python下用selenium的webdriver包如何取得打开页面的html源代码呢
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python下用selenium的webdriver包如何取得打开页面的html源代码呢相关的知识,希望对你有一定的参考价值。
我用 data=driver.find_element_by_xpath("html").text 得到的是页面看到的文字,我想得到完整的html源代码要怎么做呢?
谢谢
这个可以通过浏览器自带的f12 。
或者通过鼠标右键,审计元素获得当前html源代码。
步骤如下:
使用框架载入形式,代码如下:
代码解析:
src="123.htm" 载入的页面 。
scrolling=no 有3个选择 分别为yes no auto 这个就是设置下拉条的,yes为有下拉条,no
为没有,auto为自动识别。
width=500 载入页面的宽度 。
height=500 载入页面的高度 。
bordercolor="#000000" 载入页面的背景颜色 。
提示:只要复制我那句代码,然后再把宽度和高度设置成你想要的。
Linux下用selenium打开网页报错
环境:Fedora11、Firefox、Python2.7.3、Selenium2.44.0
这是我的Python脚本:
from selenium import webdriver
browser=webdriver.Firefox()
browser.get(http://www.baidu.com)
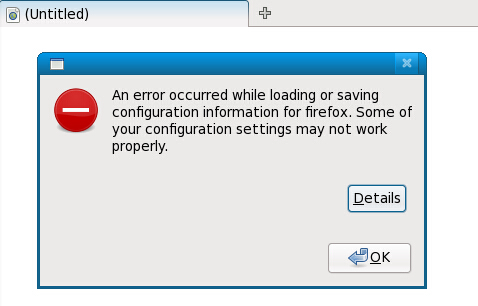
执行脚本后会弹出浏览器,如下图所示:
点击“Detailes”会出现这样的错误提示:“
Failed to contact configuration server; some possible causes are that you need to enable TCP/IP networking for ORBit, or you have stale NFS locks due to a system crash. See http://projects.gnome.org/gconf/ for information. (Details - 1: Failed to get connection to session: Did not receive a reply. Possible causes include: the remote application did not send a reply, the message bus security policy blocked the reply, the reply timeout expired, or the network connection was broken.)
”
然后Python编译器下会这样报错:
Traceback (most recent call last):
File "test.py", line 3, in <module>
browser=webdriver.Firefox()
File "/usr/local/lib/python2.7/site-packages/selenium-2.9.0-py2.7.egg/selenium/webdriver/firefox/webdriver.py", line 47, in __init__
desired_capabilities=DesiredCapabilities.FIREFOX)
File "/usr/local/lib/python2.7/site-packages/selenium-2.9.0-py2.7.egg/selenium/webdriver/remote/webdriver.py", line 60, in __init__
self.start_session(desired_capabilities, browser_profile)
File "/usr/local/lib/python2.7/site-packages/selenium-2.9.0-py2.7.egg/selenium/webdriver/remote/webdriver.py", line 151, in execute
response = self.command_executor.execute(driver_command, params)
......后面还有很多错
求高手解答,万分感谢!
蓝鱼:非常强大的网页编辑器,同时还完善。支持语法高亮,项目管理,并配备了HTML和PHP手册。
的Websphere网页建设者
的Websphere主页制造商是IBM生产的WYSIWYG HTML编辑工具,用户无需了解HTML语法和复杂的CSS / DHTML知识,将能够创造一个美丽的页面。
以上是关于python下用selenium的webdriver包如何取得打开页面的html源代码呢的主要内容,如果未能解决你的问题,请参考以下文章
python下用selenium的webdriver包如何在执行完点击下一页后没有获得下一页新打开页面的html源代码
早上在linux下用selenium启动Chrome时出现问题: