带你认识spark安装包的目录结构
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你认识spark安装包的目录结构相关的知识,希望对你有一定的参考价值。
福利 => 每天都推送
其实啊,将spark的压缩包解压好,就已经是spark的最简易安装了。
其实啊,想说的是,只要将spark这压缩包解压好,就已经是spark的最简易安装了。
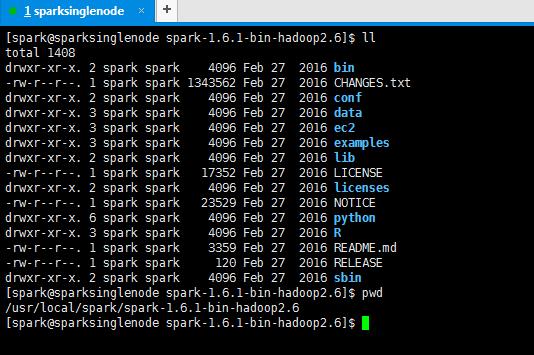
[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$ ll
total 1408
drwxr-xr-x. 2 spark spark 4096 Feb 27 2016 bin (可执行)
-rw-r--r--. 1 spark spark 1343562 Feb 27 2016 CHANGES.txt
drwxr-xr-x. 2 spark spark 4096 Feb 27 2016 conf (配置文件)
drwxr-xr-x. 3 spark spark 4096 Feb 27 2016 data (例子里用到的一些数据)
drwxr-xr-x. 3 spark spark 4096 Feb 27 2016 ec2
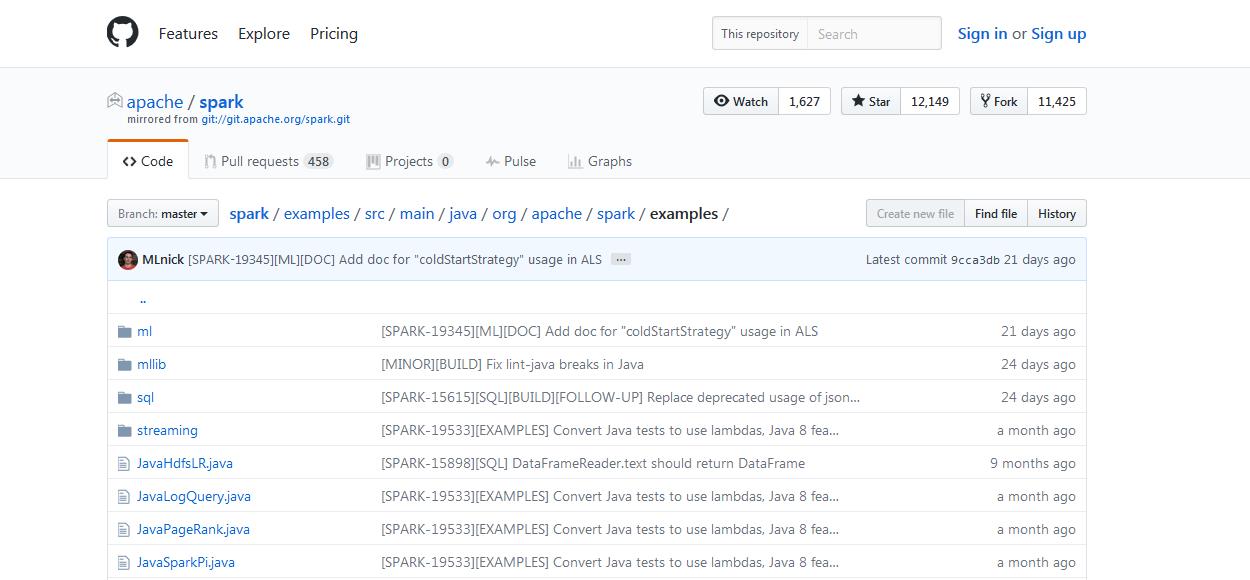
drwxr-xr-x. 3 spark spark 4096 Feb 27 2016 examples (自带的例子一些源代码)
drwxr-xr-x. 2 spark spark 4096 Feb 27 2016 lib (jar包)
-rw-r--r--. 1 spark spark 17352 Feb 27 2016 LICENSE
drwxr-xr-x. 2 spark spark 4096 Feb 27 2016 licenses
-rw-r--r--. 1 spark spark 23529 Feb 27 2016 NOTICE
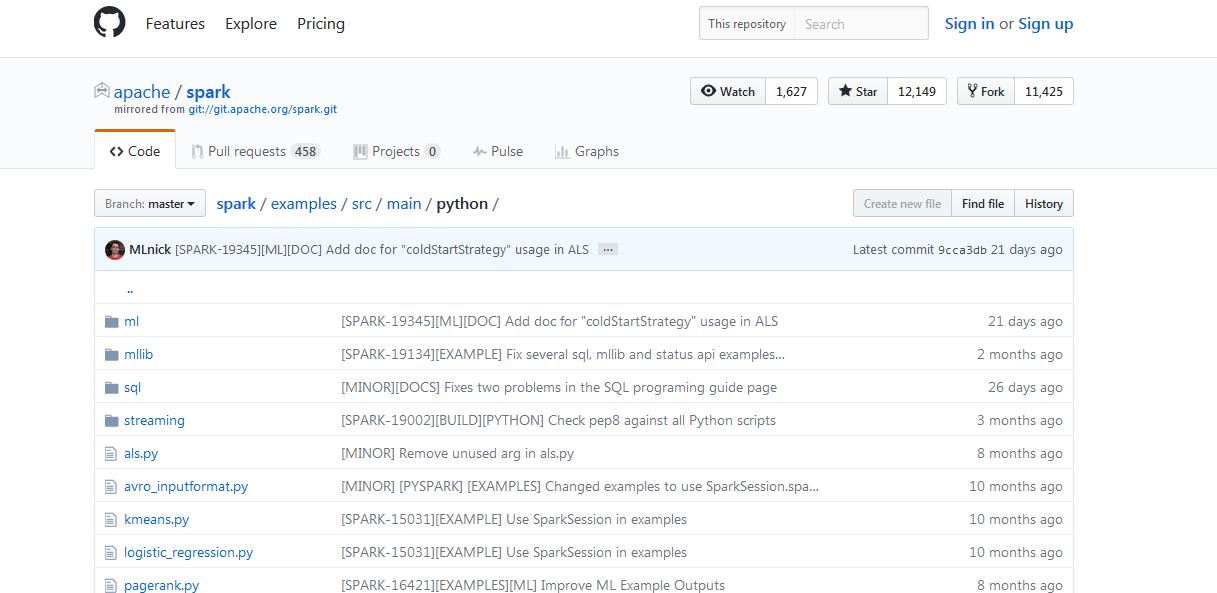
drwxr-xr-x. 6 spark spark 4096 Feb 27 2016 python
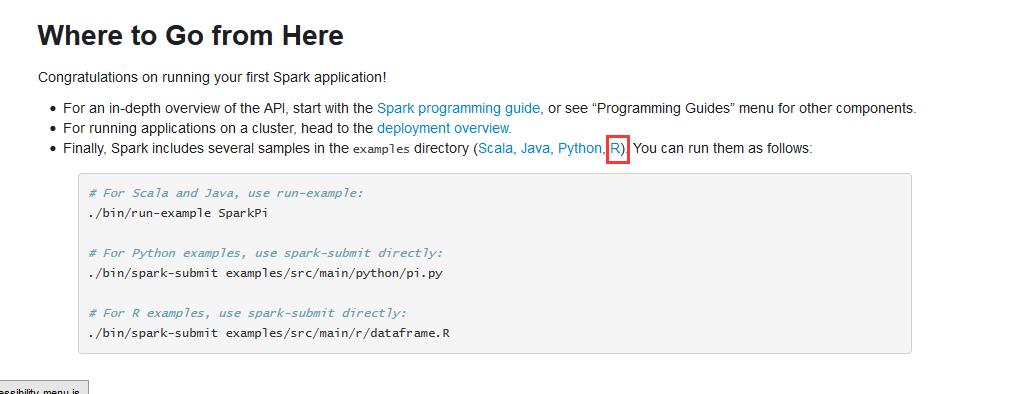
drwxr-xr-x. 3 spark spark 4096 Feb 27 2016 R
-rw-r--r--. 1 spark spark 3359 Feb 27 2016 README.md (包含一些入门的spark说明)
