新功能:阿里云反爬虫管理利器!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新功能:阿里云反爬虫管理利器!相关的知识,希望对你有一定的参考价值。
参考技术A
背景
爬虫形势
Web安全形势一直不容乐观, 根据 Globaldots的2018年机器人报告 , 爬虫占据Web流量的42%左右.
为什么要反爬
防资源过度消耗
大量的机器人访问网站, 设想你的网站有42%的流量都不是真的人访问的. 相当一部分还会大量占用后台的网络带宽, 服务器计算, 存储资源.
防黄牛党
航空公司占座: 黄牛党利用恶意爬虫遍历航空公司的低价票,同时批量发起机器请求进行占座,导致航班座位资源被持续占用产生浪费,最终引发航班空座率高对航空公司造成业务损失,并且损害正常用户的利益。
防薅羊毛党
黄牛党在电商活动时针对有限的高价值商品的限时秒杀、优惠活动等可牟利场景,批量发起机器请求来模拟正常的交易,再将商品、资源进行倒卖从中赚取差价,导致电商企业的营销资源无法触达正常用户,而被黄牛牟取暴利。
防黑客
核心接口被刷: 登录、注册、短信等业务环节作为业务中的关键节点,相关接口往往会被黑客利用,为后续的欺诈行为作准备。
私信菜鸟007即可获取数十套PDF!
为什么需要日志分析
找出隐藏更深的机器人
爬虫与反爬虫是一个攻与防的过程, 根据前述报告, 高级机器人占据了74%的比例(剩余是比较简单的机器人), 而根据 FileEye M-Trends 2018报告 ,企业组织的攻击从发生到被发现,一般经过了多达101天,其中亚太地区问题更为严重,一般网络攻击被发现是在近498(超过16个月)之后。有了日志才能更好的找出隐藏很深的坏机器人.
了解机器人并区分对待
爬虫也分好与坏, 搜索引擎来查询, 才可以达到SEO效果并带来更多有价值的访问. 通过日志可以帮助管理员更好的区分哪些是好的机器人, 并依据做出更加适合自己的反爬配置.
保留报案证据
发现非法攻击的机器人, 可以保留攻击者信息与路径, 作为报警的重要证据.
增强运维效率
基于日志可以发现异常, 并能快速报警并采取行动.
更多附加功能
依托日志服务的其他功能, 可以发挥日志的更大价值.
阿里云反爬管理 - 实时日志分析概述
阿里云反爬管理
云盾Anti-Bot Service是一款网络应用安全防护产品,专业检测高级爬虫,降低爬虫、自动化工具对网站的业务影响。 产品提供从Web、App到API接口的一整套全面的恶意Bot防护解决方案,避免某一环节防护薄弱导致的安全短板。
阿里云日志服务
阿里云的日志服务(log service)是针对日志类数据的一站式服务,无需开发就能快捷完成海量日志数据的采集、消费、投递以及查询分析等功能,提升运维、运营效率。日志服务主要包括 实时采集与消费、数据投递、查询与实时分析 等功能,适用于从实时监控到数据仓库的各种开发、运维、运营与安全场景:
目前,阿里云WAF与日志服务打通,对外开发Web访问与攻击日志。提供近实时的网站具体的日志自动采集存储、并提供基于日志服务的查询分析、报表报警、下游计算对接与投递的能力。
发布地域
适用客户
功能优势
反爬日志实时查询分析服务具有以下功能优势:
开通前提
限制说明
反爬管理所存储的日志库属于专属的日志库,有如下限制:
使用场景
1.追踪机器人爬取与封禁日志,溯源安全威胁:
查看Top 100的爬取机器人列表:
2. 实时正常可信Web请求活动,洞察状态与趋势:
查看PV/UV访问趋势的SQL:
3. 快速了解安全运营效率,即时反馈处理:
查看有效请求与拦截率趋势的SQL:
4. 输出安全网络日志到自建数据与计算中心
进一步参考
我们会陆续发布WAF安全日志分析的最佳时间, 这里可以进一步参考相关用户手册:
Python爬虫利器:BeautifulSoup库
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you.
