垃圾回收算法分代回收
Posted qqwx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了垃圾回收算法分代回收相关的知识,希望对你有一定的参考价值。
分代垃圾回收,基于的是“大部分的对象,在生成后马上就会变成垃圾”这一经验上的事实为设计出发点。此前讨论过基于引事实的另一个垃圾回收算法,引用计数出的一些优化思路。
分代的关键是:
- 给对象记录下一个age,随着每一次垃圾回收,这个age会增加;
- 给不同age的对象分配不同的堆内内存空间,称为某一代;
- 对某一代的空间,有适合其的垃圾回收算法;
- 对每代进行不同垃圾回收,一般会需要一个额外的信息:即每代中对象被其他代中对象引用的信息。这个引用信息对于当前代来说,扮演与"root"一样的角色,也是本代垃圾回收的起点。
分代垃圾回收的典型是Ungar的分代垃圾回收。
它将堆分成如下形式:
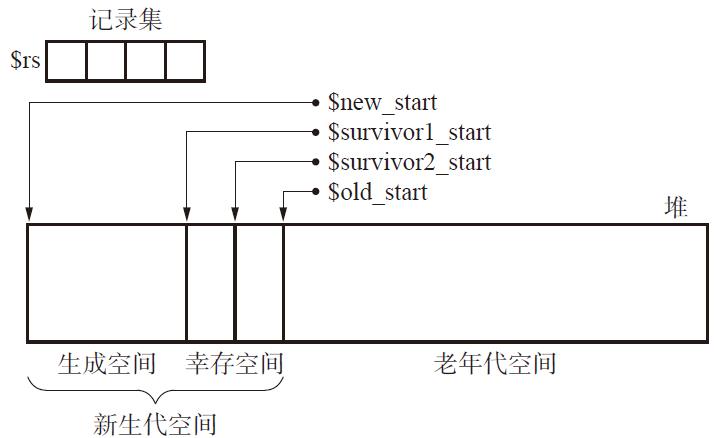
如上,分成新生代与老年代。
在新生代内,又分成了生成空间与幸存空间。当生成空间满了,会以复制算法进行垃圾回收,复制到幸存空间中。和前面的复制算法匹配,幸存空间又一分为二,分成from和to空间。每次新生代的垃圾回收,会同时进行生成空间到to、from空间到to的两个垃圾回收。
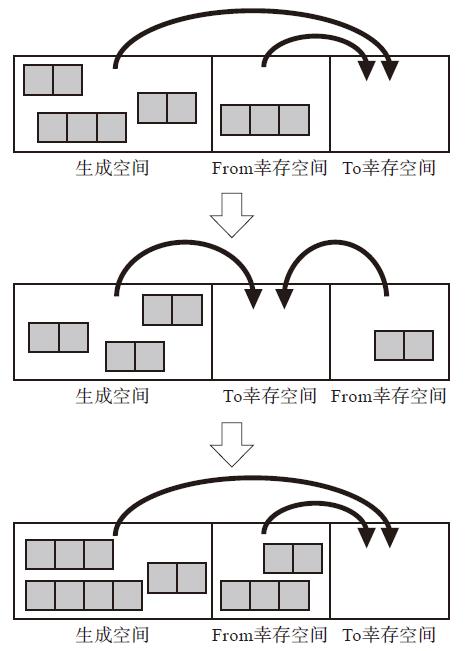
对于老年代,则直接进行mark_sweep回收。
对于“记录集”(record set),是记录代间引用的一个数组。它内部不能只记录被引用对象,因为被引用对象被复制到to空间后,引用者本身的引用指针要更新,只记录被引用的新生代内对象是无法找到被引用者的。所以,必须在记录集中记录老年代内对象。
更新记录集的操作在分配新对象,并设置成老对象的一个field时进行:
write_barrier(obj, field, new_obj) { if obj >= $old_start && new_obj < $old_start && obj.remembered == false // 条件,很明显 $rs[$rs_idx++] = obj // 更新记录集 obj.remembered = true // 这标记用于防止重复加入记录集 *field = new_obj // 最终更新 }
从上面可见,老年代的对象中,加了一个域:remembered,用来标记是否在新生代的记录集中,防止重复处理。
在分代垃圾回收的对象头中,还需要加入两个字段给新生代对象使用:
age:如上提到,是区分放在哪一代所用
forwarded:算法中用,判断是否已经复制过
forwarding要不要:也要。因为是原生复制算法,这字段不需要放头中,直接取一个域。
下面看具体算法:
分配算法,流程上很简单,不行时进行新生代的垃圾回收。注意相关头域的初始化:
new_obj(size) { if $new_free + size >=$survivor1_start minor_gc() // 后面重点介绍,新生代回收!!! if $new_free + size >=$survivor1_start fail() obj = $new_free $new_free += size // 下面是初始化 obj.age = 0 obj.forwarded = obj.remembered = false obj.size = size return obj }
上面忽略了一个错误,即分配一个大于新生代大小的超大对象。
在看新生代回收的逻辑前,先中断下思路,先看一下具体的copy流程:
copy(obj) { if obj.forwarded == false // 处理过的对象不关心,因为已经是垃圾了。 if obj.age < AGE_MAX // 判断拷到哪一代 copy_data($to_suvivor_free, obj, obj.size) obj.forwarded = true obj.forwarding = $to_suvivor_free $to_suvivor_free.age++ $to_suvivor_free += obj.size for child : children(obj.forwarding) // 注意是forwarding,原书上应该错了!拷贝并更新各子对象 child = copy(child) else promote(obj) // 升级 return obj.forwarding } promote(obj) { new_obj = allocate_in_old(obj) if new_obj == NULL major_gc() // mark_sweep,没什么好说 new_obj = allocate_in_old(obj) if new_obj == NULL fail() // 新生代内老对象上正常更新 obj.forwarding = new_obj obj.forwarded = true // 下面是关键,跨代复制后,需要更新记录集 for child : children(new_obj) if (child < $old_start) // 当前对象已经复制到老年代,一旦发现其中有一个子对象在新生代,更新新生代的记录集 $rs[$rs_idx++] = new_obj // 如前所说,记录集内记录的,必须是老年代中的对象 new_obj.remembered = true return // 只需要找到一个,就可以退出不再处理了 }
是时候回头看一下新生代GC了:
minor_gc() { $to_survivor_free = $to_survivor_start for r : $root // 复制算法,就是从根开始将有用的都拷走 if r < $old_start // 相对一般复制算法的区别,要判断分代 r = copy(r) // 另一个与正常复制算法的区别,是记录集中的老年代,也要当作根处理 i = 0 while i < $rs_idx has_new_obj = false for child : children($rs[i]) if child < $old_start // 找到了一个子对象在新生代,需要将其复制走 child = copy(child) if child < $old_start // 复制完仍在新生代(另一可能是,复制过程中,age满了被复制到老年代!) has_new_obj = true // 记录,意味着,当前这条记录集仍要保留 if has_new_obj == false // 需要将记录集中记录干掉 $rs[i].remembered = false $rs_idx-- swap($rs[i], $rs[$rs_idx]) else i++ swap($from_survivor_start, $to_suvivor_start) }
以上便是新生代回收算法。有一些额外逻辑,如to空间满了怎么办,直接拷到老年代也行。
至于老年代回收,不提了,就是mark_sweep
来看下好处:
优点:
- 吞吐量很好
缺点:
- 基于一个“很多对象年轻时会死掉”这样一个经验性的假设,一旦假设不成立,分代的整个基础都不稳,因为新生对象垃圾率没有想像的高,那么新生代会产生大量复制,同时老年代垃圾多,mark_sweep频繁运行。
- 写入屏障(更新记录集的操作)是一个额外的开销:每个对象会在记录集中占用内存(1字节?);且当它的运行时性能消耗大于新生代回收带来的好处时,分代回收也就失去意义。
- 老年代gc的mark_sweep,无可避免地,对于最大暂停时间有影响。
- 跨代的循环引用无法一次性回收(只能等新生代的对象年纪到了,放到老年代中才能得到处理)
