SparkR-Install
Posted Mr.Zhao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkR-Install相关的知识,希望对你有一定的参考价值。
1.下载R
1.1 下载URL:https://cran.r-project.org/src/base/R-3/

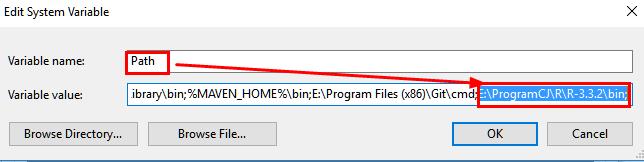
1.2 环境变量配置
1.3 测试安装:

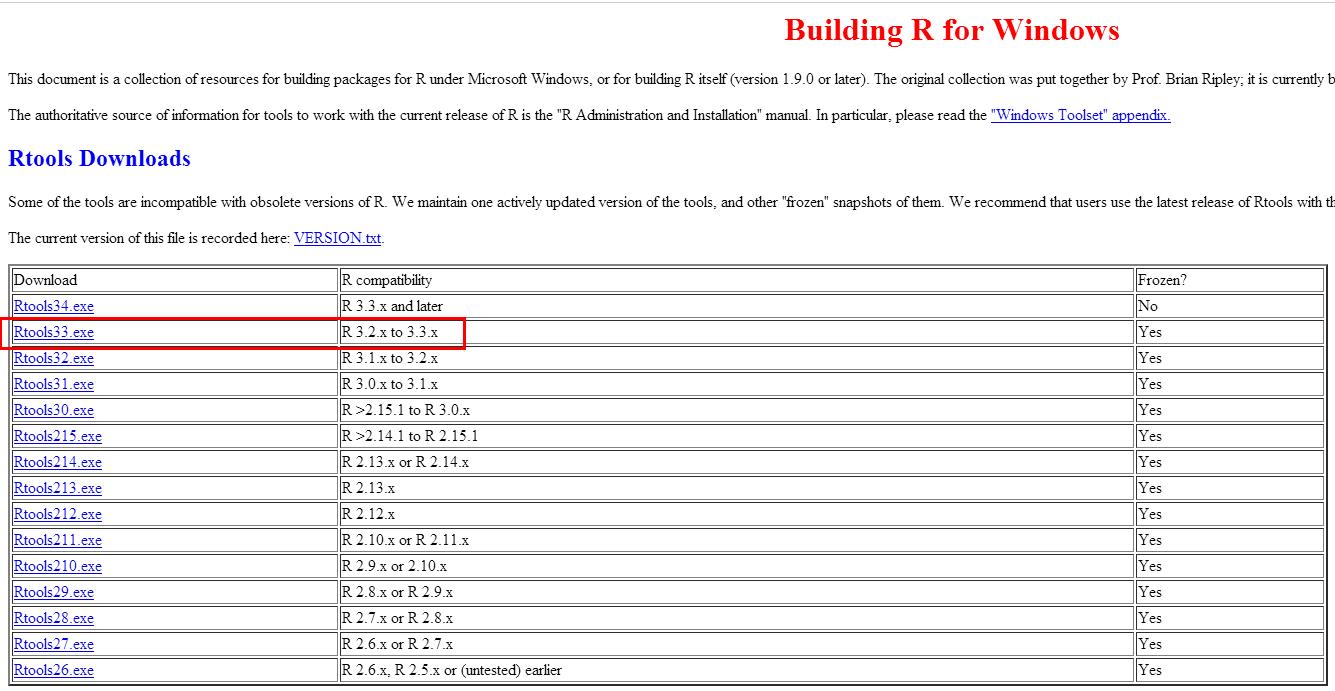
2.下载Rtools33
URL:https://cran.r-project.org/bin/windows/Rtools/
2.1 配置环境变量

2.2 测试安装成功
3.安装RStudio
URL: https://www.rstudio.com/products/rstudio/download/
直接下一步即可安装

4.安装JDK并设置环境变量
4.1环境变量配置:



4.2测试:

5.下载Spark安装程序
5.1 URL: http://spark.apache.org/downloads.html

5.2解压到本地磁盘的对应目录

6.安装Spark并设置环境变量


7.测试SparkR
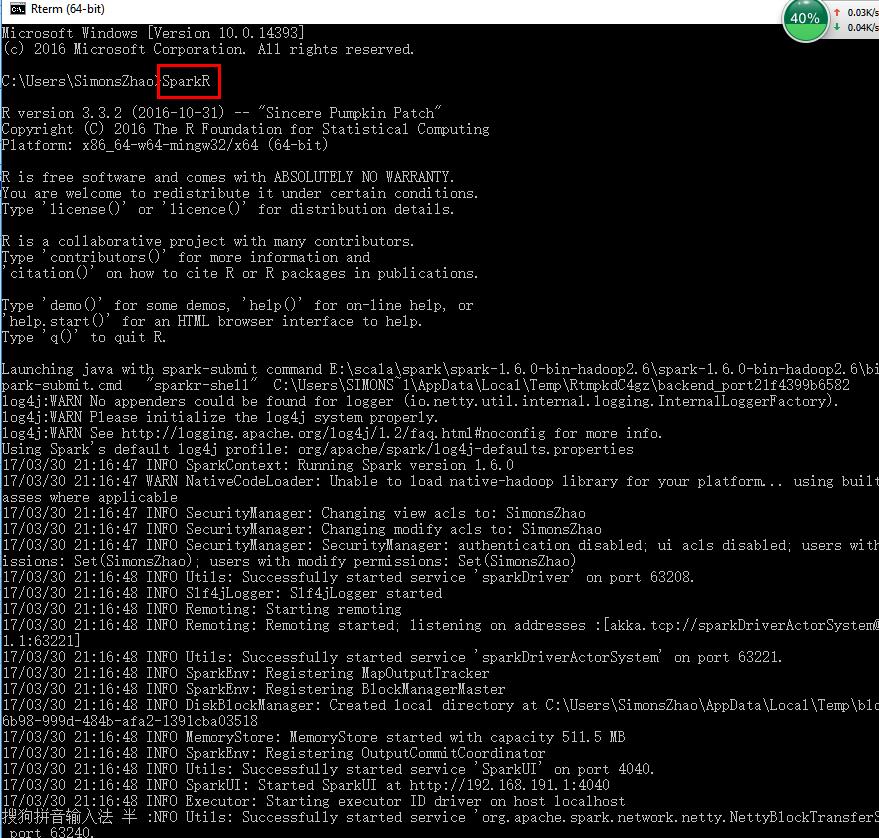

注意:如果发现了提示 WARN NativeCodeLader:Unable to load native-hadoop library for your platform.....using
builtin-java classes where applicable 需要安装本地的hadoop库
8.下载hadoop库并安装
URL: http://hadoop.apache.org/releases.html
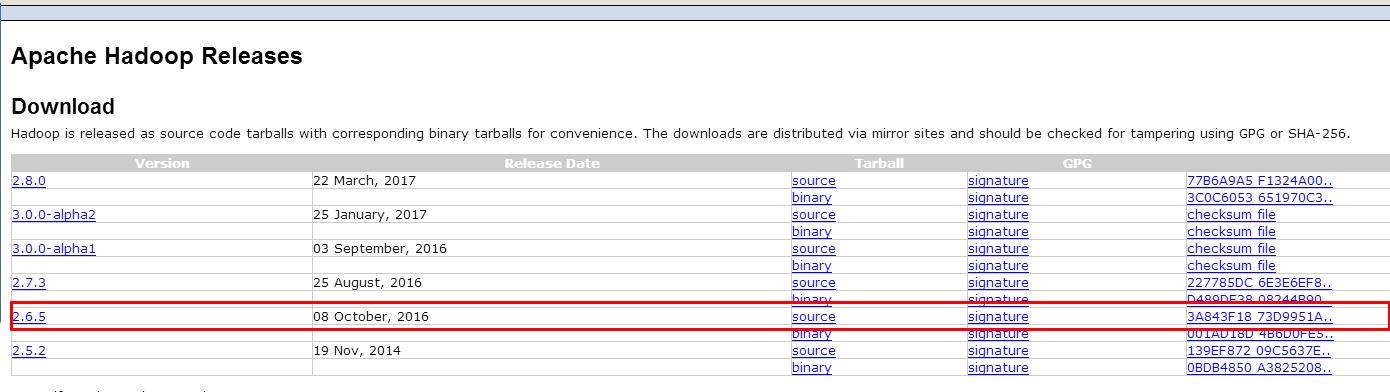
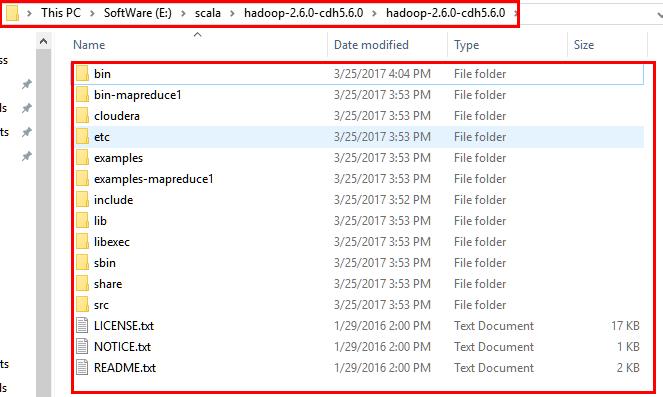
9.设置hadoop环境变量

