搜索引擎原理和简单过程
Posted 日月心诚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索引擎原理和简单过程相关的知识,希望对你有一定的参考价值。
搜索引擎原理
原文链接:http://www.cnblogs.com/seaspring/
1.1 常用的非结构化数据检索方法
按照上节所说,搜索引擎主要处理的是非结构化数据,故名思议,非结构化数据的特点就是没有固定的结构,这也正是处理比较困难的原因;结构化数据可以通过数据库等方式处理。非结构化数据如何处理,据说有两种方法:
一种是顺序搜索,比如在linux下用grep方式来搜索包含特定字符串的文档,这在文档数量少的时候比较有效。
二种是全文检索,它是通过对非结构化数据进行结构化转化,对非结构化数据进行抽取(从文档中抽取词),然后重新组合,再利用它进行搜索。
这个被抽取出来重新组织的信息称为索引。
第二种方法是搜索引擎中用的主要方法了。
1.2 全文检索的三大问题
这就涉及到三个问题:1、索引里面保存什么信息?2、索引如何建立? 3、如何利用索引进行搜索?
索引保存的是什么
让我们思考下,既然全文搜索是通过建立索引的方式进行搜索的,那么我们的索引内容必然是为了方便查找到我们要的信息的。
以搜索文章为例,假如我们需要海量的文章,为了方便管理我们给这些文章进行编号,
搜索就是要找到搜索关键词和文章编号的对应关系,然后通过编号再找到对应的文档。那么很自然的存储的索引的内容必然有和关键字匹配的部分,还有文章编号的部分。
实际情况也是如此,全文搜索建立的索引简单来说就是词和文章编号的对应关系,由于一个词可以放在多个文章中,所以这种索引一般就是一个个词后面对应一串文章编号(文档编号链表)。
从文章对应词比较自然,所以从词对应文档是文档对应词的反过程,保存这种信息的索引称为反向索引(倒排索引)。
盗用一张网上说明Lucene的倒排索引原理图,solr是基于Lucene的,所以solr的索引也是倒排索引。
倒排索引结构
一开始有点蒙,倒排序怎么个倒排序,那正排序又是什么?后来在网上找到一篇文章,正排索引和倒排索引。
正排索引
主要的意思就是说,当网络爬虫在Internet上收集信息的时候,会把收集到的网页进行处理,就是把对网页的内容进行分词(关键词),可以看成这样:

具体怎么分词大家可以去了解了解分词器,中文的分词和英文的分词是不一样的。原理如下:
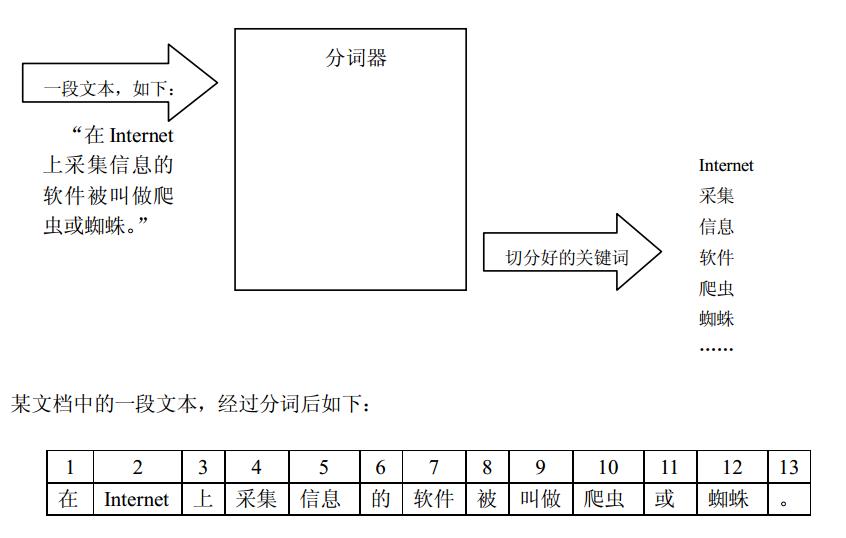
正如上面的这个过程,把一个网页分成一个个的关键词的过程就是一个正排索引的过程。
倒排索引
用户查信息的时候,一般都是通过关键词来查询相应的信息。
倒排索引是这样的,倒排索引这个关键词之后跟了一堆网页。

