机器学习入门系列01,Introduction 简介
Posted yofer张耀琦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习入门系列01,Introduction 简介相关的知识,希望对你有一定的参考价值。
Gitbook整理地址:https://yoferzhang.gitbooks.io/machinelearningstudy/content/20170326ML01Introduction.html
我们将要学习什么东东?
什么是机器学习?

有右边这样非常大的音频数据集,写程序来进行学习,然后可以输出音频“Hello”

有右边这样非常大的图片数据集,写程序来进行学习,然后可以识别左边这样图,识别为正确的物种。
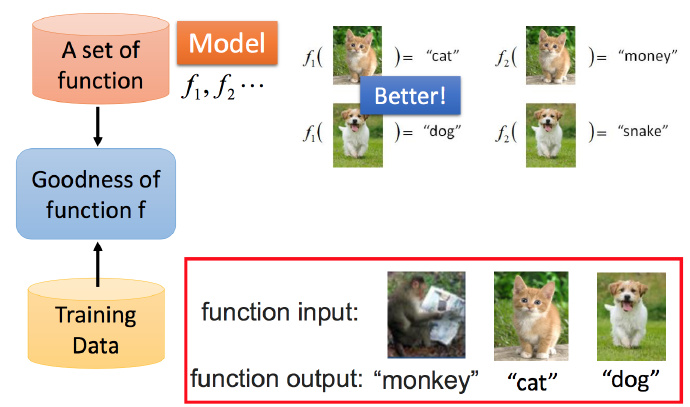
机器学习 ≈ 寻找一个函数

Framework 框架
- Image Recognition 图像识别

函数集( f1,f2,… ),通常将一个函数称为Model(模型)

为了找到最好的函数 f ,将训练集图像放入函数集的输入中,函数集输出识别结果。
下面来看具体步骤
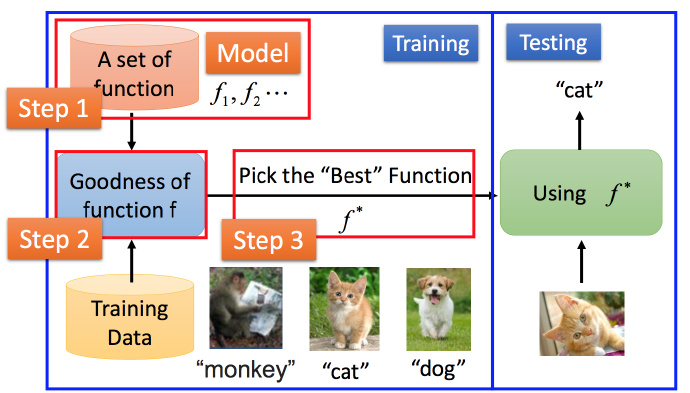
Step1.确定一组函数(Model),函数集怎么找后面会再介绍。
Step2.将训练集对函数集进行训练。
Step3.挑选出“最好”的函数
然后就可以使用
f∗
来对新的测试集进行检测。
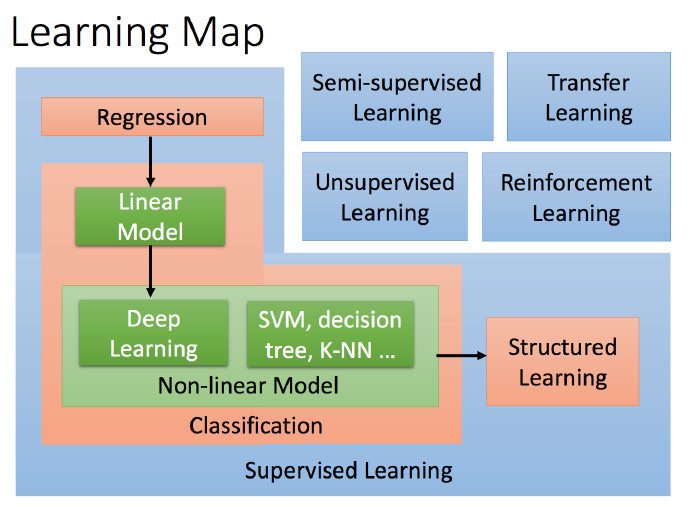
整体都学习哪些知识(Learning Map)
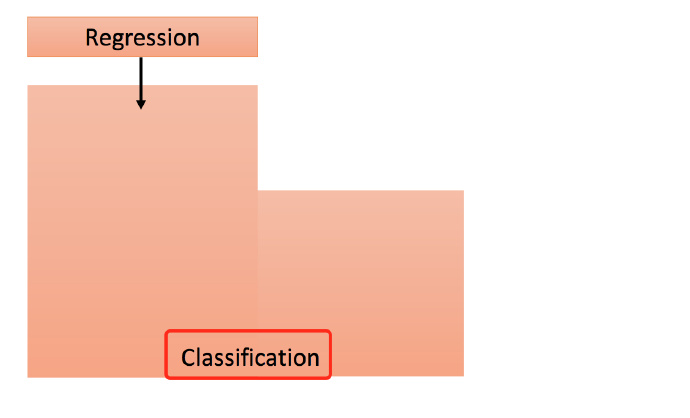
Regression(回归)是什么?
Regression 意思是,我们要找到这样一个函数 f <script type="math/tex" id="MathJax-Element-6">f</script>,使得输出为 scalar(标量,数值)
这里说法当然是比较不严谨,数学上简单的线性,一元或多元回归的知识可以在概率论与数理统计课本中进行学习。《概率论与数理统计》,浙江大学,第九章,P244。
举个例子,比如预测PM2.5.