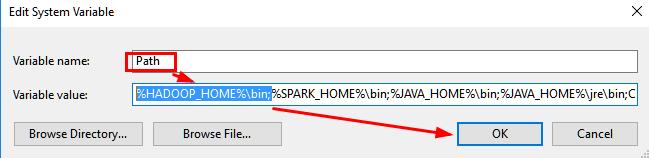
10.重新测试SparkR
10.1 如果测试时候出现以下提示,需要修改log4j文件INFO为WARN,位于\\spark\\conf下
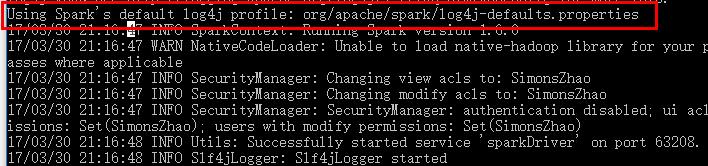
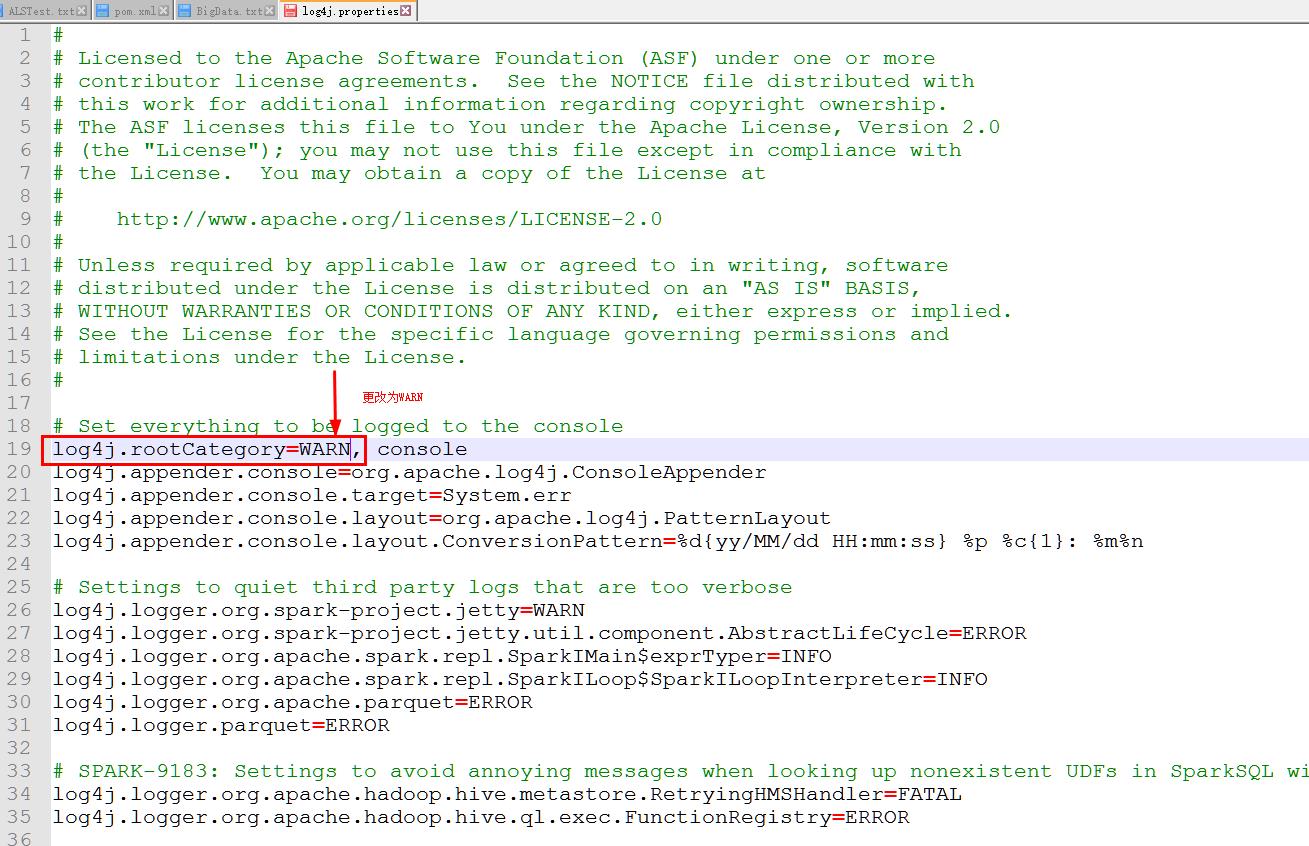
10.2 修改conf中的log4j文件:

