loadrunner提高篇-block(块)技术和参数化
Posted 一加一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了loadrunner提高篇-block(块)技术和参数化相关的知识,希望对你有一定的参考价值。
Block(块)技术
block(块)技术是应用于在一个脚本中实现不同事务、不同次数循环或不同百分比循环的情况。比如在一个脚本中,登录执行3次,查询执行1次。
使用方法如下:
1、录制一个脚本,包含2个业务:登录和查询
2、vuser->run time settings->general->run logic,选择run,插入一个block块,然后选择block(),单击insert action按钮,选中要添加的action,如图1所示:
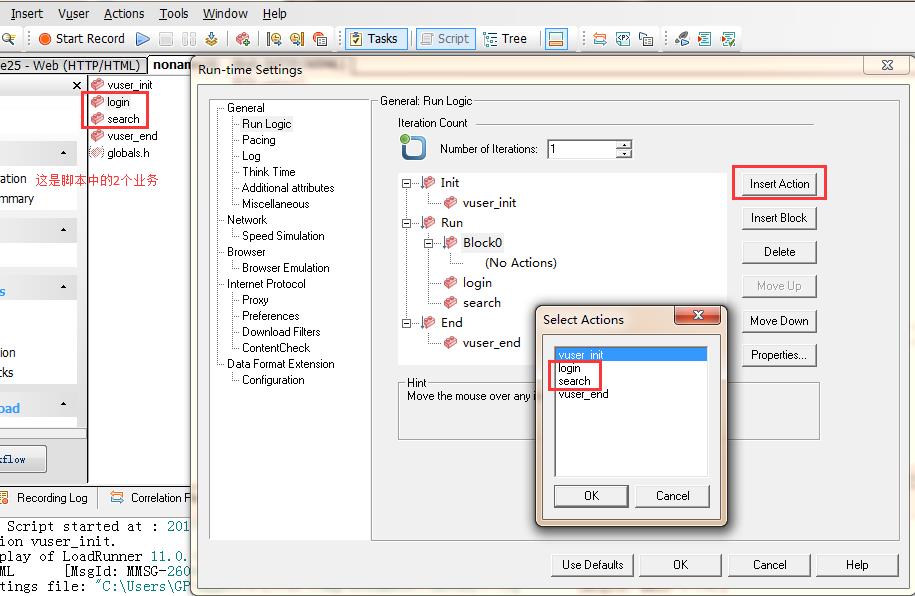
图1(为block添加action)
3、重复上面的操作,再新建一个block,然后删除block外的action,如图2所示:
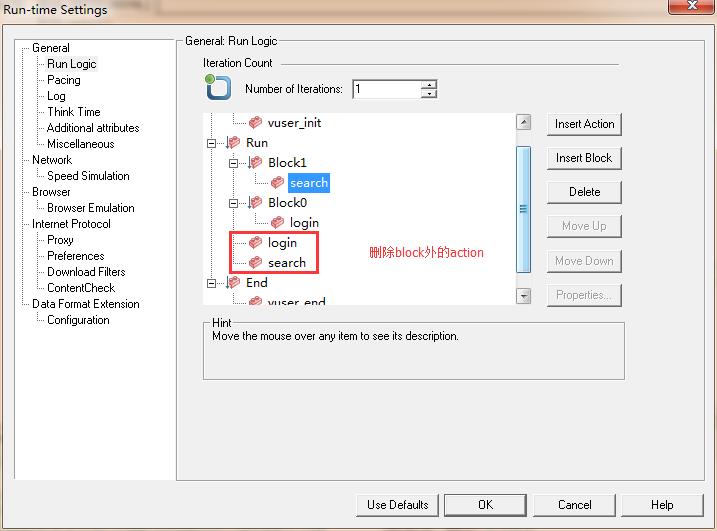
图2(删除block外面的action)
4、设置block properties,如图3所示:
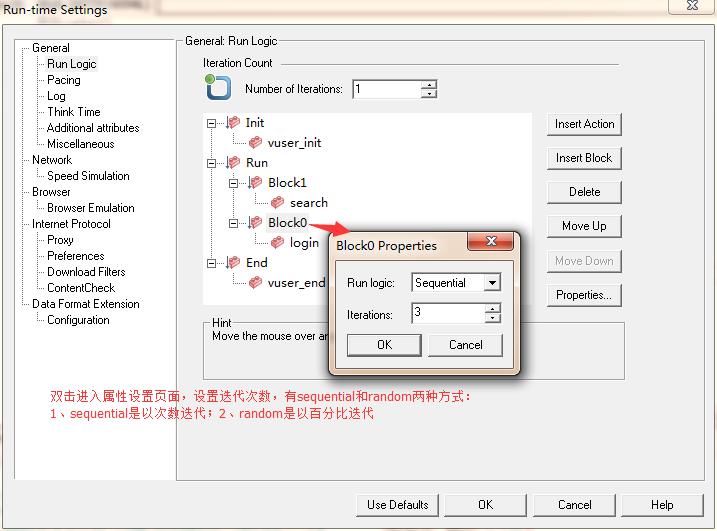
图3(block properties设置)
5、block(块)技术就是这样了,注意:事务迭代的总次数=该block迭代次数*number of iterations,如上图即是login迭代次数=3*1=3次。
参数化技术
一、参数化的原因及条件
脚本参数化就是针对脚本中的某些常量,使用参数来取代。参数化的过程体现了数据驱动的思想,即是将测试脚本和测试数据进行分离的思想,脚本体现测试流程,数据体现测试案例。
原因:可以减小脚本的数量;使业务更接近真实的客户业务,每个虚拟用户使用不同参数值来模拟,这样可以更好地接近客户的实际情况。
哪些需要进行参数化?
1)日期时间:例如录制一个订票业务流程,订票日期一定是当前日期之后,比如订的机票日期是17年4月1号,那么在该日期之后再来回放该脚本时,会发现脚本无法正常使用,所以这类情况需要参数化。
2)唯一性约束:是指在数据库中对于主键必须是唯一的,如果一起使用相同数据提交业务,那么业务将无法完成,比如注册业务就不能使用相同的数据进行注册,因为数据库中会把注册用户的ID作为主键。
3)数据约束:是指在测试过程中要求提交的业务数据必须是每次都不同,如果提交事务中的数据一致,那么事务将会失败。例如银行事务,一些银行事务是以报文的方式发送的,在发送报头时,后面一般会接一个6位的动态码,那么这个动态码就必须每次都不一样,如果写成一样,那么银行交易事务将会失败,所以对于这类数据必须进行参数化。
