C#TCP协议 socket.receive 超时问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C#TCP协议 socket.receive 超时问题相关的知识,希望对你有一定的参考价值。
在做一个类似局域网QQ的P2P聊天软件,现在要做一个用户异常下线,服务端及时将其从在线配置文件删除的处理。
我的想法是服务器不断向在线用户发包,同时用户端侦听,若客户端还在线,则返回一个标志,表示还活着。若此时客户端异常下线,则服务端的socket.receive 将会超时,此时便在服务端的在线用户中删除其信息。
不知想法对不对?
若我想让客户端也及时得知好友掉线,是否要做相同的处理?
如果想法正确,怎样判断socket.receive 超时?
新手请教前辈了!
解释下:由服务器周期性的给客户端发送消息,客户端
收到后回复(表示客户端还活着)。
当然了,频率和周期可以自己设定,不管是回复超时还是
出错等等,都可以记录失败次数,到达一定的次数就可以
断定客户端掉了。 参考技术A 一般是,你服务端侦听一个端口
用户A每十秒,发送一个消息给服务端,说自己还活着
服务端的话,就计算,如果下一个十秒用户A还没发消息过来~就说明它挂了
大用户量是不可能实时到每秒的,因为这样做对于服务器实在太大负荷了
回答者: jlilo
的回答可用于在正常关闭时实现
ps:我们常用的QQ估计是一分钟为时限的(在异常关闭情况下) 参考技术B P2P就是客户对客户,是不需要服务器参与的。服务器只接收用户登录,管理在线与否的信息。因此,并不是一直保持客户端到服务器的连接。
所以 ,要实现“服务器不断向用户发包”,首先要建立服务器到客户端的连接,因为你说用TCP,而不是UDP。如果用户下线,客户端程序关闭、客户端监听端口关闭时,连接就无法建立,所以谈不到Receive超时的问题。
建议不要用TCP,而用UDP。如果用TCP,不管心跳还是登录,服务器永远做监听方,由客户端主动连接,以便于管理。 参考技术C 你用这种方式,比较不科学,如果用户数众多,你的服务器可能就瘫痪了。
其实还有一个更加简单的,
在用户关掉程序的时候,或是,程序异常终止的时候,给服务器发个消息,告诉,用户端‘某某’挂了,这样就很方便了。 参考技术D 顶起楼主。。。
观望——
TCP/IP传输层协议实现 - TCP的超时与重传(lwip)
(参考《TCP-IP详解卷 1:协议》 第21章 TCP的超时与重传)
1、往返时间测量(RTT)
1.1、分组交换和RTT测量示例
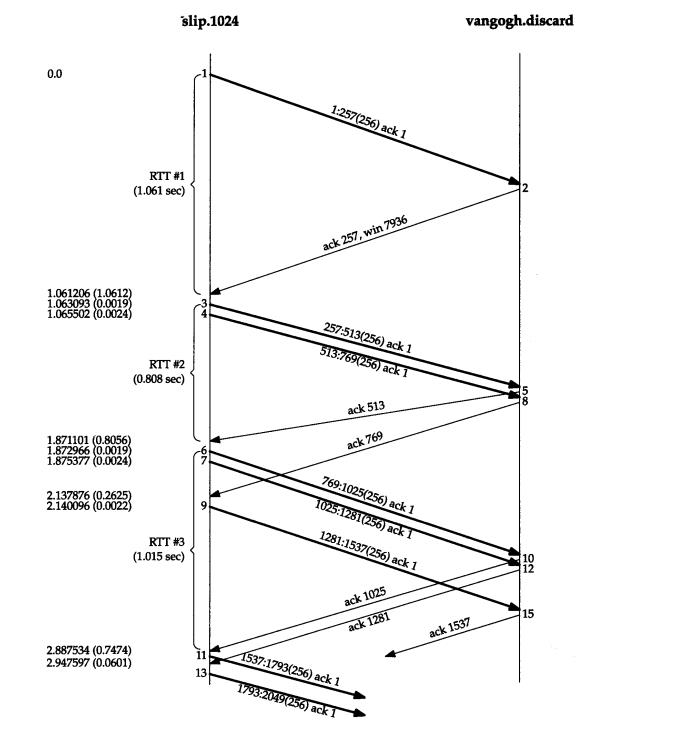
《TCP-IP详解卷 1:协议》中分组交换和RTT测量的示例。
1.2、lwip RTT测量
lwip RTT测量涉及rttest、rtseq、sa、sv变量,rttest为报文发送的时间,,rtseq为测量往返时间报文的序号,sa(rtt average estimator)、sv(rtt deviation estimator)为计算往返时间的变量。
记录测量报文发送的时间及序号。调用tcp_output_segment时,如果没有启动RTT测量,那么开启RTT测量,记录当前报文的发送时间,当前报文的序号。(tcp_output_segment将报文发送到网络层,最后通过网卡发送出去)
if (pcb->rttest == 0) { // rttest为0,表示RTT测量没有启动
pcb->rttest = tcp_ticks; // pcb->rttest设置为当前的tcp_ticks(tcp_ticks可以理解为时间计数,tcp_slowtmr每个周期对tcp_ticks加1)
pcb->rtseq = ntohl(seg->tcphdr->seqno); // pcb->rtseq记录当前发送报文的seqno,RTT对当前发送报文的往返时间进行测量