输入就是之前每一天的PM2.5数值,输出是明天的PM2.5,是个标量。
具体做法:

Classification(分类)
分类比较容易理解,比如二元分类或者多元分类。
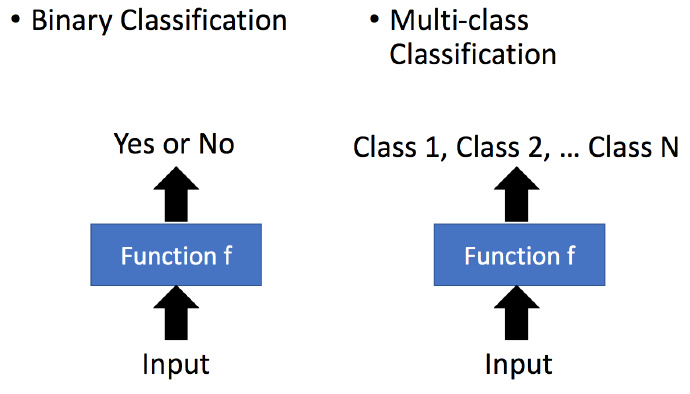
Binary Classification(二元分类)
比如垃圾邮件过滤,就是要找到一个Function,输入为一封邮件,输出是二元的,是或者不是垃圾邮件。训练集就是很多封邮件,每一封邮件知道它是否是垃圾邮件,让Function进行学习。

Multi-class Classification(多元分类)
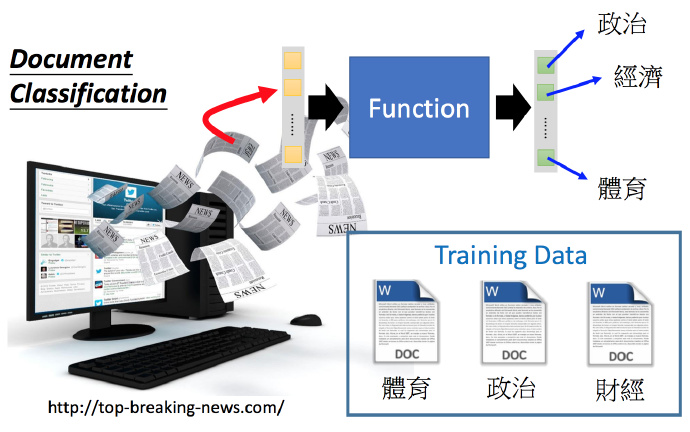
多元分类;例如下面的新闻分类系统,找一个Function,输入就是新闻的内容,输出则是新闻的类型(政治,经济,体育等等)
Deep Learning(深度学习)
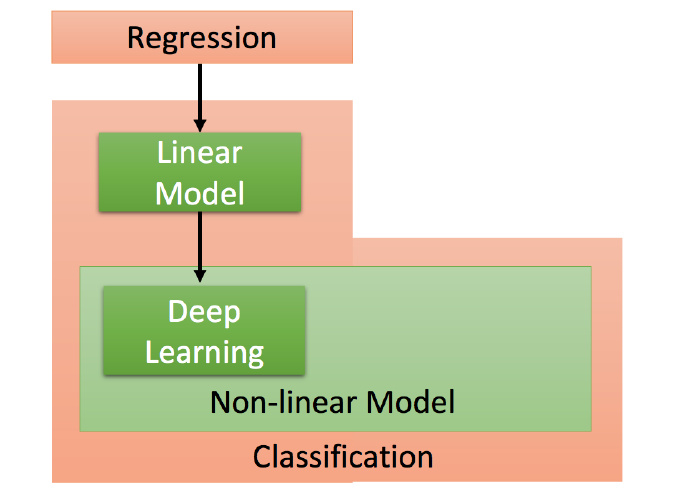
上面讲过,机器学习的第一个步骤就是确定一个函数集,可以选择Linear Model(线性模型),但是 Linear Model 比较有限。更多的则是 Non-lilnear Model(非线性模型)。比如深度学习就是 Non-lilnear Model 。
举个例子,比如图像识别:

这里举例深度学习中的一种,Convolutional Neural Network(CNN,卷积神经网络),输入就是很多的图像,输出为图像的类型,这里将每个对象都当作一个类别。训练集就是很多张图片,并告诉机器每张图片对应的是什么类型。深度学习的Function非常复杂。
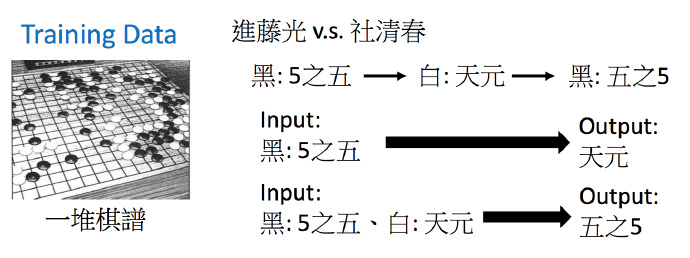
再举一个例子,下围棋:
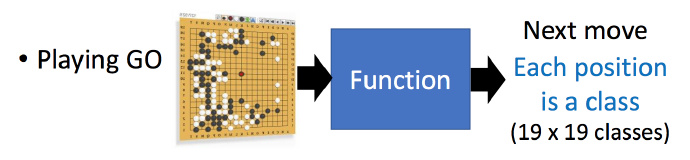
输入就是黑白子在19*19棋盘上的位置,输出就是下一步应该下在哪里。这也就是一个选择题,可能的选项有19*19个。

训练集就是一堆棋谱,每一步是怎么走的。
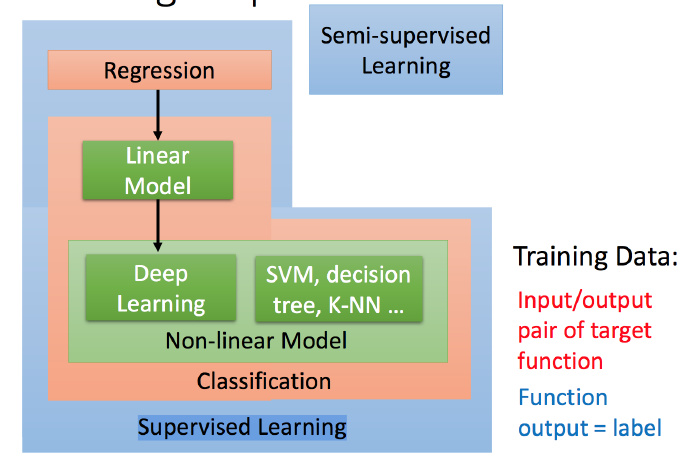
Supervised Learning(有监督学习)
Non-lilnear Model 不只Deep Learning,后面还会接触到SVM,decision tree等。
上面提到这些我们都叫做Supervised Learning(有监督学习),所谓 Supervised Learning 就是说训练集的输入和输出对于目标函数是成对的,目标函数看到一个输入,就应该对应有一个输出。也把这样的输出叫做 label。
见到说需要 Labelled data 的情况,就是指我们要告诉机器看到一个输入,要有一个输出。
其他的比如还有Semi-supervised Learning(半监督学习)
Semi-supervised Learning(半监督学习)
比如图像识别一些猫和狗,Labelled data 就是训练集中每个图片知道它对应的是什么类型。而Unlabelled data 就是不知道图片对应的类型。这种其实也是可以让机器学习的比较好的,后面也会介绍。

Transfer Learning(迁移学习)
举例说一下迁移学习:

比如有 Labelled data ,但我们还有一些labelled 或者 unlabelled 数据,这些数据和 Labelled data 中识别猫和狗都没有关系,但它也是怎么帮助Labelled data 更好的识别。这就是 Transfer Learning 要做的事情。
Unsupervised Learning(无监督学习)
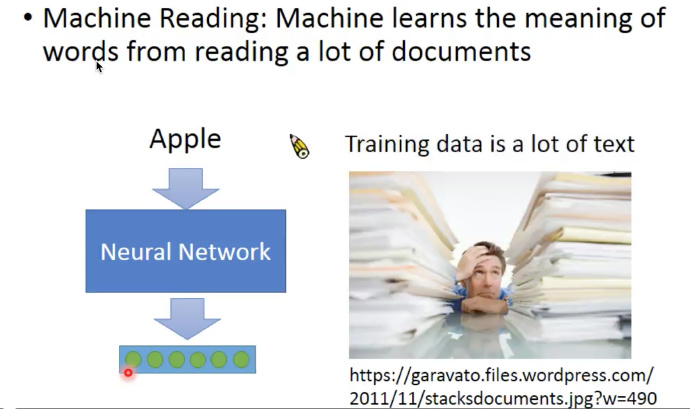
举一个Unsupervised Learning 的例子:让机器阅读非常多的文章,然后机器就可以学习单词的含义。

这个Unsupervised Learning 的例子中,训练集只有输入(很多的文章),没有输出。假设通过Neural Network(神经网络)学习之后,给一个单词,就可以输出一个向量。
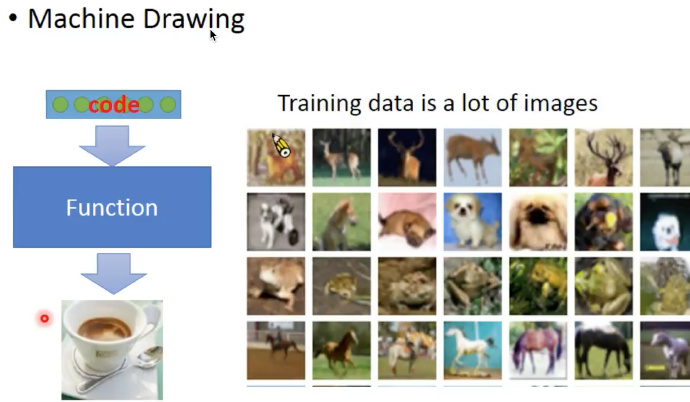
再举一个例子:比如想要让机器绘制一下自己的内心世界。

