逆分布函数法生成随机数(指数分布) R语言实现
Posted 张乐乐章
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逆分布函数法生成随机数(指数分布) R语言实现相关的知识,希望对你有一定的参考价值。
先说明一下符号:U(0,1)-均匀分布,”~“表示服从xxx分布,F(x),为需要生成的随机数的分布函数,invF(x)表示逆分布函数,那么算法步骤如下:
step 1: 产生 u~U(0,1)
step 2:计算X=invF(u)
那么X就是服从分布函数为F(x)的随机数,一个简单的证明:
证明: P(X<y)=P(invF(u)<y)=P(u<F(y))=F(y); 证毕。
你会感觉好简单啊,对是很简,下面就给出常用的指数分布
首先,指数分布的分布函数:
F(x)=1-exp(-lamda*x);x>0( lamda 为参数)
因此逆分布函数:
invF(x)=-(1/lamda)*ln(1-x);0<x<1
所以随机数数产生过程:
step 1:产生u~U(0,1)
step 2: 计算X=-ln(1-u)
得到随机数
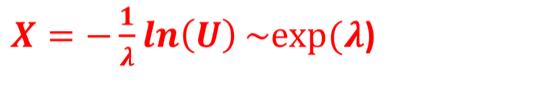
x <- runif(100) lamda <- 0.1 U <- runif(100) lamda <- 0.1 X <- -1/lamda * log(U) hist(X,prob=T,col=gray(0.9), main="exp from uniform") curve(dexp(x,lamda),add=T,col="red")
以上是关于逆分布函数法生成随机数(指数分布) R语言实现的主要内容,如果未能解决你的问题,请参考以下文章