LWIP_DEBUGF(TCP_RTO_DEBUG, ("tcp_output_segment: rtseq %"U32_F"\\n", pcb->rtseq));
}
计算报文发送到报文被确认接收的时间及超时重传时间rto。(发送方收到接收方的ACK报文,计算发送到接收到ACK的往返时间;使用Van Jacobson的Congestion Avoidance and Control算法计算超时重传时间,算法代码在Van Jacobson《Congestion Avoidance and Control》论文第20页)
/* RTT estimation calculations. This is done by checking if the
incoming segment acknowledges the segment we use to take a
round-trip time measurement. */
if (pcb->rttest && TCP_SEQ_LT(pcb->rtseq, ackno)) { // pcb->rtseq < ackno,pcb->rtseq被确认接收
/* diff between this shouldn't exceed 32K since this are tcp timer ticks
and a round-trip shouldn't be that long... */
m = (s16_t)(tcp_ticks - pcb->rttest); // 计算RTT往返时间,pcb->rttest为报文发送时的时间,tcp_ticks为收到ACK应答时的当前时间,tcp_ticks - pcb->rttest即为报文往返时间
LWIP_DEBUGF(TCP_RTO_DEBUG, ("tcp_receive: experienced rtt %"U16_F" ticks (%"U16_F" msec).\\n",
m, m * TCP_SLOW_INTERVAL));
/* This is taken directly from VJs original code in his paper */
m = m - (pcb->sa >> 3);
pcb->sa += m;
if (m < 0) {
m = -m;
}
m = m - (pcb->sv >> 2);
pcb->sv += m;
pcb->rto = (pcb->sa >> 3) + pcb->sv;
LWIP_DEBUGF(TCP_RTO_DEBUG, ("tcp_receive: RTO %"U16_F" (%"U16_F" milliseconds)\\n",
pcb->rto, pcb->rto * TCP_SLOW_INTERVAL));
pcb->rttest = 0;
}
2、超时重传定时器
2.1、启动超时重传定时器
启动发送超时定时器。(rtime为-1,表示没有启动发送超时定时器,没有报文发送,没有需要超时重传的报文;rtime为0,表示已启动发送超时定时器,tcp_output_segment发送报文时,如果发送超时定时器rtime为-1(没有启动发送超时定时器),那么启动发送超时定时器,rtime设置为0,超时重传时间开始计时)
/* Increase the retransmission timer if it is running */
if(pcb->rtime >= 0)
++pcb->rtime;
2.2、关闭超时重传定时器
关闭超时定时器。(客户发起连接,收到服务器的SYN|ACK报文,如果客户发起连接过程中没有数据要发送(unacked队列为空),没有等待超时重传的数据,那么关闭超时重传定时器,rtime设置为-1,否则,复位超时重传定时器及超时重传次数,rtime、nrtx设置为0,重新开始启动超时重传定时;其他状态收到ACK,有新的数据被确认接收时,复位超时重传计数器nrtx为0,如果unacked队列仍有数据,复位超时重传时间rtime为0(tcp_input收到报文后,会调用tcp_output发送报文,因此下一次超时重传时间需要从当前时间重新开始计时),否则关闭超时重传定时器,rtime设置为-1;总而言之就是,有新的数据被确认接收时,如果unacked仍有待超时重传的报文,那么复位超时重传定时器及超时重传次数,如果unacked没有待超时重传的报文,那么复位超时重传次数及关闭超时重传定时器)