对于write_barrier的开销,可以优化优化:比如,不记录对象级别的记录集,而是记录某一段内存的跨代引用。这样就可以以位图来记录,大幅减少内存开销。但同时就引入了在内存块中遍历的额外操作。总之都没法完美。
对于分代垃圾回收,也可以加以强化,不只分两代,而是分多代,也是个优化思路。
下面介绍一个解决第三个、第四个缺点的一个略复杂的算法:train GC
算法略复杂,引入train这个概念,正是为了使算法便于理解。实际上,是对于老年代内存进行了一次二维的划分,将垃圾回收的范围缩小到二维的某一“行”,同时,将具备引用关系的对象放到同一“行”中。
这里,“行”这概念,被抽象成了train,火车。每行中内存划的一个个分片,被抽象成car,车厢。
跨车厢与跨列车之间的引用,都有记录集。但因为垃圾回收只回收“第一个”火车,且从前到后回收不同车厢,因此记录集可以大大简化,不关心从前到后的跨引用。
首先,虽然是优化老年代的垃圾回收算法,但对于新生代,也有变化:在新生代复制中,不按age拷贝到新生代中了,而是直接拷入老年代(因为算法本身就是解决老年代回收效率问题,所以没必须在新生代中复制来复制去了)。复制到老年代,需要确定上文的二维坐标,即train和car。具体复制逻辑:
// 往老年代的某一car上复制,逻辑不复杂 copy(obj, to_car) { if obj.forwarded == false if to_car.free + obj.size >= to_car.start + CAR_SZ to_car = new_car(to_car) copy_data(to_car.free, obj, obj.size) obj.forwarding = to_car.free obj.forwarded = true to_car.free += obj.size for child : children(obj.forwarding) child = copy(child, to_car) // 引用关系的,都往同一car拷。后面可看到,即使car空间不足重分配,那也是在同一train内的。 return obj.forwarding }
再看是怎么调用的,怎么把引用关系的对象缕到一起的:
minor_gc() { // root引用的,就不管了,先拷到一个新car再说(老年代回收自会处理) to_car = new_car(NULL) // new_car(NULL)这个操作,不仅会创建新car,也会创建一个新train!!!!!!!!!!!!!!!!!!!! for r : $root if r < $old_start r = copy(r, to_car) // 从记录集引用来的,说明老年代中必有引用它的对象,直接找到对应车厢即可 for remembered_obj : $young_rs for child : children(remembered_obj) if child < $old_start to_car = get_last_car(obj_to_car(rememberd_obj)) //关键点:两个操作,1找到引用它的老年对象所在car,2找到对应car所在train的最后一个car child = copy(child, to_car) }
上面有一个逻辑要关注,从root引用的对象,是复制到新火车的,而从记录集引用的对象,是拷贝到引用所在的火车。
老年代的垃圾回收的思路是从前到后的,第一列车第一车厢的优先:
major_gc() { has_root_reference = false to_car = new_car(NULL) // 注意,新火车 // 先处理根出发的对象 for r : $roots if is_in_from_train(r) // 只处理这个from_train,这个from_train是第一个train has_root_reference = true // from_train中,存在着从根来的引用。这意味着,将它拷到train中的后面car后,本train仍然是被root引用的 if is_in_from_car(r) // 同样只处理from_car,这个from_car是from_train中的第一个car r = copy(r, to_car) // 移走到新火车中 // 处理到这里后,第一train中第一车厢的根引用的活动对象,都已经拷走,拷到新火车中! // 这里这个额外的判断,很重要 if !has_root_reference && is_empty(train_rs($from_car)) // 火车回收算法的核心逻辑:如果,本列车已经没有从根的引用,也没有从其他列车的引用,说明这是一整车垃圾,而不仅仅是一车厢!可以全部回收。循环引用也可以在这里被回收!!! reclaim_train($from_car) return // 处理从记录集出发的引用对象。如果有从其他火车的引用,要进行各种调整。 scan_rs(train_rs($from_car)) scan_rs(car_rs($from_car)) add_to_freelist($from_car) // 当前这from_car是可以回收了 $from_car = $from_car.next } // 火车算法的核心逻辑:将从记录集出发的引用对象归整到同一火车 scan_rs(rs) { for remembered_obj : rs for (child : rememberd_obj) if is_in_from_car(child) to_car = get_last_car(obj_to_car(remembered_obj)) // 移动到引用它对象同一个train child = copy(child, to_car) }
最后,看一下wirte_barrier
// 这里的操作是obj.field = new_obj这样的 write_barrier(obj, field, new_obj) { if obj >= $old_start if new_obj < $old_start // 老年代引用新生代,简单 add(obj, $young_rs) else // 老年代引用老年代,就有点逻辑 src_car = obj_to_car(obj) // 这里的src, dest是引用的关系 dest_car = obj_to_car(new_obj) if src_car.train_num > dest_car.train_num add(obj, train_rs(dest_car) else if src_car.car_num > dest_car.car_num add(obj, car_rs(dest_car) //上面两上不完全的判断条件看似漏了一些分支未处理,但其实是不需要处理的。因为垃圾回收过程从前往后进行,只会关心这里的两种从后往前的引用方式。 field = new_obj }
到这里有个疑问,通过源引用对象,将对象拷贝到源对象所在的列车中,那么,什么情况下,源引用对象与扫描对象会不在一个train中?上面minor已经提到了,new_car(NULL)时。具体是,不管处理新生代往老年代复制,还是老年代自己复制,只要是复制根引用对象时,都会新建立火车。这逻辑也正确,根出发的对象作“火车头”。
最后看一个示意图:
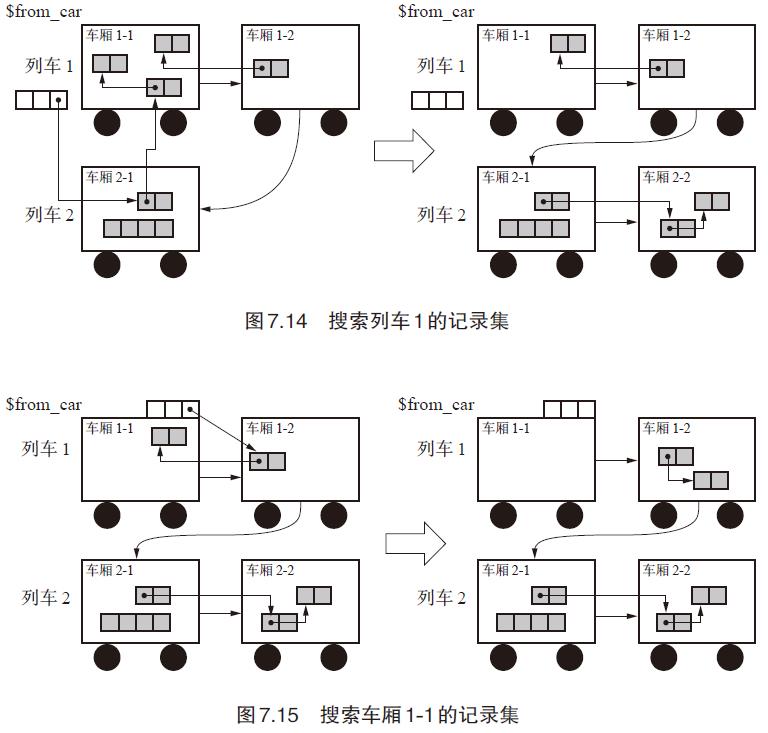
形象的表示了,如何处理不同火车和不同车厢的跨车厢记录集,最终使from_car全都拷贝走。
优点:
- 老年代的回收不会扫全堆,而是仅仅一车厢或,会使暂停时间很短;
- 循环垃圾一次性也可回收;
缺点:
- 吞吐量略差,因为计算记录集量大了。
以上是关于垃圾回收算法分代回收的主要内容,如果未能解决你的问题,请参考以下文章