volatile来保证一定程度上的有序性。也可以通过 synchonized来保证多线程下的有序性。
在《深入理解Java虚拟机》有这么一段话“
观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。”
所以以后遇到问题的时候,还是得多从原理里面找答案。
虽然volatile的性能比synchronized性能高,但是volatile的使用场景有所限制。因为它无法保证多线程下的原子性。
以上是关于volatile synschonized的区别的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch解决使用BucketIterator.splits警告volatile was removed and now has no effect. Use `with torch.no_g(代