/* If there's nothing left to acknowledge, stop the retransmit
timer, otherwise reset it to start again */
if(pcb->unacked == NULL)
pcb->rtime = -1;
else {
pcb->rtime = 0;
pcb->nrtx = 0;
}
2.3、超时重传定时器超时(拥塞)
unacked队列长时间没有数据被确认接收时,tcp的慢定时器,每过一段时间调用tcp_slowtmr对超时重传时间rtime计时,每个周期加1。
/* Increase the retransmission timer if it is running */
if(pcb->rtime >= 0) // 对tcp_active_pcbs里面的超时重传时间计时(pcb->rtime >= 0表示已启动超时重传定时器)
++pcb->rtime; // 超时重传定时器加1
unacked队列不为空,有待确认接收的报文,超时重传时间rtime大于等于超时时间rto。(发送报文超时)
if (pcb->unacked != NULL && pcb->rtime >= pcb->rto) {
/* Time for a retransmission. */
LWIP_DEBUGF(TCP_RTO_DEBUG, ("tcp_slowtmr: rtime %"S16_F
" pcb->rto %"S16_F"\\n",
pcb->rtime, pcb->rto));
更新下一次超时时间rto,复位超时重传计数器rtime为0。
/* Double retransmission time-out unless we are trying to
* connect to somebody (i.e., we are in SYN_SENT). */
if (pcb->state != SYN_SENT) { // 非SYN_SENT状态(已连接的状态)
pcb->rto = ((pcb->sa >> 3) + pcb->sv) << tcp_backoff[pcb->nrtx]; // 根据算法,重新计算下一次超时重传时间(越往后,超时重传时间间隔越大)
}
/* Reset the retransmission timer. */
pcb->rtime = 0;
慢启动门限ssthresh、拥塞窗口cwnd更新。(慢启动门限ssthresh设置为拥塞窗口/发送窗口的一半(最少为 2个报文段),拥塞窗口设置为一个报文段,执行慢启动算法,慢启动一直持续到我们回到当拥塞发生时所处位置的一半(ssthresh)的时候才停止,当拥塞窗口大于慢启动门限时,才执行拥塞避免算法)
/* Reduce congestion window and ssthresh. */
eff_wnd = LWIP_MIN(pcb->cwnd, pcb->snd_wnd);
pcb->ssthresh = eff_wnd >> 1;
if (pcb->ssthresh < pcb->mss) {
pcb->ssthresh = pcb->mss * 2;
}
pcb->cwnd = pcb->mss; // 慢启动算法(pcb->cwnd < pcb->ssthresh),当拥塞窗口大于慢启动门限时,才执行拥塞避免算法
LWIP_DEBUGF(TCP_CWND_DEBUG, ("tcp_slowtmr: cwnd %"U16_F
" ssthresh %"U16_F"\\n",
pcb->cwnd, pcb->ssthresh));
调用tcp_rexmit_rto,超时重传次数加1,unacked队列插入到unsent队列头部,最后调用tcp_output发送unsent队列(此时拥塞窗口已经减小了,tcp_output能够发送的数据也减少了,避免网络拥塞)
3、慢启动算法
《TCP-IP详解卷 1:协议》“20.6 慢启动”。
慢启动为发送方的TCP增加了另一个窗口:拥塞窗口 (congestion window),记为cwnd,当与另一个网络的主机建立 TCP连接时,拥塞窗口被初始化为 1个报文段,每收到一个ACK,拥塞窗口就增加一个报文段,发送方取拥塞窗口与通告窗口中的最小值作为发送上限。
3.1、建立连接/数据收发过程的慢启动
先不考虑慢启动门限。
客户发起连接时,发送第一次握手报文,拥塞窗口设置为1个字节。(与《TCP-IP详解卷 1:协议》稍有不同,lwip初始化拥塞窗口为1个字节,而不是1个报文段;连接过程不需要发送数据,最大报文段大小也还没协商,拥塞窗口设置为1个字节对本地也没有影响)
pcb->cwnd = 1; // 拥塞窗口设置为一个字节
pcb->ssthresh = pcb->mss * 10;
pcb->state = SYN_SENT;
客户收到第二次握手的SYN|ACK报文时,拥塞窗口设置为2个报文段。(虽然lwip初始化拥塞窗口为1个字节,但是收到第二次握手报文时,拥塞窗口设置为2个报文段,相当于初始化时为1个报文段,收到SYN|ACK报文时增加1个报文段,最终还是《TCP-IP详解卷 1:协议》慢启动的拥塞窗口大小一样,2个报文段)
/* Set ssthresh again after changing pcb->mss (already set in tcp_connect
* but for the default value of pcb->mss) */
pcb->ssthresh = pcb->mss * 10;
pcb->cwnd = ((pcb->cwnd == 1) ? (pcb->mss * 2) : pcb->mss); // 拥塞窗口增加一个报文段
ESTABLISHED状态下,客户收到ACK报文。
if (pcb->state >= ESTABLISHED) {
if (pcb->cwnd < pcb->ssthresh) {
if ((u16_t)(pcb->cwnd + pcb->mss) > pcb->cwnd) {
pcb->cwnd += pcb->mss; // 拥塞窗口增加一个报文段
}
LWIP_DEBUGF(TCP_CWND_DEBUG, ("tcp_receive: slow start cwnd %"U16_F"\\n", pcb->cwnd));
} else {
u16_t new_cwnd = (pcb->cwnd + pcb->mss * pcb->mss / pcb->cwnd);
if (new_cwnd > pcb->cwnd) {
pcb->cwnd = new_cwnd;
}
LWIP_DEBUGF(TCP_CWND_DEBUG, ("tcp_receive: congestion avoidance cwnd %"U16_F"\\n", pcb->cwnd));
}
}
3.2、发生超时的慢启动(拥塞)
分组丢失意味着在源主机和目的主机之间的某处网络上发生了拥塞。有两种分组丢失的指示:发生超时和接收到重复的确认。(发生超时的慢启动参考“2.3、发送超时(拥塞)”;lwip接收到小于3个重复的确认时,没有执行慢启动!!!)
4、拥塞避免算法
《TCP-IP详解卷 1:协议》"21.6 拥塞避免算法"。
分组丢失意味着在源主机和目的主机之间的某处网络上发生了拥塞。有两种分组丢失的指示:发生超时和接收到重复的确认。(lwip接收到小于3个重复的确认时,没有执行拥塞避免!!!)