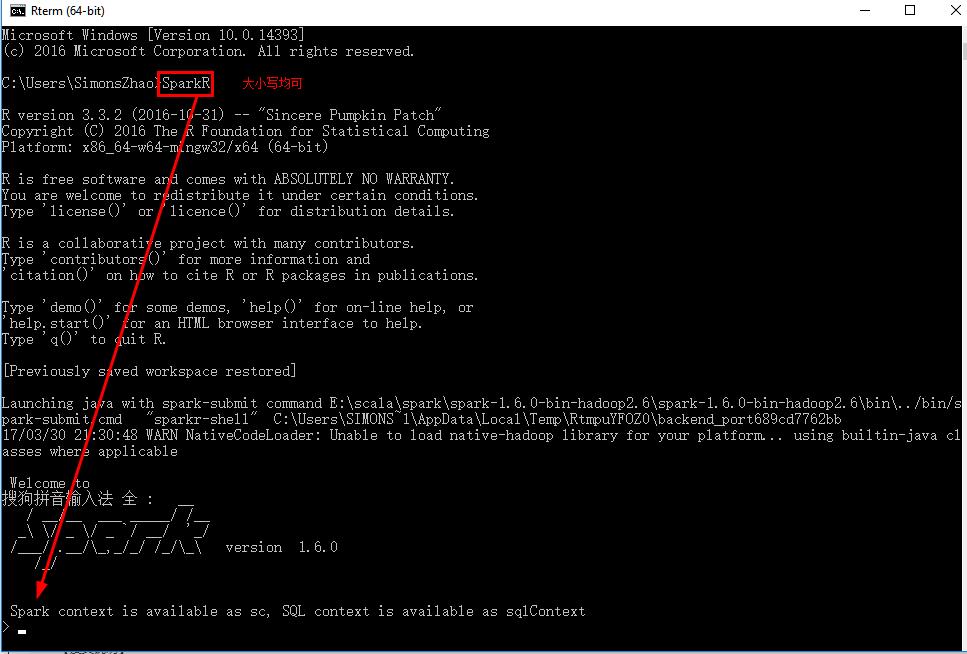
10.3 重新运行SparkR,输出就会变少
11.运行SprkR代码
在Spark2.0中增加了RSparkSql进行Sql查询
dataframe为数据框操作
data-manipulation为数据转化
ml为机器学习
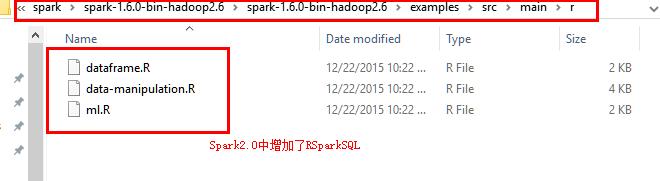
11.1 使用crtl+ALT+鼠標左鍵 打开控制台在此文件夹下
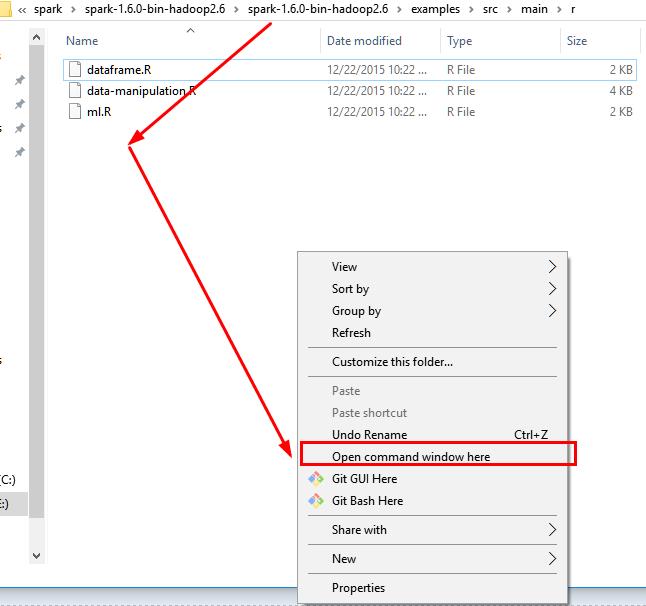
11.2 执行spark-submit xxx.R文件即可
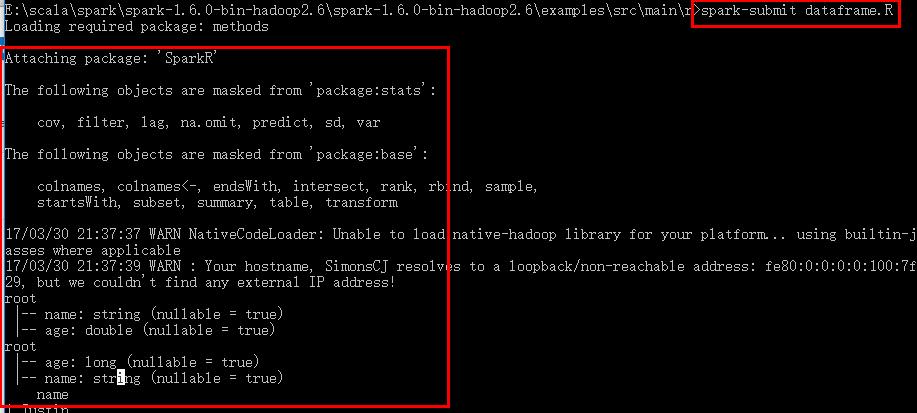
12.安装SparkR包
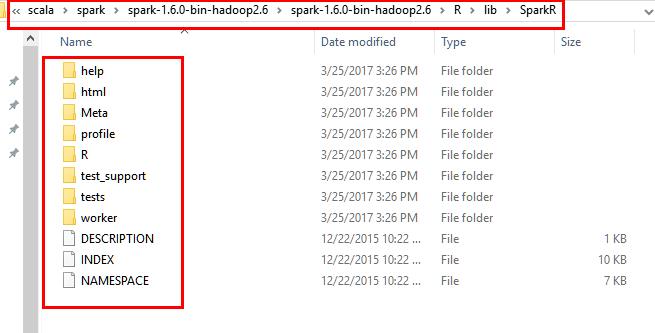
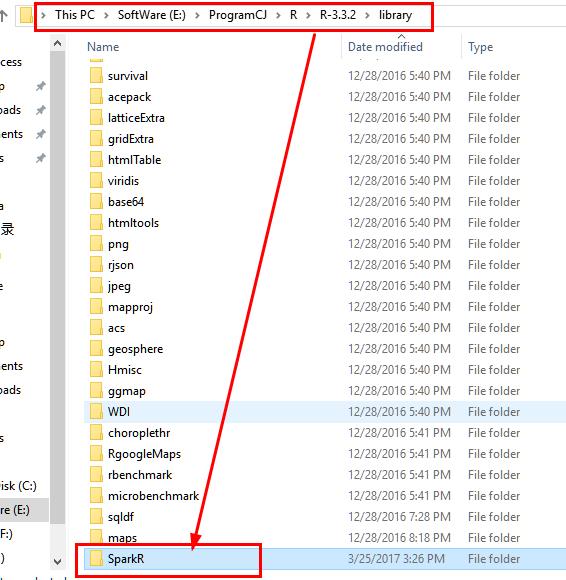
12.1 将spark安装目录下的R/lib中的SparkR文件拷贝到..\\R-3.3.2\\library中,注意是将整个Spark文件夹,而非里面每一个文件。
源文件夹:
目的文件夹:
12.2 在RStudio中打开SparkR文件并运行代码dataframe.R文件,采用Ctrl+Enter一行行执行即可
SparkR语言的dataframe.R源代码如下
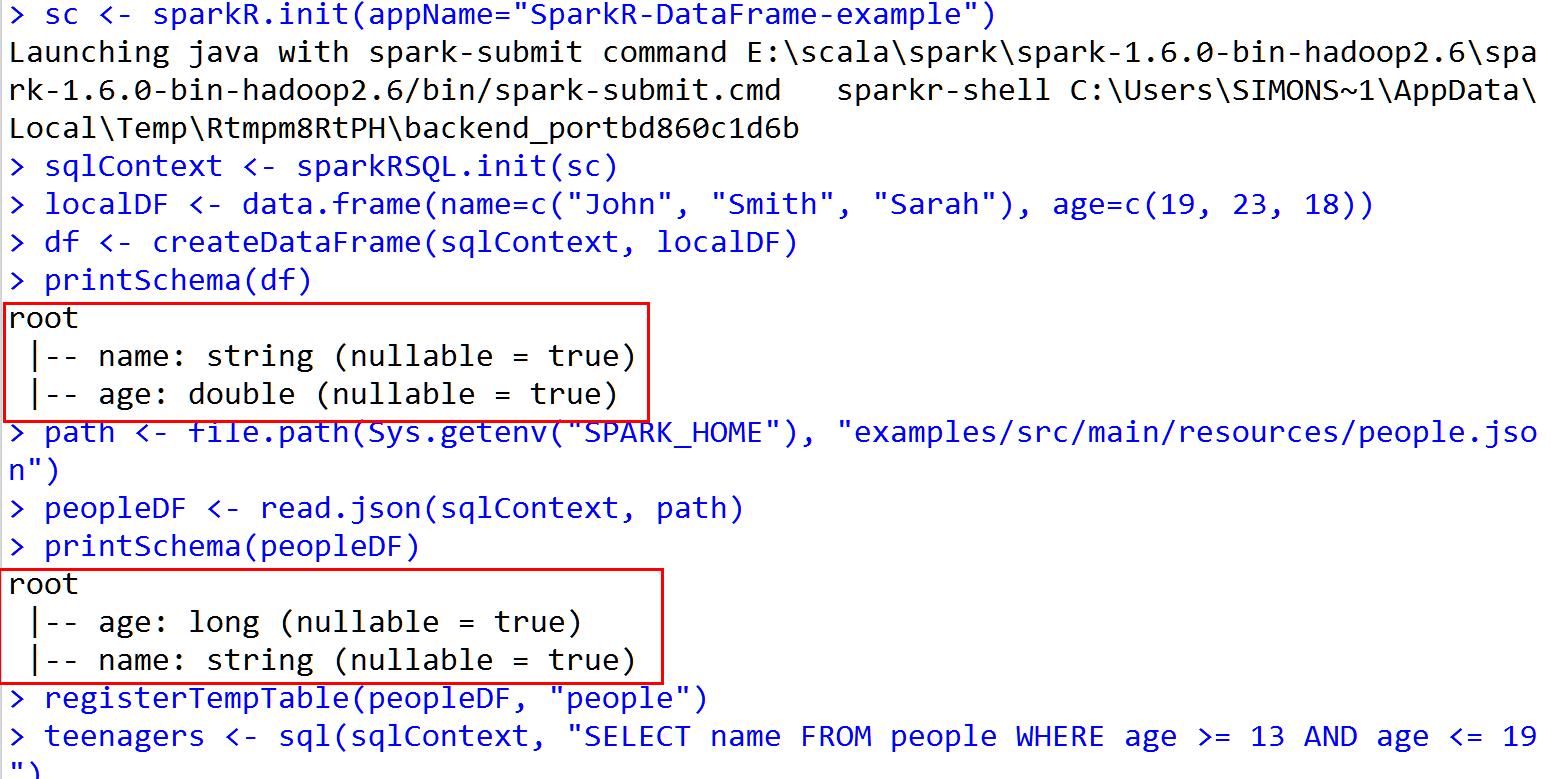
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # library(SparkR) # Initialize SparkContext and SQLContext sc <- sparkR.init(appName="SparkR-DataFrame-example") sqlContext <- sparkRSQL.init(sc) # Create a simple local data.frame localDF <- data.frame(name=c("John", "Smith", "Sarah"), age=c(19, 23, 18)) # Convert local data frame to