BeautifulSoup库是解析、遍历、维护 “标签树” 的功能库(遍历,是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问)。https://www.crummy.com/software/BeautifulSoup
BeautifulSoup库我们常称之为bs4,导入该库为:from bs4 import BeautifulSoup。其中,import BeautifulSoup即主要用bs4中的BeautifulSoup类。
bs4库解析器
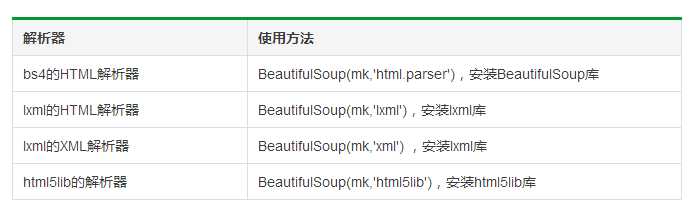
BeautifulSoup类的基本元素
1 import requests 2 from bs4 import BeautifulSoup 3 4 res = requests.get(‘http://www.pmcaff.com/site/selection‘) 5 soup = BeautifulSoup(res.text,‘lxml‘) 6 print(soup.a) 7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。 8 9 print(soup.a.name) 10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型 11 12 print(soup.a.attrs) 13 print(soup.a.attrs[‘class‘]) 14 # 一个<tag>可能有一个或多个属性,是字典类型 15 16 print(soup.a.string) 17 # <tag>.string可以取到标签内非属性字符串 18 19 soup1 = BeautifulSoup(‘<p><!--这里是注释--></p>‘,‘lxml‘) 20 print(soup1.p.string) 21 print(type(soup1.p.string)) 22 # comment是一种特殊类型,也可以通过<tag>.string取到
运行结果:
<a class="no-login" href="">登录</a>
a
{‘href‘: ‘‘, ‘class‘: [‘no-login‘]} [‘no-login‘]
登录
这里是注释
<class ‘bs4.element.Comment‘>
bs4库的HTML内容遍历
HTML的基本结构
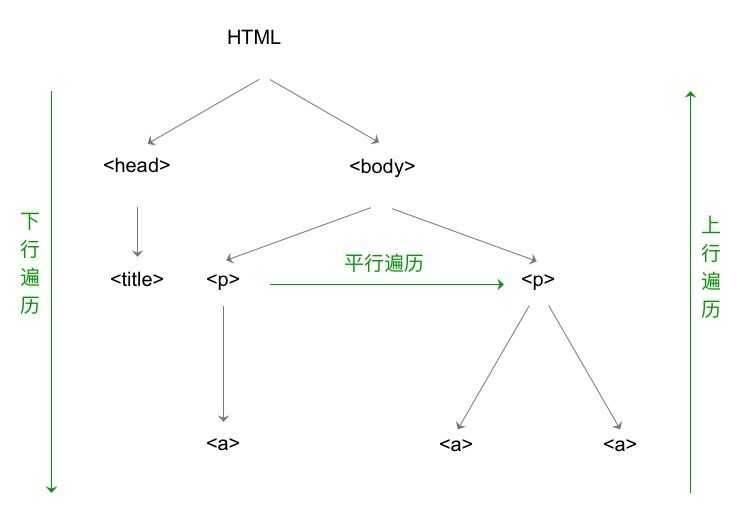
标签树的下行遍历
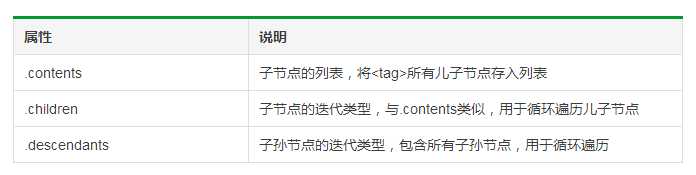
其中,BeautifulSoup类型是标签树的根节点。
1 # 遍历儿子节点 2 for child in soup.body.children: 3 print(child.name) 4 5 # 遍历子孙节点 6 for child in soup.body.descendants: 7 print(child.name)
标签树的上行遍历

1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断 2 for parent in soup.a.parents: 3 if parent is None: 4 print(parent) 5 else: 6 print(parent.name)
运行结果:
div
div
body
html
[document]
标签树的平行遍历
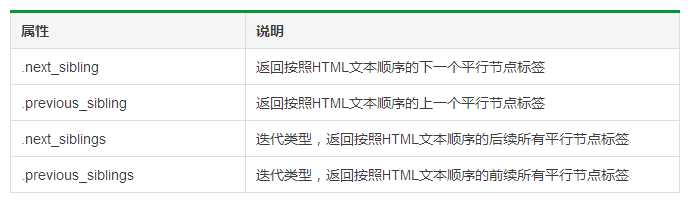
1 # 遍历后续节点 2 for sibling in soup.a.next_sibling: 3 print(sibling) 4 5 # 遍历前续节点 6 for sibling in soup.a.previous_sibling: 7 print(sibling)
bs4库的prettify()方法
prettify()方法可以将代码格式搞的标准一些,用soup.prettify()表示。在PyCharm中,用print(soup.prettify())来输出。
操作环境:Mac,Python 3.6,PyCharm 2016.2
参考资料:中国大学MOOC课程《Python网络爬虫与信息提取》
----- End -----
更多精彩内容关注我公众号:杜王丹
作者:杜王丹,互联网产品经理

以上是关于新功能:阿里云反爬虫管理利器!的主要内容,如果未能解决你的问题,请参考以下文章