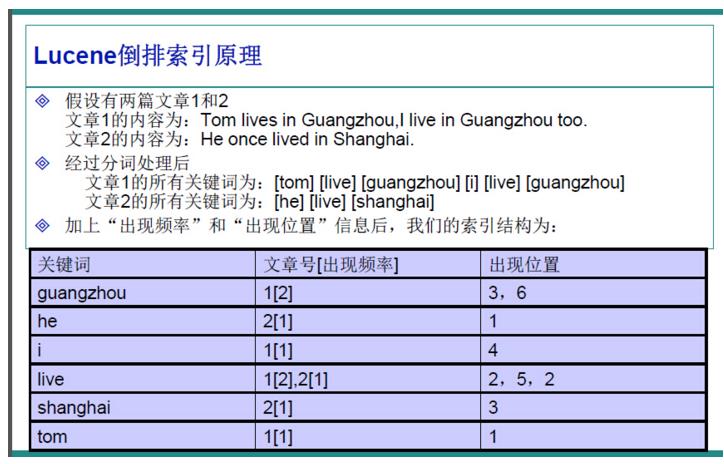
这里面,关键词一般叫词典,后面对应的一串文档号文章号叫做倒排表。
索引如何建立
创建索引的过程盗用个网上图,索引过程如下:

我们来思考下,我们要建立的索引为倒排索引即是词典和倒排表。
我们首先要从文档中得到词,所以我们首要工作是分词,这里面用到的就是分词组件(Tokenizer)本次得到的结果是词元(Token)。
其次从词元(Token)经过语言处理组件(Linguistic Processor)的处理,输出为词(Term)。这一部分主要完成的是词义转化等
词边变的更纯碎些。最后一步就是将词传递给相关的索引组件,建立索引。
1、分词做的主要工作
1)切词,英语比较好拆分就是按照空格分隔,汉字要涉及到利用词典进行切词或单独按照字来进行切词。
2)去掉标点符号。
3)去掉停词,停词是指语言中没有特殊含义的副词,比如英语中的this、is、a、汉语中的“的”等。
在solr中有专门的配置文件配置停词,stopwords_开头的配置文件。
使得到的词更有意义,减少索引的长度,因为停词在很多文档中都有,如果加到索引里面,后面的文档号要排很长,专业名词叫拉链过长。
不光占用过多的空间,而且还会导致搜索变慢。
中文由于没有明显的词语直接的间隔,所以中文分词要复杂的多。solr中默认StandardTokenizerFactory是按照字来分隔,好处是实现字级匹配,坏处索引变大。
也可以利用网上开源的分词组件,比如:庖丁分词、IK分词等。
效率solr默认的分词的建索引效率大概是IK分词的1倍,但是查询效率却慢4倍原因,是按字分词拉链过长原因。
2、语言处理主要工作
1)对英语来说是大小写转换。
2)将词缩减或简化为词根。(比如cars转成car、running转成run)
语言处理组件得到的结果是为Term(词)。
3、将此传递给索引组件
1)利用词创建词典和文档ID的对应关系表。
2)按照字典顺序对词典进行排序。
3)合并相同的词典,文档ID变成文档ID链表。
实际建立的倒排索引,还包含词在文档中的位置、出现的频次等信息。
搜索过程
1)我们利用搜索引擎的语法输入查询的语句。我们常用的搜索引擎百度
常用语法举例子如下:
1. 如果你想让百度作为整体搜索而不进行分词,用双引号包括。
2. 如果你不想要一些信息可以用-号,比如手机-推广,将不会显示百度的推广广告。
3. 比如搜索关键词之间是或者关系,可以通过搜索xxx|yyy方式搜索。
2) 对查询的语句进行词法分析、语法分析和语义处理。
类似建索引的过程,需要进行分词、转化后,还有多一个内容要区分关键字和搜索词、
关键字代表搜索词之间的逻辑关系,在solr搜索中是op标示,比如AND标示逻辑与、
OR标示或关系,经过这种语法分析后形成一个语法树。
3)搜索
在solr中大概分为三步完成:
1、在反向索引表中查找符合要求的文档ID。第一次查询返回的是文档ID和匹配度得分。
2、根据语法树进行逻辑与或或等操作,得到最终符合要求的文档ID列表。
3、通过这些文档ID列表,结合要求查询的内容去查询具体到具体的内容信息返回。
4)排序返回
文档列表查到之后,把查询的语句当做一个文档,来计算被查询的文档和查询到的文档之间的相关度,并进行打分,
相关度高的排在前面。
相关度得分的计算比较复杂,主要涉及有:
词频TF: 即词在文档中出现的次数。
DF: 即这个词在多少个文档中出现。
词的权重:词在文档中的重要性。
以上是关于搜索引擎原理和简单过程的主要内容,如果未能解决你的问题,请参考以下文章