拥塞避免算法和慢启动算法是两个目的不同、独立的算法。但是当拥塞发生时,我们希望降低分组进入网络的传输速率,于是可以调用慢启动来做到这一点。在实际中这两个算法通常在一起实现。
拥塞避免算法和慢启动算法需要对每个连接维持两个变量:一个拥塞窗口cwnd和一个慢启动门限ssthresh。
4.1、拥塞窗口控制发送数据
TCP输出例程的输出不能超过cwnd和接收方通告窗口(发送窗口)的大小。
tcp_output发送unsent报文时,取拥塞窗口和接收方通告窗口(发送窗口)较小的作为当前的发送窗口来发送数据,当前发送窗口之外的数据不能够被发送。
wnd = LWIP_MIN(pcb->snd_wnd, pcb->cwnd);
seg = pcb->unsent;
4.2、拥塞发生时
发生超时,即发生了拥塞。(发生超时的拥塞避免,发生超时,首先执行的是慢启动算法,当拥塞窗口大于慢启动门限时,才执行拥塞避免算法,慢启动过程参考“2.3、发送超时(拥塞)”)
发生超时,ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为 2个报文段)。
执行拥塞避免算法。
拥塞避免算法要求每次收到一个确认时将cwnd增加1/cwnd(lwip是1/ cwnd个mss * mss;《TCP-IP详解卷 1:协议》 "21.8 拥塞举例(续)"中,也不是1/cwnd)。与慢启动的指数增加比起来(lwip慢启动是线性增长,每次增加一个报文段),这是一种加性增长(additive increase);拥塞避免算法,拥塞窗口每次增加1/pcb->cwnd个pcb->mss * pcb->mss,pcb->mss * pcb->mss一般不会变化,每次有数据被确认接收时,拥塞窗口cwnd都会增加pcb->mss * pcb->mss / pcb->cwnd,拥塞窗口cwnd在增加,那么pcb->mss * pcb->mss / pcb->cwnd每次都在减小,因此拥塞窗口每次增加的大小在减小,拥塞窗口增加的速度在下降)
/* Update the congestion control variables (cwnd and
ssthresh). */
if (pcb->state >= ESTABLISHED) {
if (pcb->cwnd < pcb->ssthresh) { // 慢启动
if ((u16_t)(pcb->cwnd + pcb->mss) > pcb->cwnd) {
pcb->cwnd += pcb->mss; // 慢启动(线性增长)
}
LWIP_DEBUGF(TCP_CWND_DEBUG, ("tcp_receive: slow start cwnd %"U16_F"\\n", pcb->cwnd));
} else { // 拥塞避免
u16_t new_cwnd = (pcb->cwnd + pcb->mss * pcb->mss / pcb->cwnd); // 拥塞避免(加性增长)
if (new_cwnd > pcb->cwnd) {
pcb->cwnd = new_cwnd;
}
LWIP_DEBUGF(TCP_CWND_DEBUG, ("tcp_receive: congestion avoidance cwnd %"U16_F"\\n", pcb->cwnd));
}
}
5、快速重传与快速恢复算法
具体描述参考《TCP-IP详解卷 1:协议》 21.7 快速重传与快速恢复算法。
收到一个失序的报文段时,TCP立即需要产生一个ACK(一个重复的ACK)。由于我们不知道一个重复的ACK是由一个丢失的报文段引起的,还是由于仅仅出现了几个报文段的重新排序,因此我们等待少量重复的ACK到来。如果一连串收到 3个或3个以上的重复ACK,就非常可能是一个报文段丢失了,于是我们就重传丢失的数据报文段,而无需等待超时定时器溢出。这就是快速重传算法。
接下来执行的不是慢启动算法而是拥塞避免算法。这就是快速恢复算法。(快速恢复算法时的拥塞窗口是一个比较大的窗口,相当于在慢启动过程直接跳到拥塞避免算法,快速恢复了拥塞窗口)
5.1、重复ACK的判断
收到ACK报文时,如果该报文有确认新的数据被接收,那么lastack更新为该报文的ackno,因此lastack记录的是最后一次确认数据被接收的报文的ackno。(如果没有新的数据被确认接收,那么lastack一直不会变化)
更新发送窗口的原则:
1、当前报文的序号seqno大于之前收到报文的最大序号seqno,那么使用当前报文的通告窗口、序号seqno、确认序号ackno更新发送窗口相关数据(当前报文序号大于之前收到报文的最大序号,当前收到的报文比之前收到的报文的发送时间更后,那么当前报文的ackno应该也大于或等于之前收到报文的最大确认序号ackno);