4)缓存数据约束:在谈缓存数据约束前,必须先了解数据库查询的过程,数据库在查询时首先使用查询条件在数据库中查询,查询结束后,系统需要将查询到的结果显示在页面中,那么显示时需要先将查询到的结果从硬盘中读取,读取后将数据从硬盘读到内存,再从内存读到缓存,最后将缓存中的数据发送到处理器中进行处理。但是有一种特殊情况,如果每次使用的查询条件一致时,数据库中查询到的结果就是一致的,那么需要处理的数据已经存储在缓存中,这样系统就不需要从硬盘将数据讲到缓存,而直接将缓存中的数据传输到处理器中进行处理,这样就节约了从硬盘读到缓存中的时间,而整个查询过程中时间消耗最多的恰好是从硬盘读到缓存的时间,所以这样测试出来的时间不是真实的时间,这时就出现缓存数据约束,所以这种情况也需要进行参数化。
二、创建参数
1、录制注册业务的脚本->选中要参数化的常量并右击,选择replace with a parameter->输入参数化名称,如图4所示:

图4(参数化命名)
2、参数化结束后,脚本保存的根目录下会自动生成一个参数化的文件,如图5所示:
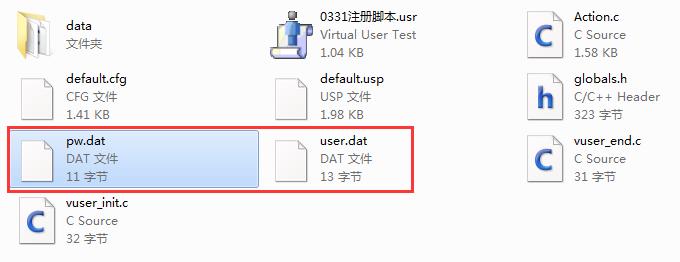
图5(参数化文件)
3、可对这2个文件进行合并,节省资源,合并后可以将pw和user2个文件删除,为了将参数和脚本分离,一般会新建一个参数文件夹,将所有参数文件都放到里面,如图6所示:
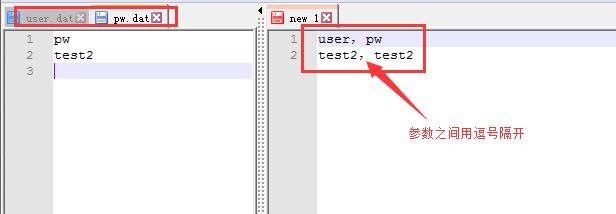

图6(合并参数文件与分离脚本、参数)
注:如果改变了参数文件路径后直接运行的话,会报错(error-13889),这时要进行参数类型属性设置,可看下面的内容。
三、参数类型属性
创建参数后,需要对参数类型属性进行设置,主要有以下几种参数类型:
1、date/time(日期/时间)参数类型,如图7所示:

图7(日期时间参数类型)
2、group name(组名)参数类型
用vuser组的名称替换参数。创建方案时,要指定vuser组的名称,否则运行脚本时,组名始终为“无”。
3、iteration number(迭代编号)参数类型
用当前的迭代编号替换参数,迭代编号的格式可以自己设置。
4、load generator name(负载发生器名)参数类型
用vuser脚本的负载发生器名替换参数,负载发生器是运行vuser的计算机。
5、random number(随机数)参数类型
用一个随机生成的整数替换参数,可以通过指定最小值和最大值,设置随机数的范围。
6、unique number(唯一数)参数类型
用一个唯一编号替换参数。start表示vuser从第几个参数开始使用;block size指明分配给每个vuser的编号块的大小;number数据类型表示产生的唯一的类型。
