正则表达式 提取内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式 提取内容相关的知识,希望对你有一定的参考价值。
比如源码中包含
</span><span data-jsx="468416" data-reactid="41">要提取的内容<br>
</span><span data-jsx="24661" data-reactid="79">要提取的内容<br>
</span><span data-jsx="2643468" data-reactid="113">要提取的内容<br>
</span><span data-jsx="271131960" data-reactid="215">要提取的内容<br>
这个该怎么写,谢谢各位解答
var text = \'</span><span data-jsx="468416" data-reactid="41">要提取的内容< br>\'
var reg = /data-reactid="\\d+">(.*)< br>/g;
var group1 = reg.exec(text)[1];//要提取的内容
/**
正则中,使用()包含起来的内容可以捕获;
要正确匹配要捕获的内容,跟要处理的字符串环境有关,越复杂的字符串,正则就越复杂;像(.*)就只能捕获没换行符的内容,
**/ 参考技术A <span .*?>(.+?)<br>
正则表达式 -- 提取并替换 ${} 之间的内容
一、提取 ${} 之间的内容
1、正则表达式
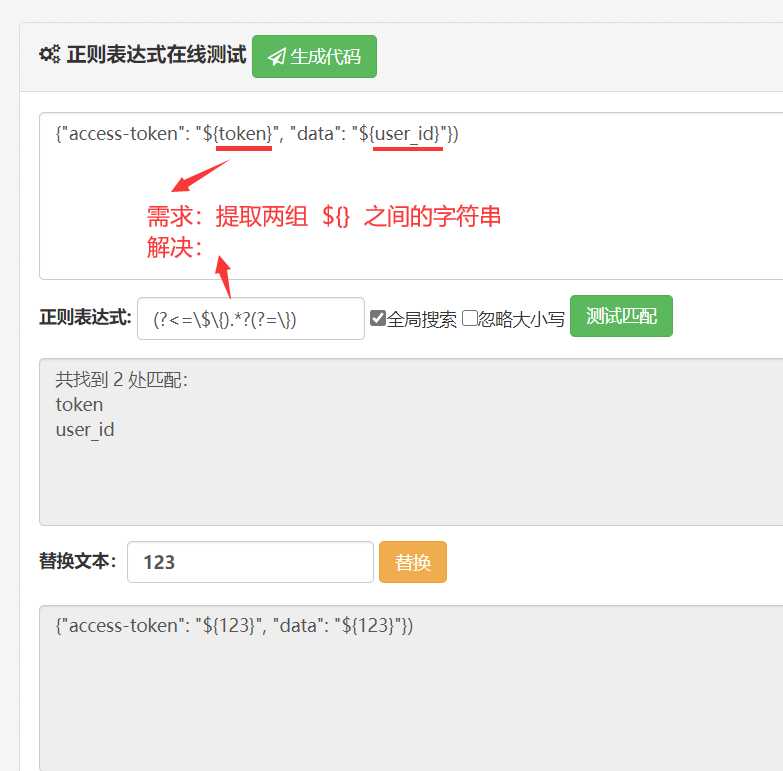
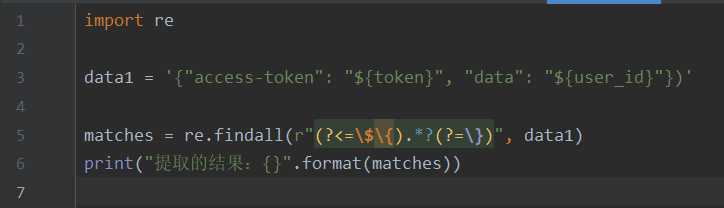
2、用 Python的正则 提取

二、替换 ${} 之间的内容
1、替换
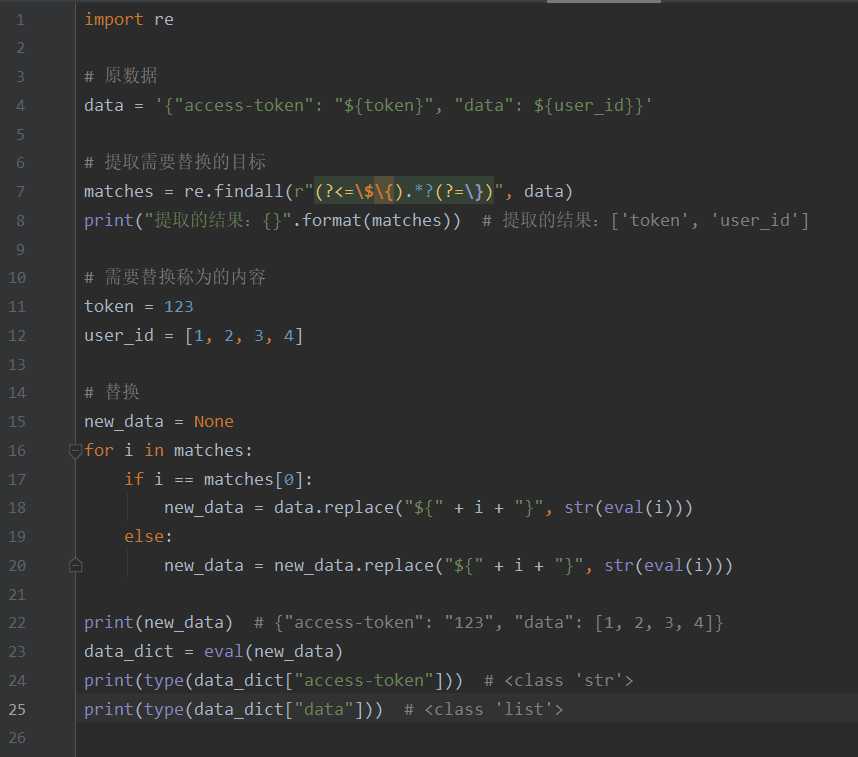
2、封装成专门的替换函数
import re def my_split(resource_data: str, split_content: dict): """ :param resource_data: 被替换的原数据 :param split_content: 需要替换的内容 """ matches = re.findall(r"(?<=${).*?(?=})", resource_data) # 提取需要替换的目标 new_data = None # 替换后的数据 for i in matches: # 替换过程 new_value = split_content[i] if i == matches[0]: new_data = resource_data.replace("${" + i + "}", str(new_value)) else: new_data = new_data.replace("${" + i + "}", str(new_value)) return new_data # 开始调试 old_data = ‘{"access-token": "${token}", "data": ${user_id}, "phone_code": ${code}}‘ spilt_data = {"token": "123asf6549qewA+-*asd", "user_id": [1, 2, 3, 4], "code": 1356} new_data0 = my_split(old_data, spilt_data) print(new_data0) # {"access-token": "123asf6549qewA+-*asd", "data": [1, 2, 3, 4], "phone_code": 1356} data_dict = eval(new_data0) print(type(data_dict["access-token"])) # <class ‘str‘> print(type(data_dict["data"])) # <class ‘list‘> print(type(data_dict["phone_code"])) # <class ‘int‘>
以上是关于正则表达式 提取内容的主要内容,如果未能解决你的问题,请参考以下文章