Linux转发性能评估与优化-转发瓶颈分析与解决方式(补遗)
Posted yxwkaifa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux转发性能评估与优化-转发瓶颈分析与解决方式(补遗)相关的知识,希望对你有一定的参考价值。
补遗
关于网络接收的软中断负载均衡,已经有了成熟的方案,可是该方案并不特别适合数据包转发,它对server的小包处理非常好。这就是RPS。我针对RPS做了一个patch。提升了其转发效率。
下面是我转载的我自己的原文。
线速问题
非常多人对这个线速概念存在误解。觉得所谓线速能力就是路由器/交换机就像一根网线一样。而这。是不可能的。应该考虑到的一个概念就是延迟。数据包进入路由器或者交换机。存在一个核心延迟操作,这就是选路,对于路由器而言。就是路由查找,对于交换机而言,就是查询MAC/port映射表,这个延迟是无法避开的,这个操作须要大量的计算机资源,所以无论是路由器还是交换机,数据包在内部是不可能像在线缆上那样近光速传输的。
类比一下你经过十字街头的时候,是不是要左顾右盼呢?
那么,设备的线速能力怎么衡量呢?假设一个数据包经过一个路由器。那么延迟必览无疑。可是设备都是有队列或者缓冲区的,那么试想一个数据包紧接一个数据包从输入port进入设备,然后一个数据包紧接一个数据包从输出port发出,这是能够做到的。我们对数据包不予编号,因此你也就无法推断出来的数据包是不是刚刚进去的那个了。这就是线速。
我们能够用电容来理解转发设备。有人可能会觉得电容具有通高频阻低频的功效,我说的不是这个,所以咱不考虑低频。仅以高频为例,电容具有存储电荷的功能,这就相似存储转发,电容充电的过程相似于数据包进入输入队列缓冲区。电容放电的过程相似于数据包从输出缓冲区输出,我们能够看到,在电流经过电容的前后,其速度是不变的,然而针对详细的电荷而言,从电容放出的电荷绝不是刚刚在在还有一側充电的那个电荷,电容的充电放电拥有固有延迟。
我们回到转发设备。
对于交换机和路由器而言。衡量标准是不同的。
对于交换机而言。线速能力是背板总带宽,由于它的查表操作导致的延迟并不大。大量的操作都在数据包通过交换矩阵的过程,因此背板带宽直接导致了转发效率。
而对于路由器。衡量标准则是一个port每秒输入输出最小数据包的数量,假设数据包以每秒100个进入,每秒100个流出。那么其线速就是100pps。
本文针对路由器而不针对交换机。
路由器的核心延迟在路由查找,而这个查找不会受到数据包长度的影响。因此决定路由器线速能力的核心就在数据包输出的效率。注意,不是数据包输入的效率,由于仅仅要队列足够长。缓存足够大,输入总是线速的。可是输入操作就涉及到了怎样调度的问题。
这也就说明了为何非常多路由器都支持输出流量控制而不是输入流量控制的原因,由于输入流控即使完美完毕,它也会受到路由器输出port自身输出效率的影响。流控结果将不再准确。
在写这个方法的前晚,有一个故事。
我近期联系到了初中时一起玩摇滚玩音响的超级铁的朋友,他如今搞舞台设计,灯光音响之类的。我问他在大型舞台上。音箱摆放的位置不同,距离后级,前置。音源也不同,怎么做到不同声道或者相同声道的声音同步的,要知道,好的耳朵能够听出来毫秒级的音差...他告诉我要统一到达时间,即统一音频流到达各个箱子的时间,而这要做的就是调延迟。要求不同位置的箱子路径上要有不同的延迟。这对我的设计方案的帮助是多么地大啊。
然后。在第二天,我就開始整理这个令人悲伤终于心碎的Linux转发优化方案。
声明:本文仅仅是一篇普通文章,记录这个方法的点点滴滴,并非一个完整的方案。请勿在格式上较真,内容上也仅仅是写了些我觉得重要且有意思的。完整的方案是不便于以博文的形式发出来的。
见谅。
问题综述
Linux内核协议栈作为一种软路由运行时,和其他通用操作系统自带的协议栈相比,其效率并非例如以下文所说的那样非常低。然而基于工业路由器的评判标准。确实是低了。
市面上各种基于Linux内核协议栈的路由器产品,甚至网上也有大量的此类文章,比方什么将Linux变成路由器之类的。无非就是打开ip_forward,加几条iptables规则,搞个配置起来比較方便的WEB界面...我想说这些太低级了,甚至超级低级。我非常想谈一下关于专业路由器的我的观点。可是今天是小小的生日,玩了一天,就不写了。仅仅是把我的方案整理出来吧。
Linux的转发效率究竟低在哪儿?怎样优化?这是本文要解释的问题。
依旧如故,本文能够随意转载并基于这个思路实现编码,可是一旦用于商业目的,不保证没有个人或组织追责。因此文中我尽量採用尽可能模糊的方式阐述细节。
瓶颈分析概述
1.DMA和内存操作
我们考虑一下一个数据包转发流程中须要的内存操作,临时不考虑DMA。*)数据包从网卡复制到内存
*)CPU訪问内存读取数据包元数据
*)三层报头改动,如TTL
*)转发到二层后封装MAC头
*)数据包从内存复制到输出网卡
这几个典型的内存操作为什么慢?为什么我们总是对内存操作有这么大的意见?由于訪问内存须要经过总线。首先总线竞争(特别在SMP和DMA下)就是一个打群架的过程。另外由于内存自身的速度和CPU相比差了几个数量级。这么玩下去。肯定会慢啊!所以一般都是尽可能地使用CPU的cache。而这须要一定的针对局部性的数据布局,对于数据包接收以及其他IO操作而言。由于数据来自外部。和进程运行时的局部性利用没法比。所以必须採用相似Intel I/OAT的技术才干改善。
1.1.Linux作为server时
採用标准零拷贝map技术全然胜任。这是由于。运行于Linux的server和线速转发相比就是个蜗牛。server在处理client请求时消耗的时间是一个硬性时间。无法优化,这是代偿原理。Linux服务唯一须要的就是能高速取到client的数据包,而这能够通过DMA高速做到。本文不再详细讨论作为server运行的零拷贝问题,自己百度吧。1.2.Linux作为转发设备时
须要採用DMA映射交换的技术才干实现零拷贝。这是Linux转发性能低下的根本。由于输入port的输入队列和输出port的输出队列互不相识,导致了不能更好的利用系统资源以及多port数据路由到单port输出队列时的队列锁开销过大。总线争抢太严重。DMA影射交换须要超级棒的数据包队列管理设施,它用来调度数据包从输入port队列到输出port队列,而Linux差点儿没有这样的设施。
尽管近年在路由器领域有人提出了输入队列管理。可是这项技术对于Linux而言就是还有一个世界,而我。把它引入了Linux世界。
2.网卡对数据包队列Buff管理
在Linux内核中,差点儿对于全部数据结构,都是须要时alloc,完毕后free。即使是kmem_cache。效果也一般。特别是对于高速线速设备而言(skb内存拷贝,若不採用DMA,则会频繁拷贝,即便採用DMA。在非常多情况下也不是零拷贝)。
即使是高端网卡在skb的buffer管理方面,也没有使用全然意义上的预分配内存池,因此会由于频繁的内存分配。释放造成内存颠簸,众所周知,内存操作是问题的根本。由于它涉及到CPU Cache。总线争抢。原子锁等,实际上,内存管理才是根本中的根本,这里面道道太多,它直接影响CPU cache,后者又会影响总线...从哪里分配内存。分配多少,何时释放。何时能够重用,这就牵扯到了内存区域着色等技术。通过分析Intel千兆网卡驱动。在我看来,Linux并没有做好这一点。
3.路由查找以及其他查找操作
Linux不区分对待路由表和转发表,每次都要最长前缀查找,尽管海量路由表时trie算法比hash算法好,可是在路由分布畸形的情况下依旧会使trie结构退化。或者频繁回溯。路由cache效率不高(查询代价太大,不固定大小。仅有弱智的老化算法,导致海量地址訪问时,路由cache冲突链过长),终于在内核协议栈中下课。
假设没有一个好的转发表,那么Linux协议栈在海量路由存在时对于线速能力就是一个瓶颈。这是一个可扩展性问题。
另外,非常多的查询结果都是能够被在一个地方缓存的,可是Linux协议栈没有这样的缓存。比方,路由查询结果就是下一跳,而下一跳和输出网卡关联。而输出网卡又和下一跳的MAC地址以及将要封装的源MAC地址关联。这些本应该被缓存在一个表项,即转发表项内,然而Linux协议栈没有这么做。
4.不合理的锁
为何要加锁,由于SMP。然而Linux内核差点儿是对称的加锁,也就是说,比方每次查路由表时都要加锁。为何?由于怕在查询的期间路由表改变了...然而你细致想想,在高速转发情景下,查找操作和改动操作在单位时间的比率是多少呢?不要以为你用读写锁就好了,读写锁不也有关抢占的操作吗(尽管我们已经建议关闭了抢占)?起码也浪费了几个指令周期。这些时间几率不正确称操作的加锁是不必要的。你仅仅须要保证内核本身不会崩掉就可以,至于说IP转发的错误,无论也罢。依照IP协议,它本身就是一个尽力而为的协议。
5.中断与软中断调度
Linux的中断分为上半部和下半部,动态调度下半部,它能够在中断上下文中运行,也能够在独立的内核线程上下文中运行,因此对于实时需求的环境。在软中断中处理的协议栈处理的运行时机是不可预知的。Linux原生内核并没有实现Solaris,Windows那样的中断优先级化,在某些情况下。Linux靠着自己动态的且及其优秀的调度方案能够达到极高的性能,然而对于固定的任务,Linux的调度机制却明显不足。而我须要做的,就是让不固定的东西固定化。
6.通用操作系统内核协议栈的通病
作为一个通用操作系统内核。Linux内核并非仅仅处理网络数据,它还有非常多别的子系统。比方各种文件系统,各种IPC等,它能做的仅仅是可用,简单,易扩展。Linux原生协议栈全然未经网络优化,且基本装机在硬件相同也未经优化的通用架构上,网卡接口在PCI-E总线上,假设DMA管理不善,总线的占用和争抢带来的性能开销将会抵消掉DMA本意带来的优点(其实对于转发而言并没有带来什么优点。它仅仅对于作为server运行的Linux有优点。由于它仅仅涉及到一块网卡)
[注意。我觉得内核处理路径并非瓶颈。这是分层协议栈决定的。瓶颈在各层中的某些操作,比方内存操作(固有开销)以及查表操作(算法不好导致的开销)]
综述:Linux转发效率受到下面几大因素影响
IO/输入输出的队列管理/内存改动拷贝 (又一次设计相似crossbar的队列管理实现DMA ring交换)
各种表查询操作,特别是最长前缀匹配。诸多本身唯一确定的查询操作之间的关联没有建立
SMP下处理器同步(锁开销)(使用大读锁以及RCU锁)以及cache利用率
中断以及软中断调度
Linux转发性能提升方案
概述
此方案的思路来自基于crossbar的新一代硬件路由器。设计要点:1.又一次设计的DMA包管理队列(思路来自Linux O(1)调度器,crossbar阵列以及VOQ[虚拟输出队列])
2.又一次设计的基于定位而非最长前缀查找的转发表
3.长线程处理(中断线程化,处理流水线化,添加CPU亲和)
4.数据结构无锁化(基于线程局部数据结构)
5.实现方式
5.1.驱动以及内核协议栈改动
5.2.全然的用户态协议栈
5.3.评估:用户态协议栈灵活,可是在某些平台要处理空间切换导致的cache/tlb/mmu表的flush问题
内核协议栈方案
优化框架
0.例行优化
1).网卡多队列绑定特定CPU核心(利用RSS特性分别处理TX和RX)[能够參见《Effective Gigabit Ethernet Adapters-Intel千兆网卡8257X性能调优》]
2).依照包大小统计动态开关积压延迟中断ThrottleRate以及中断Delay(对于Intel千兆卡而言)
3).禁用内核抢占,降低时钟HZ。由中断粒度驱动(见上面)
4).假设不准备优化Netfilter。编译内核时禁用Netfilter,节省指令
5).编译选项去掉DEBUG和TRACE,节省指令周期
6).开启网卡的硬件卸载开关(假设有的话)
7).最小化用户态进程的数量,降低其优先级
8).原生网络协议栈优化
由于不再作为通用OS。能够让除了RX softirq的task适当饥饿
*CPU分组(考虑Linux的cgroup机制),划一组CPU为数据面CPU。每个CPU绑定一个RX softirq或者
*添加rx softirq一次运行的netdev_budget以及time limit,或者
*仅仅要有包即处理。每个。控制面/管理面的task能够绑在别的CPU上。
宗旨:
原生协议栈的最优化方案
1.优化I/O。DMA。降低内存管理操作
1).降低PCI-E的bus争用,採用crossbar的全交叉超立方开关的方式[Tips:16 lines 8 bits PCI-E总线拓扑(非crossbar!
)的网络线速不到满载60% pps
]2).降低争抢式DMA。降低锁总线[Tips:优化指令LOCK,最好採用RISC,方可调高内核HZ]
[Tips:交换DMA映射,而不是在输入/输出buffer ring之间拷贝数据!如今,仅仅有傻逼才会在DMA情况拷贝内存,正确的做法是DMA重映射,交换指针!]
3).採用skb内存池,避免频繁内存分配/释放造成的内存管理框架内的抖动
[Tips:每线程负责一块网卡(甚至输入和输出由不同的线程负责会更好),保持一个预分配可循环利用的ring buffer,映射DMA]
宗旨:
降低cache刷新和tlb刷新。降低内核管理设施的工作(比方频繁的内存管理)
2.优化中断分发
1).添加长路径支持,降低进程切换导致的TLB以及Cache刷新2).利用多队列网卡支持中断CPU亲和力利用或者模拟软多队列提高并行性
3).牺牲用户态进程的调度机会,全部精力集中于内核协议栈的处理,多CPU多路并行的
[Tips:假设有超多的CPU。建议划分cgroup]
4).中断处理线程化,内核线程化。多核心并行运行长路经。避免切换抖动
5).线程内部,依照IXA NP微模块思想採用模块化(方案未实现,待商榷)
宗旨:
降低cache刷新和tlb刷新
降低协议栈处理被中断过于频繁打断[要么使用IntRate,要么引入中断优先级]
3.优化路由查找算法
1).分离路由表和转发表,路由表和转发表同步採用RCU机制2).尽量採用线程局部数据
每个线程一张转发表(由路由表生成。OpenVPN多线程採用,但失败)。採用定位而非最长前缀查找(DxR或者我设计的那个)。若不採用为每个线程复制一份转发表,则须要又一次设计RW锁或者使用RCU机制。
3).採用hash/trie方式以及DxR或者我设计的DxRPro定位结构
宗旨:
採用定位而非查找结构
採用局部表,避免锁操作
4.优化lock
1).查询定位局部表。无锁(甚至RW锁都没有)不禁止中断2).临界区和内核线程关联。不禁中断,不禁抢占(其实内核编译时抢占已经关闭了)
3).优先级锁队列替换争抢模型。维持cache热度
4).採用Windows的自旋锁机制
[Tips:Linux的ticket spin lock由于採用探測全局lock的方式,会造成总线开销和CPU同步开销,Windows的spin lock採用了探測CPU局部变量的方式实现了真正的队列lock,我设计的输入输出队列管理结构(下面详述)思路部分来源于Windows的自旋锁设计]
宗旨:锁的粒度与且仅与临界区资源关联,粒度最小化
优化细节概览
1.DMA与输入输出队列优化
1.1.问题出在哪儿
假设你对Linux内核协议栈足够熟悉,那么就肯定知道,Linux内核协议栈正是由于软件project里面的天天普及的“一件好事”造成了转发性能低效。这就是“解除紧密耦合”。Linux协议栈转发和Linuxserver之间的根本差别在于,后者的应用服务并不在乎数据包输入网卡是哪个,它也不必关心输出网卡是哪一个,然而对于Linux协议栈转发而言,输入网卡和输出网卡之间确实是有必要相互感知的。Linux转发效率低的根本原因不是路由表不够高效,而是它的队列管理以及I/O管理机制的低效。造成这样的低效的原因不是技术实现上难以做到,而是Linux内核追求的是一种灵活可扩展的性能,这就必须解除出入网卡,驱动和协议栈之间关于数据包管理的紧密耦合。
我们以Intel千兆网卡驱动e1000e来说明上述的问题。
顺便说一句,Intel千兆驱动亦如此,其他的就更别说了,其根源在于通用的网卡驱动和协议栈设计并非针对转发优化的。
初始化:
创建RX ring:RXbuffinfo[MAX]
创建TX ring:TXbuffinfo[MAX]
RX过程:
i = 当前RX ring游历到的位置;
while(RXbuffinfo中有可用skb) {
skb = RXbufferinfo[i].skb;
RXbuffinfo[i].skb = NULL;
i++;
DMA_unmap(RXbufferinfo[i].DMA);
[Tips:至此,skb已经和驱动脱离,全然交给了Linux协议栈]
[Tips:至此,skb内存已经不再由RX ring维护,Linux协议栈拽走了skb这块内存]
OS_receive_skb(skb);
[Tips:由Linux协议栈负责释放skb。调用kfree_skb之类的接口]
if (RX ring中被Linux协议栈摘走的skb过多) {
alloc_new_skb_from_kmem_cache_to_RXring_RXbufferinfo_0_to_MAX_if_possible;
[Tips:从Linux核心内存中再次分配skb]
}
}
TX过程:
skb = 来自Linux协议栈dev_hard_xmit接口的数据包;
i = TX ring中可用的位置
TXbufferinfo[i].skb = skb;
DMA_map(TXbufferinfo[i].DMA);
while(TXbufferinfo中有可用的skb) {
DMA_transmit_skb(TXbufferinfo[i]);
}
[异步等待传输完毕中断或者在NAPI poll中主动调用]
i = 传输完毕的TXbufferinfo索引
while(TXbufferinfo中有已经传输完毕的skb) {
skb = TXbufferinfo[i];
DMA_unmap(TXbufferinfo[i].DMA);
kfree(skb);
i++;
}
以上的流程能够看出,在持续转发数据包的时候,会涉及大量的针对skb的alloc和free操作。假设你觉得上面的代码不是那么直观。那么下面给出一个图示: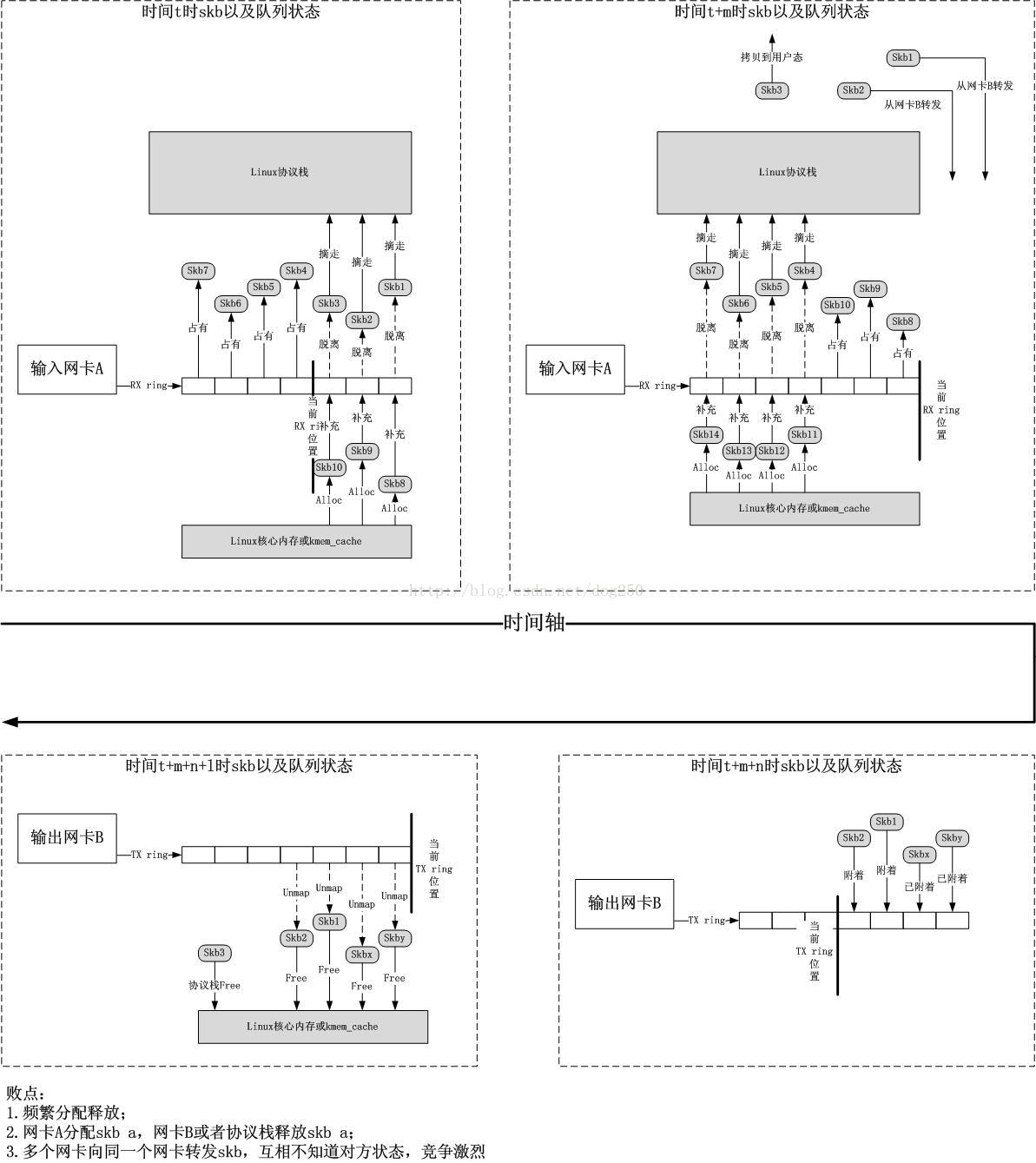
频繁的会发生从Linux核心内存中alloc skb和free skb的操作,这不仅仅是不必要的,并且还会损害CPU cache的利用。不要寄希望于keme_cache,我们能够看到。全部的网卡和socket差点儿是共享一块核心内存的,尽管能够通过dev和kmem cache来优化。但非常遗憾。这个优化没有质的飞跃。
1.2.构建新的DMA ring buffer管理设施-VOQ,建立输入/输出网卡之间队列的关联。
类比Linux O(1)调度器算法。每个cpu全局维护一个唯一的队列,散到各个网卡,靠交换队列的DMA映射指针而不是拷贝数据的方式优化性能,达到零拷贝,这仅仅是其一。
关于交换DMA映射指针而不是拷贝数据这一点不多谈,由于差点儿全部的支持DMA的网卡驱动都是这么做的。假设它们不是这么做的,那么肯定有人会将代码改成这么做的。
假设类比高端路由器的crossbar交换阵列结构以及真实的VOQ实现。你会发现,在逻辑上,每一对可能的输入/输出网卡之间维护一条数据转发通路是避免队头堵塞以及竞争的好方法。这样排队操作仅仅会影响单独的网卡。不须要再全局加锁。在软件实现上。我们相同能够做到这个。
你要明白。Linux的网卡驱动维护的队列信息被内核协议栈给割裂,从此,输入/输出网卡之间彼此失联。导致最优的二分图算法无法实施。
其实。你可能觉得把网卡作为一个集合,把须要输出的数据包最为还有一个集合,转发操作须要做的就是建立数据包和网卡之间的一条路径,这是一个典型的二分图匹配问题,然而假设把建立路径的操作与二分图问题分离,这就是不再是网卡和数据包之间的二分图匹配问题了。由于分离出来的路由模块导致了针对每个要转发的数据包。其输出网卡是唯一确定的。这个问题变成了处理输出网卡输出操作的CPU集合和输出网卡之间的二分图匹配问题。
这里有一个优化点,那就是假设你有多核CPU。那么就能够为每一块网卡的输出操作绑定一个唯一的CPU,二分图匹配问题迎刃而解,剩下的就是硬件总线的争用问题(对于高性能crossbar路由器而言,这也是一个二分图匹配问题,但对于总线结构的通用系统而言有点差别,后面我会谈到)了,作为我们而言,这一点除了使用性价比更高的总线。比方我们使用PCI-E 16Lines 8 bits,没有别的办法。作为一个全然的方案,我不能寄希望于底层存在一个多核CPU系统。假设仅仅有一个CPU,那么我们能寄希望于Linux进程调度系统吗?还是那个观点,作为一个通用操作系统内核,Linux不会针对网络转发做优化。于是乎,进程调度系统是此方案的还有一个优化点。这个我后面再谈。
最后,给出我的数据包队列管理VOQ的设计方案草图。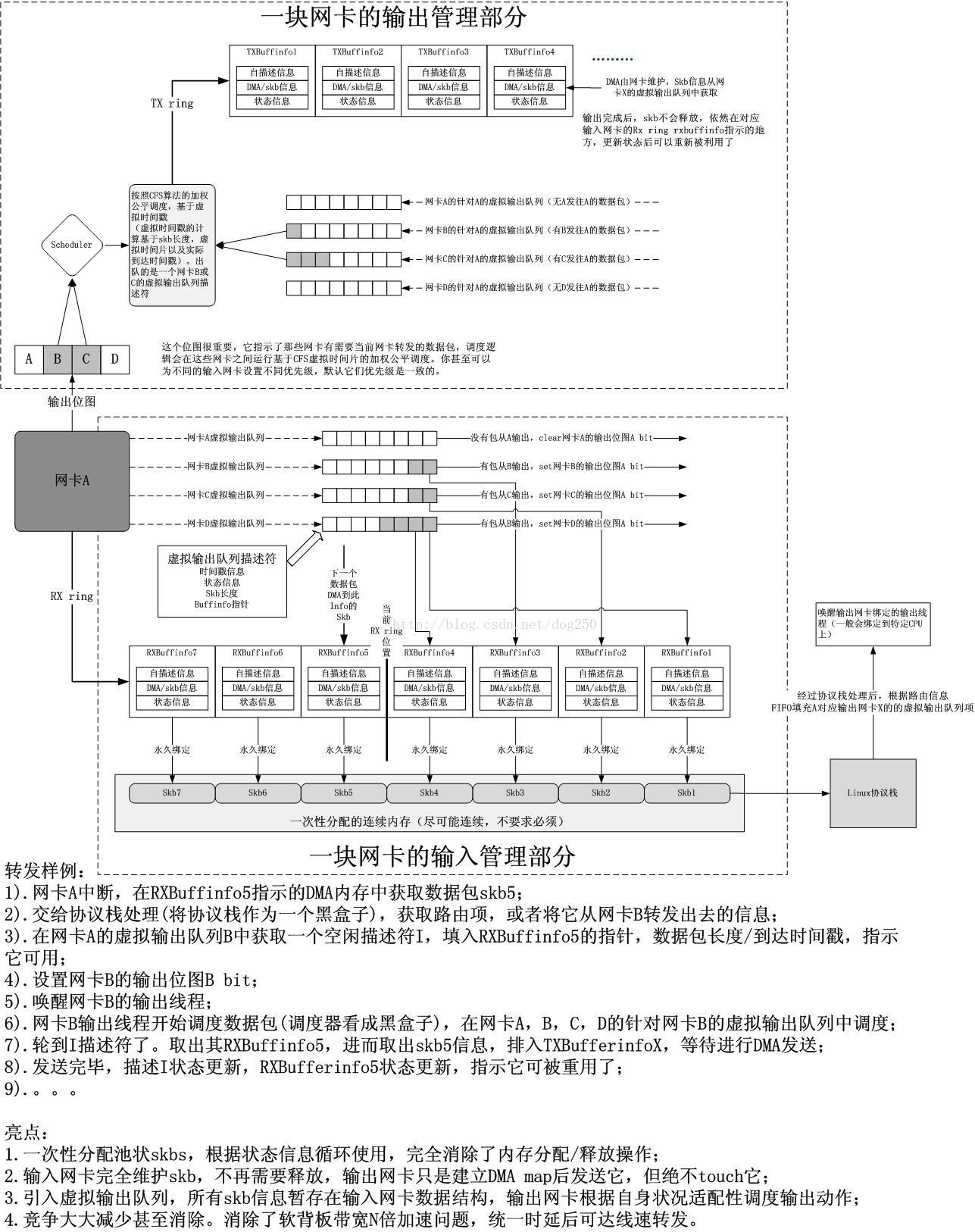
在我的这个针对Linux协议栈的VOQ设计中。VOQ总要要配合良好的输出调度算法,才干发挥出最佳的性能。
2.分离路由表和转发表以及建立查找操作之间的关联
Linux协议栈是不区分对待路由表和转发表的,而这在高端路由器上显然是必须的。诚然。我没有想将Linux协议栈打造成比肩专业路由器的协议栈。然而通过这个排名第二的核心优化,它的转发效率定会更上一层楼。
在大约三个月前,我參照DxR结构以及借鉴MMU思想设计了一个用于转发的索引结构,能够实现3步定位,无需做最长前缀匹配过程,详细能够參见我的这篇文章《以DxR算法思想为基准设计出的路由项定位结构图解》,我在此就不再深度引用了。须要注意的是,这个结构能够依据现行的Linux协议栈路由FIB生成。并且在路由项不规则的情况下能够在最差情况下动态回退到标准DxR,比方路由项不可汇聚,路由项在IPv4地址空间划分区间过多且分布不均。
我将我设计的这个结构称作DxR Pro++。
至于说查找操作之间的关联,这也是一个深度优化,底层构建高速查询流表实现协议栈短路(流表可參照conntrack设计)。这个优化思想直接參照了Netfilter的conntrack以及SDN流表的设计。尽管IP网络是一个无状态网络,中间路由器的转发策略也应该是一个无状态的转发。
然而这是形而上意义上的理念。
假设谈到深度优化,就不得不牺牲一点清纯性。
设计一个流表。流的定义能够不必严格依照五元组,而是能够依据协议头的随意字段,每个表项中保存的信息包含但不限于下面的元素:
*流表缓存路由项
*流表缓存neighbour
*流表缓存NAT
*流表缓存ACL规则
*流表缓存二层头信息
这样能够在协议栈的底层保存一张能够高速查询的流表,协议栈收到skb后匹配这张表的某项,一旦成功,能够直接取出相关的数据(比方路由项)直接转发。理论上仅仅有一个流的第一个数据包会走标准协议栈的慢速路径(其实,经过DxR Pro++的优化,一经不慢了...)。
在直接高速转发中。须要运行一个HOOK。运行标准的例行操作,比方校验和,TTL递减等。