a SparkR DataFrame df <- createDataFrame(sqlContext, localDF) # Print its schema printSchema(df) # root # |-- name: string (nullable = true) # |-- age: double (nullable = true) # Create a DataFrame from a JSON file path <- file.path(Sys.getenv("SPARK_HOME"), "examples/src/main/resources/people.json") peopleDF <- read.json(sqlContext, path) printSchema(peopleDF) # Register this DataFrame as a table. registerTempTable(peopleDF, "people") # SQL statements can be run by using the sql methods provided by sqlContext teenagers <- sql(sqlContext, "SELECT name FROM people WHERE age >= 13 AND age <= 19") # Call collect to get a local data.frame teenagersLocalDF <- collect(teenagers) # Print the teenagers in our dataset print(teenagersLocalDF) # Stop the SparkContext now sparkR.stop()
13.Rsudio 运行结果
补充:SparkR自带机器学习的例子:(D:\\......\\spark-1.6.0-bin-hadoop2.6\\spark-1.6.0-bin-hadoop2.6\\examples\\src\\main\\r)
源代码如下:
1 # 2 # Licensed to the Apache Software Foundation (ASF) under one or more 3 # contributor license agreements. See the NOTICE file distributed with 4 # this work for additional information regarding copyright ownership. 5 # The ASF licenses this file to You under the Apache License, Version 2.0 6 # (the "License"); you may not use this file except in compliance with 7 # the License. You may obtain a copy of the License at 8 # 9 # http://www.apache.org/licenses/LICENSE-2.0 10 # 11 # Unless required by applicable law or agreed to in writing, software 12 # distributed under the License is distributed on an "AS IS" BASIS, 13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 14 # See the License for the specific language governing permissions and 15 # limitations under the License. 16 # 17 18 # To run this example use 19 # ./bin/sparkR examples/src/main/r/ml.R 20 21 # Load SparkR library into your R session 22 library(SparkR) 23 24 # Initialize SparkContext and SQLContext 25 sc <- sparkR.init(appName="SparkR-ML-example") 26 sqlContext <- sparkRSQL.init(sc) 27 28 # Train GLM of family \'gaussian\' 29 training1 <- suppressWarnings(createDataFrame(sqlContext, iris)) 30 test1 <- training1 31 model1 <- glm(Sepal_Length ~ Sepal_Width + Species, training1, family = "gaussian") 32 33 # Model summary 34 summary(model1) 35 36 # Prediction 37 predictions1 <- predict(model1, test1) 38 head(select(predictions1, "Sepal_Length", "prediction")) 39 40 # Train GLM of family \'binomial\' 41 training2 <- filter(training1, training1$Species != "setosa") 42 test2 <- training2 43 model2 <- glm(Species ~ Sepal_Length + Sepal_Width, data = training2, family = "binomial") 44 45 # Model summary 46 summary(model2) 47 48 # Prediction (Currently the output of prediction for binomial GLM is the indexed label, 49 # we need to transform back to the original string label later) 50 predictions2 <- predict(model2, test2) 51 head(select(predictions2, "Species", "prediction")) 52 53 # Stop the SparkContext now 54 sparkR.stop()
运行结果:


END~
以上是关于SparkR-Install的主要内容,如果未能解决你的问题,请参考以下文章