7、vuser id参数类型
使用该虚拟用户的ID来代替参数值,该ID由controller来控制,在vugen中运行脚本时,vugen将会是-1.
8、file(文件)参数类型
可以在参数属性中编辑参数文件,也可以直接选择已编辑好的参数文件,还可以从现成的数据库中提取(这是最常用的一种参数化方式),下面的内容会详细介绍。
四、数据文件
参数的数据源可以来自于真实的历史数据也可以是自行构建的数据,参数中的数据如何调用也是需要设置的。
1、browse属性:如果修改过参数文件路径,则需要在这里重新选择,否则无法读到参数文件中的参数(会报错error-13889),如图8所示:
注:如果设置的是绝对路径的话,那么脚本移植到另的机器上运行时会报错,因为脚本的路径发生了变化,所以最好的方法就是采用相对路径,将脚本的根目录使用“.”来代替。
(比如绝对路径:E:\\loadrunner\\0331参数化\\0331注册脚本\\parameter\\parameter;则相对路径:.\\parameter\\parameter)
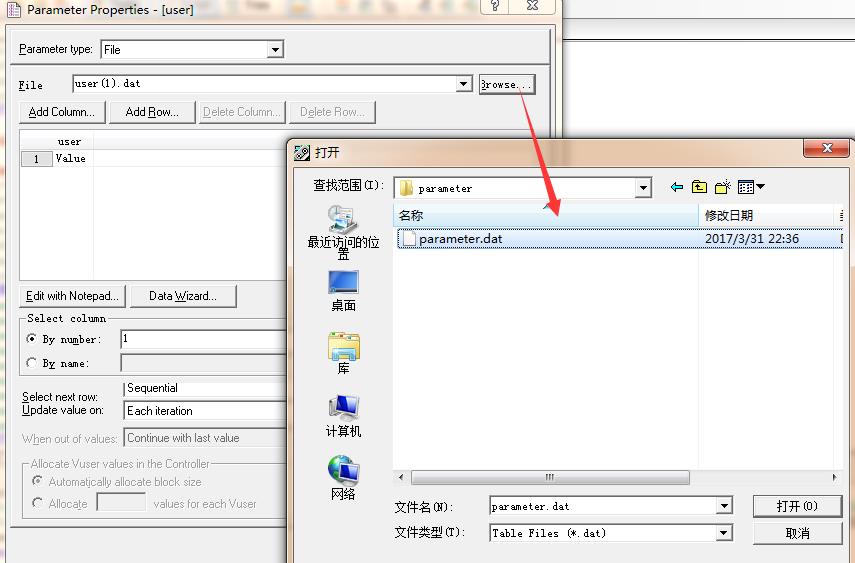
图8(选择参数化文件)
2、edit with notepad设置:打开记事本,可在记事本中对参数值进行修改、添加或删除。
3、select column设置:指明参数选择的列,可按列号(包含所需要数据的列的索引),也可按列名。
4、column delimiter设置:选择列分隔符,一般是选择逗号。
5、file data line设置:在脚本执行时选择第几行数据开始使用。如果选择从列标题后的第一行参数开始执行,就输入1。
6、select next row设置:该属性都是针对虚拟用户来说的,即这里的策略是针对controller设置的,在调试脚本的过程中是看不出来的,其决定虚拟用户选择参数的过程。
when out of values:表示当参数不够时如何处理
1)abort vuser:忽略剩下所有的虚拟用户不再运行
2)continue in a cyclic manner:将参数继续循环一次,虚拟用户按顺序参数进行迭代
3)continue with last value:一直使用最后一个数据进行后面的迭代
allocate vuser values in the controller:指在控制器运行时,如何分配这些参数
1)由LR自动分配每个虚拟用户使用的参数情况
2)为每个虚拟用户所设置的虚拟用户数。假如设置为20,那么第一个虚拟用户使用的参数为1-20,第二个则为21-40。(注:不要将该值设置为参数的总数)
*same link as ..:与某个已定义好的参数取同一行值,该方法要求至少其中的一个参数必须是sequential、random、unique