2、当前报文的序号seqno等于之前收到报文的最大序号seqno并且ackno大于之前的确认报文的ackno,那么使用当前报文的通告窗口、序号seqno、确认序号ackno更新发送窗口相关数据(之前最大序号的报文为顺序上最后发送的报文,当前报文序号seqno与之相等,ackno大于之前报文的ackno,那么当前报文应该是对端收到了新的数据但是对端没有数据要发送,只发送一个ACK确认报文,因此报文的seqno与之前报文相等,但是ackno增加了,ackno越大可以认为是发送时间越后);
3、当前报文的seqno等于之前收到的最大报文的seqno,但是ackno小于之前收到的最大报文的ackno,那么不更新发送窗口相关数据,也认为是重复ACK(当前报文确认了已经确认数据中的一小部分,例如之前报文确认了1、2、3、4、5这几个数据被接收,当前报文确认1、2、3这几个数据被接收,那么很明显1、2、3这3个数据被重复确认接收了);
4、当前报文的seqno、ackno都与之前收到的最大报文的seqno、ackno相同,如果通告窗口小于或等于之前最大seqno、ackno的报文的通告窗口,可以认为是重复报文(通告窗口相等,两个报文一样,可以认为是重复的确认;通告窗口更小,理论上应该是先发送的一个报文后到达,那么该报文相对于前一个报文也是重复的,对端收到数据时,通告窗口(接收窗口)正常情况下会变小,数据被应用层接收时才会变大接收窗口,因此小的通告窗口理论上应该是数据被应用层接收前发送的ACK报文,大的通告窗口理论上应该是数据被应用层接收后发送的ACK报文,后收到的小通告窗口的ACK报文重复了大通告窗口的ACK报文),不需要更新发送窗口相关数据,"pcb->snd_wnd + pcb->snd_wl2"将不会发生变化,就认为是重复报文,如果当前报文的通告窗口大于之前收到报文的通告窗口,如之前所言,应该是应用层接收数据后,接收窗口变大了,因此可以认为之前的报文是应用层接收数据前的,当前的报文是应用层接收数据后的,两个报文是先后两个不同的报文,那么使用当前报文的通告窗口、序号seqno、确认序号ackno更新发送窗口相关数据,"pcb->snd_wnd + pcb->snd_wl2"将发生变化,通过这个变化就认为不是重复ACK。
总结起来就是,seqno、ackno、wnd相同的ACK报文认为是重复的ACK,ackno小的ACK报文认为是重复的ACK报文,seqno、ackno相同通告窗口wnd更大的ACK报文认为是先的报文。
重复ACK的判断涉及发送窗口更新代码,发送窗口更新代码如下:
/* Update window. */
if (TCP_SEQ_LT(pcb->snd_wl1, seqno) ||
(pcb->snd_wl1 == seqno && TCP_SEQ_LT(pcb->snd_wl2, ackno)) ||
(pcb->snd_wl2 == ackno && tcphdr->wnd > pcb->snd_wnd)) {
pcb->snd_wnd = tcphdr->wnd;
pcb->snd_wl1 = seqno;
pcb->snd_wl2 = ackno;
if (pcb->snd_wnd > 0 && pcb->persist_backoff > 0) {
pcb->persist_backoff = 0;
}
LWIP_DEBUGF(TCP_WND_DEBUG, ("tcp_receive: window update %"U16_F"\\n", pcb->snd_wnd));
#if TCP_WND_DEBUG
} else {
if (pcb->snd_wnd != tcphdr->wnd) {
LWIP_DEBUGF(TCP_WND_DEBUG,
("tcp_receive: no window update lastack %"U32_F" ackno %"
U32_F" wl1 %"U32_F" seqno %"U32_F" wl2 %"U32_F"\\n",
pcb->lastack, ackno, pcb->snd_wl1, seqno, pcb->snd_wl2));
}
#endif /* TCP_WND_DEBUG */
}
判断当前报文的ackno是否等于之前收到的最大的lastack。(ackno < lastack,那么可以认为当前报文是乱序收到的,不需要判断重复ACK;如果ackno > lastack,那么很明显ackno与之前报文的ackno不会重复,当前报文的ackno比之前报文的ackno都大)
if (pcb->lastack == ackno) {
pcb->acked = 0;
if (pcb->snd_wl2 + pcb->snd_wnd == right_wnd_edge){ // 相等为重复的ACK(参考前面判断重复ACK的原则)