关于以上的元素。特别要指出的是和neighbour与二层信息相关的。数据转发操作一向被觉得瓶颈在发不在收。在数据发送过程。会涉及到下面耗时的操作:>加入输出网卡的MAC地址作为源-内存拷贝>加入next hop的MAC地址作为目标-内存拷贝又一次,我们遇到了内存操作,恼人的内存操作。假设我们把这些MAC地址保存在流表中,能够避免吗?貌似仅仅是能够高速定位,而无法避免内存拷贝...再一次的,我们须要硬件的特性来帮忙,这就是分散聚集I/O(Scatter-gather IO)。原则上,Scatter-gather IO能够将不连续的内存当成连续的内存使用,进而直接映射DMA,因此我们仅仅须要告诉控制器,一个将要发送的帧的MAC头的位置在哪里,DMA就能够直接传输,没有必要将MAC地址复制到帧头的内存区域。
例如以下图所看到的:
特别要注意,上述的流表缓存项中的数据存在大量冗余,由于next hop的MAC地址,输出网卡的MAC地址,这些是能够由路由项唯一确定的。之所以保存冗余数据,其原则还是为了优化,而标准的通用Linux内核协议栈,它却是要避免冗余的...既然保存了冗余数据。那么慢速路径的数据项和高速路经的数据项之间的同步就是一个必须要解决的问题。

我基于读写的不正确称性,着手採用event的方式通知更新。比方慢速路径中的数据项(路由,MAC信息。NAT,ACL信息等)。一旦这些信息更改,内核会专门触发一个查询操作,将高速流表中与之相关的表项disable掉就可以。
值得注意的是。这个查询操作不是必需太快。由于相比較高速转发而言,数据同步的频率要慢天文数字个数量级...相似Cisco的设备,能够创建几个内核线程定期刷新慢速路径表项,用来发现数据项的更改。从而触发event。
[Tips:能够高速查找的流表结构可用多级hash(採用TCAM的相似方案)。也能够借鉴我的DxR Pro++结构以及nf-HiPac算法的多维区间匹配结构。我个人比較推崇nf-HiPac]
3.路由Cache优化
虽说Linux的路由cache早已下课,可是它下课的原因并非cache机制本身不好,而是Linux的路由cache设计得不好。因此下面几点能够作为优化点来尝试。
*)限制路由软cache的大小。保证查找速度[实施精心设计的老化算法和替换算法]
[利用互联网訪问的时间局部性以及空间局部性(须要利用计数统计)]
[自我PK:假设有了我的那个3步定位结构。难道还用的到路由cache吗]
*)预制经常使用IP地址到路由cache,实现一步定位
[所谓经常使用IP须要依据计数统计更新,也能够静态设置]
4.Softirq在不支持RSS多队列网卡时的NAPI调度优化
*)将设备依照协议头hash值均匀放在不同CPU,远程唤醒softirq,模拟RSS软实现眼下的网络接收软中断的处理机制是。哪个CPU被网卡中断了。哪个CPU就处理网卡接收软中断。在网卡仅仅能中断固定CPU的情况下,这会影响并行性。比方仅仅有两块网卡,却有16核CPU。怎样将尽可能多的CPU核心调动起来呢?这须要改动网络接收软中断处理逻辑。我希望多个CPU轮流处理数据包。而不是固定被中断的数据包来处理。改动逻辑例如以下:
1.全部的rx softirq内核线程组成一个数组
struct task_struct rx_irq_handler[NR_CPUS];
2.全部的poll list组成一个数组
struct list_head polll[NR_CPUS];
3.引入一把保护上述数据的自旋锁
spinlock_t rx_handler_lock;
4.改动NAPI的调度逻辑
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
static int curr = 0;
unsigned int hash = curr++%NR_CPUS;
local_irq_save(flags);
spin_lock(&rx_handler_lock);
list_add_tail(&n->poll_list, polll[hash]);
local_softirq_pending(hash) |= NET_RX_SOFTIRQ;
spin_unlock(&rx_handler_lock);
local_irq_restore(flags);
}[Tips:注意和DMA/DCA。CPU cache亲和的结合。假设连DMA都不支持。那他妈的还优化个毛]
理论上一定要做基于传输层以及传输层下面的元组做hash,不能随机分派,在计算hash的时候也不能引入不论什么每包可变的字段。由于某些高层协议比方TCP以及绝大多数的基于非TCP的应用协议是高度按序的,中间节点的全然基于数据包处理的并行化会引起数据包在端节点的乱序到达。从而引发重组和重传开销。
自己为了提高线速能力貌似爽了一把,却给端主机带来了麻烦。然而我眼下没有考虑这个,我仅仅是基于轮转调度的方式来分发poll过程到不同的CPU来处理,这显然会导致上述的乱序问题。