比如将参数PW\'select next row\'设置为’same line as user‘,当user选择test2时,那么参数pw只能选择跟它同一行的值
7、update value on设置:设置脚本迭代过程中取值的策略,其结果可以在代码调试的日志中体现。
1)each iteration:脚本每迭代一次都访问数据表中的下一个值,即在同一次迭代中,不管同一个参数出现多少次都只使用这一个参数
2)each occurrence:在每次迭代过程中,参数的值都更新,即使在同一次迭代过程,如果某个参数使用了多次,其选择的值也会更新而不会使用相同的参数值。
3)once:在同一个vuser中一直取同一个参数,表中其他的数据不参与迭代的过程
五、导入数据
如果在事务中希望参数是来自实际的数据,那么LR允许利用参数化从已经存在的数据中导入数据。提供microsoft query、指定数据库连接字符串和SQL语句 两种方式,如图9所示:
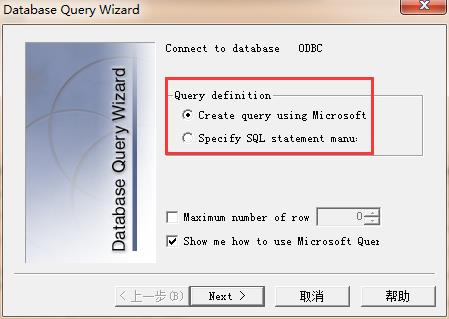
图9(导入数据方式)
1、microsoft query创建查询
2、指定数据库连接字符串和SQL语句
具体创建LR数据源步骤,可看:http://jingyan.baidu.com/article/b2c186c8fee106c46ef6ffb8.html
以上是参数化的整个过程,但参数化过程中有以下几个问题需要注意:
1)参数化文件尽可能少,因为参数化是放在内存中的,占用了内存的资源
2)参数化文件与脚本分离
3)参数文件的路径应该设置为相对路径
4)为了使参数更具有真实性,参数应该从历史数据库中获得
5)参数类型的选择
6)参数的数据由事务决定
关联与参数化的区别
一、数据处理的方式不同
参数化的数据是由客户端向服务器提交的,而关联是需要获取服务器返回客户端的数据。在参数化时,参数化的数据会通过web_submit_data提交到服务器,其参数化的策略来自于相关设置选项,关联的数据是从服务器端返回给客户端的,是提交请求的一组验证信息,所以处理关联数据一定要在从服务器返回的信息中获取。
二、处理的数据是否确定
参数化的数据是测试工程师知道需要使用什么数据进行参数化,以满足事务的需要;而对于需要关联数据的内容是不清楚的,所以只能通过左右边界值来确定。参数化的数据是静态的,即提交的数据可以静态地表示 ,但关联的数据是动态,即它们之间的原理截然不同。
备注:文字讲解来自《深入性能测试--LoadRunner性能测试、流程、监控、调优全程实战剖析》(黄文高、何月顺编著)一书,我是新手,参照此教程做了下实践,顺便将学到的东西写下来。
以上是关于loadrunner提高篇-block(块)技术和参数化的主要内容,如果未能解决你的问题,请参考以下文章