具体说就是给机器一堆数字,他就能自己绘制一张图片,此时训练集只有输出(很多的图片),没有输入。
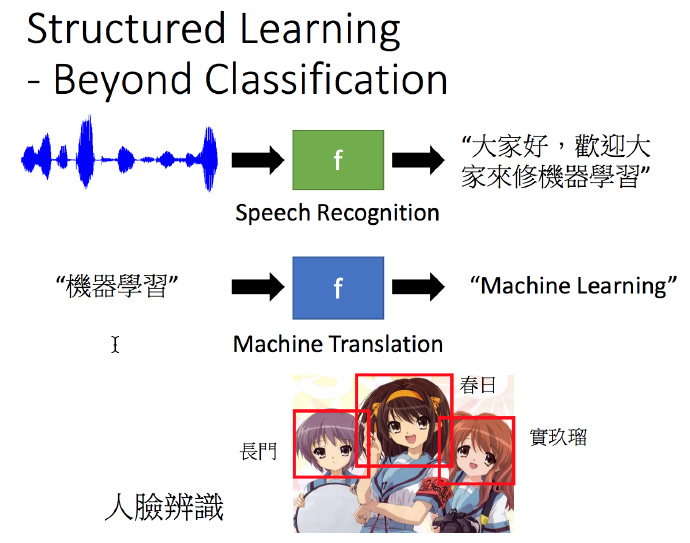
Structured Learning(结构化学习)
比如看下面例子:第一个是语音识别,假设我们想要找的function是输入一段语音,然后输出语音的文字。如果把世界上不同的句子当作一个类别,这样是没有办法穷举所有类型的,所以这种超越分类的问题,就需要另外一套完整的思想来解决。
还有例子就是机器翻译,将中文翻译成英文,也是没有办法穷举所有的句子。再或者人脸识别,没有办法穷举所有人脸框。
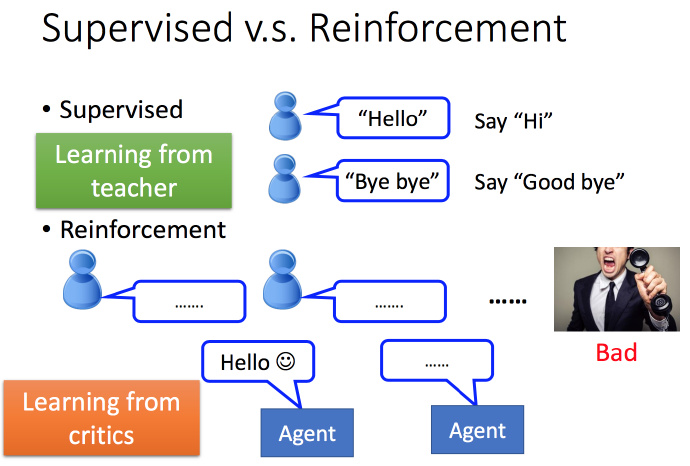
Reinforcement Learning(增强学习)
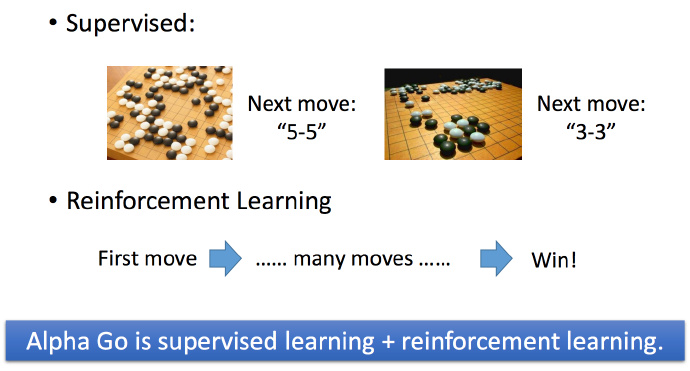
举个Reinforcement Learning 的例子:AlphaGo。
举例来比较 Supervised 和 Reinforcement:比如学习对话,Supervised 训练集每句话,都有对应的输出;但是Reinforcement就只是不断的对话,机器只能知道它做的好或者不好,没有其他更多的信息。
再举一个围棋的例子,比如 Supervised 情况就是机器看到一个棋局,告诉它下一步应该走什么。Reinforcement 的情况就是走了很多步,输了或者赢了,就是知道一个结果。AlphaGo 就是两个都用到了,先看棋谱学习,但是棋谱的数量是有限的,然后再进行增强型学习。所以 AlphaGo 第一轮和世界高手对局时还捉襟见肘,第二轮就基本横扫了。
理解Learning Map颜色的意义
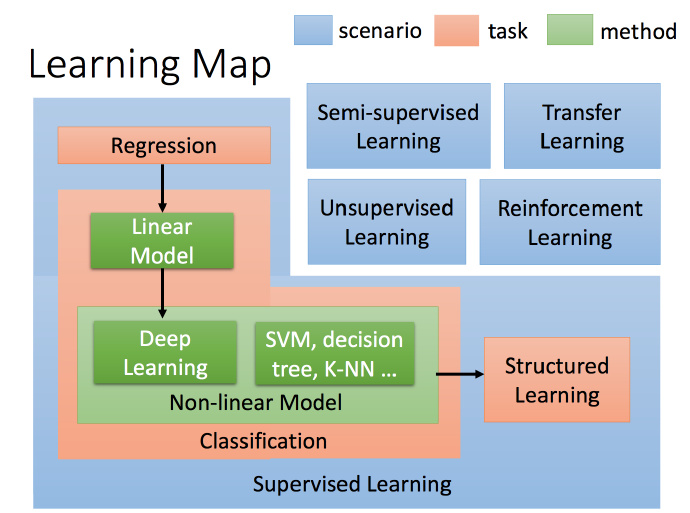
蓝色的都是代表Scenario(方案),红色部分指的是你要找的function的样子,可以在Semi-supervised Learning 的情况下做红色的task,也可以在 Transfer Learning下做红色task,就是右上角的4个虽然是小方块,但是 Supervised Learning 里面的 task 都可以在其他蓝色 scenario 中做。绿色的部分就是方法或者说模型,绿色的内容虽然写在 Classification 里面,但是可以放在 Regression 或者 Structured Learning 中。
新博客文章地址:http://yoferzhang.com/post/20170326ML01Introduction/
CSDN博客文章地址:http://blog.csdn.net/zyq522376829/article/details/66478149
以上是关于机器学习入门系列01,Introduction 简介的主要内容,如果未能解决你的问题,请参考以下文章