若想完美解决上述问题。须要添加一个调度层,将RX softirq再次分为上下两半部RX softirq1和RX softirq2,上半部RX softirq1仅仅是不断取出skb并分派到特定CPU核心,下半部才是协议栈处理。改动NAPI的poll逻辑。每当poll出来一个skb,就计算这个skb的hash值。然后将其再次分派到特定的CPU的队列中。最后唤醒有skb须要处理的CPU上的RX softirq2,这期间须要引入一个位图来记录有无情况。
可是有一个须要权衡的逻辑,是不是真的值得将RX softirq做再次切割。将其分为上下半部。这期间的调度开销和切换开销究竟是多少。须要基准測试来评估。
*)延长net softirq的运行时间,有包就一直dispatch loop。管理/控制平面进程被划分到独立的cgroup/cpuset中。
5.Linux调度器相关的改动
这个优化涉及到方案的完备性,毕竟我们不能保证CPU核心的数量一定大于网卡数量的2倍(输入处理和输出处理分离),那么就必须考虑输出事件的调度问题。
依照数据包队列管理的设计方案,考虑单CPU核心,假设有多块网卡的输出位图中有bit被置位,那么究竟调度哪一个网卡进行输出呢?这是一个明白的task调度问题。你放心把这个工作交给Linux内核的调度器去做吗?我不会。
由于我知道,尽管有好几个网卡可能都有数据包等待发送,可是它们的任务量并不同,这又是一个二分图问题。
我须要三个指标加权来权衡让哪个网卡先发送。这三个指标是。队头等待时间,队列数据包长度总和以及数据包数量。由此能够算出一个优先级prio。总的来讲就是虚拟输出队列中等待越久。数据包越多,长度越长的那个网卡最值得发送数据。计算队列总长势必会引发非局部訪问。比方訪问其他网卡的虚拟输出队列,这就会引发锁的问题,因此考虑简单情形。仅仅使用一个指标,即数据包长度。
在Linux当前的CFS调度器情形下,须要将排队虚拟输出队列的数据包长度与task的虚拟时间,即vruntime关联,详细来讲就是。在输入网卡对输出网卡的输出位图置位的时候,有下列序列:
//仅仅要有skb排队,无条件setbit setbit(outcart, incard); //仅仅要有skb排队。则将与输出网卡关联的输出线程的虚拟时间减去一个值,该值由数据包长度与常量归一化计算所得。outcard_tx_task_dec_vruntime(outcard, skb->len);
对Linux CFS调度不熟悉的,能够自行google。
其实,一旦某个输出网卡的输出task開始运行,它也是依照这样的基于虚拟时间流逝的CFS方式来调度数据包的,即摘下一个最值得发送的数据包队列描写叙述符放入TX ring。
最后有一个思考,假设不採用CFS而採用RT调度类是不是更好?单独网卡输出的实时性和多块网卡输出之间的公平性怎样权衡?另外。採用RT调度类就一定带有实时性吗?
6.内置包分类和包过滤的情况
这是一个关于Netfilter优化的话题。Netfilter的性能一直被人诟病,其非常大程度上都是由于iptables造成的,一定要区分对待Netfilter和iptables。当然排除了这个误会,并不表明Netfilter就全然无罪。Netfilter是一个框架。它本身在我们已经关闭了抢占的情况下是没有锁开销的。关键的在它内部的HOOK遍历运行中。作为一些callback。内部的逻辑是不受控制的,像iptables。conntrack(本来数据结构粒度就非常粗-同一张hash存储两个方向的元组。又使用大量的大粒度锁,内存不紧张时我们能够多用几把锁,空间换自由。再说,一把锁能占多大空间啊)。都是吃性能的大户,而nf-HiPac就好非常多。因此这部分的优化不好说。
只是建议还是有的,为一段临界区加锁的时候千万不要盲目,假设一个数据结构被读的频率比被写的频率高非常多,以至于后者能够被忽略的地步。那么劝各位不要锁定它,即使RW锁,RCU锁都不要,而是採用复制的形式,拷贝出一个副本,然后读副本。写原本,写入原本后採用原子事件的方式通知副本失效。比方上面提到的关于高速流表的同步问题,一旦路由发生变化,就触发一个原子事件。查询高速流表中与之相关的项,失效掉它。
查询能够非常慢,由于路由更新的频率非常低。
本节不多谈。建议例如以下:
*)预处理ACL或者NAT的ruleset(採用nf-hipac方案替换非预处理的逐条匹配)
[Hipac算法相似于一种针对规则的预处理,将matches进行了拆分。採用多维区间匹配算法]
*)包调度算法(CFS队列,RB树存储包到达时间*h(x)。h为包长的函数)
7.作为容器的skb
skb作为一个数据包的容器存在。它要和真正的数据包区分开来。其实,它仅仅作为一个数据包的载体。像一辆卡车运载数据包。它是不应该被释放的。永远不该被释放。每一块网卡都应该拥有自己的卡车车队。假设我们把网卡看作是航空港,Linux路由器看作是陆地。那么卡车从空港装载货物(数据包),要么把它运输到某个目的地(Linux作为server),要么把它运输到还有一个空港(Linux作为转发路由器),其间这辆卡车运送个来回就可以,这辆卡车一直属于货物到达的那个空港,将货物运到还有一个空港后空车返回就可以。卡车的使用不必中心调度,更无需用完后销毁。用的时候再造一辆(Linux的转发瓶颈即在此!!!