++pcb->dupacks; // 增加重复ack计数
if (pcb->dupacks >= 3 && pcb->unacked != NULL) { // 重复ack大于等于3次,并且有待被确认接收的数据
5.2、快速重传与快速恢复算法
执行快速重传与快速恢复算法。(当收到第3个重复的ACK时,将ssthresh设置为当前拥塞窗口cwnd的一半。重传丢失的报文段。设置cwnd为ssthresh加上3倍的报文段大小。)
/* This is fast retransmit. Retransmit the first unacked segment. */
LWIP_DEBUGF(TCP_FR_DEBUG, ("tcp_receive: dupacks %"U16_F" (%"U32_F"), fast retransmit %"U32_F"\\n",
(u16_t)pcb->dupacks, pcb->lastack,
ntohl(pcb->unacked->tcphdr->seqno)));
tcp_rexmit(pcb);
/* Set ssthresh to max (FlightSize / 2, 2*SMSS) */
/*pcb->ssthresh = LWIP_MAX((pcb->snd_max -
pcb->lastack) / 2,
2 * pcb->mss);*/
/* Set ssthresh to half of the minimum of the current cwnd and the advertised window */
if (pcb->cwnd > pcb->snd_wnd)
pcb->ssthresh = pcb->snd_wnd / 2; // ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为 2个报文段)
else
pcb->ssthresh = pcb->cwnd / 2; // ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为 2个报文段)
/* The minimum value for ssthresh should be 2 MSS */
if (pcb->ssthresh < 2*pcb->mss) {
LWIP_DEBUGF(TCP_FR_DEBUG, ("tcp_receive: The minimum value for ssthresh %"U16_F" should be min 2 mss %"U16_F"...\\n", pcb->ssthresh, 2*pcb->mss));
pcb->ssthresh = 2*pcb->mss; // ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为 2个报文段)
}
pcb->cwnd = pcb->ssthresh + 3 * pcb->mss; // pcb->cwnd > pcb->ssthresh,当前正在进行拥塞避免
pcb->flags |= TF_INFR; // 设置快速恢复标志
}快速恢复过程收到重复ACK。(每次收到另一个重复的ACK时, cwnd增加1个报文段大小并发送 1个分组(如果新的cwnd允许发送))
} else {
/* Inflate the congestion window, but not if it means that
the value overflows. */
if ((u16_t)(pcb->cwnd + pcb->mss) > pcb->cwnd) {
pcb->cwnd += pcb->mss;
}
}
当下一个确认新数据的ACK到达时,设置cwnd为ssthresh。(ssthresh为快速恢复时窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为 2个报文段);清除快速恢复标志,执行拥塞避免算法)
/* Reset the "IN Fast Retransmit" flag, since we are no longer
in fast retransmit. Also reset the congestion window to the
slow start threshold. */
if (pcb->flags & TF_INFR) {
pcb->flags &= ~TF_INFR; // 清除快速恢复标志
pcb->cwnd = pcb->ssthresh;
}
以上是关于C#TCP协议 socket.receive 超时问题的主要内容,如果未能解决你的问题,请参考以下文章