)。
其实还有更加高效的做法,那就是卡车将货物运输到还有一个港口或者运输到陆地目的地后。不必空车返回,而是直接排入目的港口或者目的地的出港队列,等待运输货物满载返回所属的港口。
可是对于Linux而言,由于须要路由查找后才知道卡车返回哪里,因此在出发的时候。卡车并不能确定它一定会返回它所属的港口...因此须要对包管理队列做一定的修正,即解除网卡的RX ring和skb的永久绑定关系。为了统一起见,新的设计将路由到本机的数据包也作为转发处理。仅仅是输出网卡变成了一个BSD socket,新的设计例如以下图所看到的: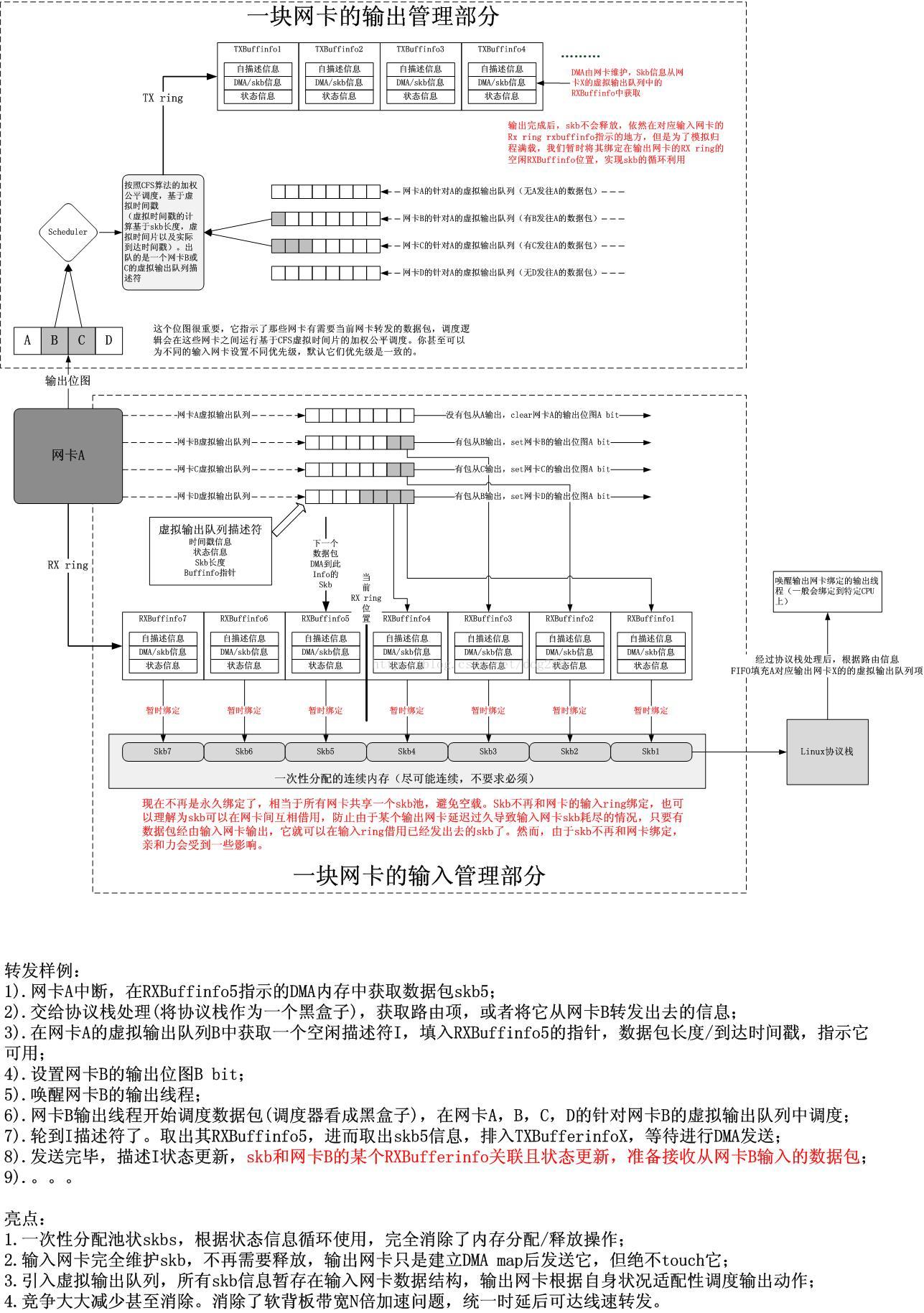
其实。类比火车和出租车我们就能看到这个差别。对于火车而言,它的线路是固定的。比方哈尔滨到汉口的火车,它属于哈尔滨铁路局。满客到达汉口后。下客。然后汉口空车又一次上客。它一定返回哈尔滨。
然而对于出租车,就不是这样。嘉定的沪C牌的出租车理论上属于嘉定。不拒载情况下。一个人打车到松江,司机到松江后。尽管期待有人打他的车回嘉定,可是乘客上车后(路由查找),告诉司机。他要到闵行。到达后。又一人上车,说要到嘉兴...越走越远,但事实就是这样,由于乘客上车前。司机是不能确定他要去哪里的。
用户态协议栈方案
1.争议
在某些平台上,假设不解决user/kernel切换时的cache,tlb刷新开销,这样的方案并非我主推的,这些平台上无论是写直通还是写回,訪问cache都是不经MMU的。也不cache mmu权限,且cache直接使用虚地址。2.争议解决方式
能够採用Intel I/OAT的DCA技术。避免上下文切换导致的cache抖动3.採用PF_RING的方式
改动驱动,直接与DMA buffer ring关联(參见内核方案的DMA优化)。4.借鉴Tilera的RISC超多核心方案
并行流水线处理每一层,流水级数为同一时候处理的包的数量,CPU核心数+2,流水数量为处理模块的数量。[流水线倒立]
本质上来讲,用户态协议栈和内核协议栈的方案是雷同的,无外乎还是那几种思想。用户态协议栈实现起来限制更少,更灵活。同一时候也更稳定,可是并非一味的都是优点。须要注意的是。大量存在的争议都是形而上的,仁者见仁,智者见智。
稳定性
对于非专业非大型路由器。稳定性问题能够不考虑。由于无需7*24。故障了大不了重新启动一下而已,无伤大雅。可是就技术而言。还是有几点要说的。在高速总线情形下。并行总线easy窜扰。内存也easy故障,一个位的错误。一个电平的不稳定都会引发不可预知的后果,所以PCI-E这样的高速总线都採用串行的方式数据传输,对于硬盘而言,SATA也是一样的道理。
在多网卡DMA情况下,对于通过的基于PCI-E的设备而言,总线上的群殴是非常激烈的。这是总线这样的拓扑结构所决定的。和总线类型无关,再考虑到系统总线和多CPU核心,这样的群殴会更加激烈。由于CPU们也会參与进来。群殴的时候。打翻桌椅而不是扳倒对方是非经常有的事,仅仅要考虑一下这样的情况。我就想为三年前我与客户的一次争吵而向他道歉。
2012年。我做一个VPN项目,客户说我的设备可能下一秒就会宕机,由于不确定性。我说if(true) {printf("cao ni ma!\n")(当然当时我不敢这么说);确定会运行吗?他说不一定。我就上火了...可是如今看来。他是对的。
VOQ设计后良好的副作用-QoS
VOQ是本方案的一个亮点,本文差点儿是环绕VOQ展开的,关于还有一个亮点DxR Pro,在其他的文章中已经有所阐述,本文仅仅是加以引用而已。临近末了。我再次提到了VOQ,这次是从一个宏观的角度,而不是细节的角度来加以说明。
仅仅要输入缓冲区队列足够大。数据包接收差点儿就是线速的。然而对于输出,却受到了调度算法,队头拥塞等问题的影响。即输入对于系统来讲是被动的,中断触发的,而输出对于系统来讲则是主动的。受制于系统的设计。因此对于转发而言“收易发难”就是一个真理。
因此对于QoS的位置,大多数系统都选择在了输出队列上,由于输入队列上即便对流量进行了干预,流量在输出的时候还是会受到二次无辜的干预,而这会影响输入队列上的QoS干预效果。
我记得以前研究过Linux上的IMQ输入队列流控。当时仅仅是关注了实现细节,并没有进行形而上的思考,如今不了。
有了VOQ以后,配合设计良好的调度算法,差点儿攻克了全部问题,这是令人兴奋的。上文中我提到输出操作的时候。输出线程採用基于数据包长度以及虚拟时间的加权公平调度算法进行输出调度,可是这个算法的效果仅仅是全速发送数据包。
假设这个调度算法策略化。做成一个可插拔的,或者说把Linux的TC模块中的框架和算法移植进来,是不是会更好呢?
唉,假设你百度“路由器 线速”,它搜出来的差点儿都是“路由器 限速”,这真是一个玩笑。其实对于转发而言。你根本不用加入不论什么TC规则就能达到限速的效果,Linux盒子在网上上一串,立即就被自己主动限速了,难道不是这样吗?而加上VOQ以后,你确实须要限速了。
就像在拥挤的中国城市中区,主干道上写着限速60,这不是开玩笑吗?哪个市中心的熙熙攘攘的街道能跑到60....可是一旦上了高速,限速100/120,就是必须的了。
VOQ设计后良好的副作用-队头拥塞以及加速比问题
用硬件路由器的术语,假设採用将数据包路由后排队到输出网卡队列的方案,那么就会有多块网卡同一时候往一块网卡排队数据包的情况,这对于输出网卡而言是被动的。这又是一个令人悲伤的群殴过程。为了让多个包都能同一时候到达。输出带宽一定要是各个输入带宽的加和。这就是N倍加速问题,我们希望的是一个输出网卡主动对数据包进行调度的过程。有序必定高效。这就是VOQ设计的精髓。
对于Linux而言,由于它的输出队列是软件的。因此N加速比问题变成了队列锁定问题,总之,还是一个令人遗憾的群殴过程。因此应对方案的思想是一致的。因此在Linux中我就模拟了一个VOQ。从这里我们能够看出VOQ和输出排队的差别,VOQ对于输出过程而言是主动调度的过程,显然更加高效,而输出排队对于输出过程而言则是一个被动被争抢的过程,显然这是令人感到无望的。
须要说明的是。VOQ仅仅是一个逻辑上的概念,类比了硬件路由器的概念。假设依旧坚持使用输出排队而不是VOQ。那么设计多个输出队列,每个网卡一个队列也是合理的,它甚至更加简化,压缩掉了一个网卡分派过程。简化了调度。于是我们得到了Linux VOQ设计的第三版:将虚拟输出队列VOQ关联到输出网卡而不是输入网卡(下面一小节我将分析原因)。
总线拓扑和Crossbar
真正的硬件路由器,比方Cisco。华为的设备,路由转发全由线卡硬件运行。数据包在此期间是精巧在那里的,查询转发表的速度是如此之快。以至于相对将数据包挪到输出网卡队列的开销。查表开销能够忽略。因此在真正的硬件路由器上,怎样构建一个高性能交换网络就是重中之重。
不但如此,硬件路由器还须要考虑的是,数据包在路由查询过后是由输入处理逻辑直接通过交换网络PUSH到输出网卡队列呢。还是原地不动。然后等待输出逻辑通过交换网络把数据包PULL到那里。这个不同会影响到交换网络仲裁器的设计。假设有多个网卡同一时候往一个网卡输出数据包。PUSH方式可能会产生冲突,由于在Crossbar的一条路径上,它相当于一条总线,并且冲突通常会发生在交换网络内部,因此这样的PUSH的情况下,通常会在交换网络内部的开关节点上携带cache,用来暂存冲突仲裁失败的数据包。反之,假设是PULL方式,情况就有所不同。
因此把输出队列放在交换网络的哪一側带来的效果是不同的。
可是对于通用系统架构。一般都是採用PCI-E总线连接各个网卡,这是一种典型的总线结构,根本就没有所谓的交换网络。
因此所谓的仲裁就是总线仲裁,这并非我关注的重点,谁让我手上仅仅有一个通用架构的设备呢?!
我的优化不包含总线仲裁器的设计,由于我不懂这个。
因此,对于通用架构总线拓扑的Linux协议栈转发优化而言,虚拟输出队列VOQ关联在输入网卡还是输出网卡,影响不会太大。可是考虑到连续内存訪问带来的局部性优化,我还是倾向将VOQ关联到输出网卡。假设VOQ关联到输入网卡,那么在进行输出调度的时候,输出网卡的输出线程就要从输出位图指示的每个待发送数据的输入网卡VOQ中与自己关联的队列调度数据包,无疑。这些队列在内存中是不连续的。假设关联到输出网卡,对于每个输出网卡而言,VOQ是连续的。例如以下图所看到的:

实现相关
前面我们提到skb仅仅是作为容器(卡车)存在。因此skb是不必释放的。理想情况下,在Linux内核启动,网络协议栈初始化的时候,依据自身的硬件性能和网卡參数做一次自測,然后分配MAX个skb,这些skb能够先均匀分配到各个网卡,同一时候预留一个socket skb池。供用户socket取。后面的事情就是skb运输行为了,卡车开到哪里算哪里。运输过程不空载。
可能你会觉得这个没有必要。由于skb本身甚至整个Linux内核中绝大部分内存分配都是被预先分配并cache的,slab就是做这个的,不是有kmem_cache机制吗?是这样的,我承认Linux内核在这方面做得非常不错。可是kmem_cache是一个通用的框架,为何不针对skb再提高一个层次呢?每一次调用alloc_skb,都会触发到kmem_cache框架内的管理机制做非常多工作,更新数据结构,维护链表等,甚至可能会触及到更加底层的伙伴系统。因此,期待直接使用高效的kmem_cache并非一个好的主意。
你可能会反驳说万一系统内存吃紧也不释放吗?万事并不绝对。但这并非本文的范畴。这涉及到非常多方面。比方cgroup等。
针对skb的改动,我加入了一个字段。指示它的所属地(某个网卡?socket池?...)。当前所属地。这些信息能够维护skb不会被free到kmem_cache,同一时候也能够最优化cache利用率。
这部分改动已经实现。眼下正在针对Intel千兆卡的驱动做进一步改动。
关于DxR Pro的性能,我在用户态已经经过測试,眼下还没有移植到内核。
关于高速查找表的实现,眼下的思路是优化nf_conntrack。做多级hash查找。
最后的声明
本文仅仅是针对Linux做的转发调优方案,假设须要更加优化的方案, 请參考ASIC以及NP等硬件方案,不要使用总线拓扑。而是使用交叉阵列拓扑。以上是关于Linux转发性能评估与优化-转发瓶颈分析与解决方式(补遗)的主要内容,如果未能解决你的问题,请参考以下文章