-rw-r--r--. 1 spark spark 120 Feb 27 2016 RELEASE
drwxr-xr-x. 2 spark spark 4096 Feb 27 2016 sbin (集群启停,因为spark有自带的集群环境)
[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$ pwd
/usr/local/spark/spark-1.6.1-bin-hadoop2.6
[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$
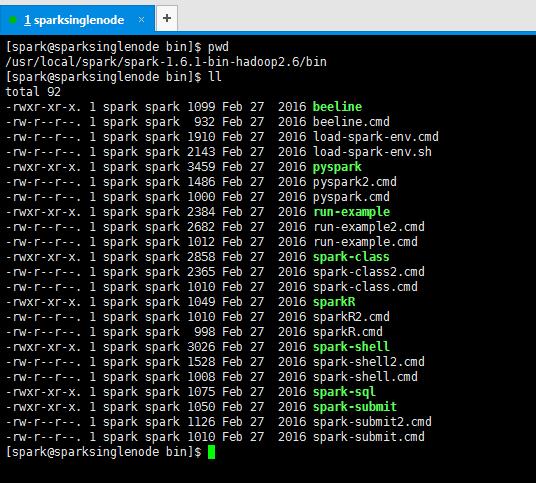
[spark@sparksinglenode bin]$ pwd /usr/local/spark/spark-1.6.1-bin-hadoop2.6/bin [spark@sparksinglenode bin]$ ll total 92 -rwxr-xr-x. 1 spark spark 1099 Feb 27 2016 beeline -rw-r--r--. 1 spark spark 932 Feb 27 2016 beeline.cmd -rw-r--r--. 1 spark spark 1910 Feb 27 2016 load-spark-env.cmd -rw-r--r--. 1 spark spark 2143 Feb 27 2016 load-spark-env.sh -rwxr-xr-x. 1 spark spark 3459 Feb 27 2016 pyspark -rw-r--r--. 1 spark spark 1486 Feb 27 2016 pyspark2.cmd -rw-r--r--. 1 spark spark 1000 Feb 27 2016 pyspark.cmd -rwxr-xr-x. 1 spark spark 2384 Feb 27 2016 run-example -rw-r--r--. 1 spark spark 2682 Feb 27 2016 run-example2.cmd -rw-r--r--. 1 spark spark 1012 Feb 27 2016 run-example.cmd -rwxr-xr-x. 1 spark spark 2858 Feb 27 2016 spark-class -rw-r--r--. 1 spark spark 2365 Feb 27 2016 spark-class2.cmd -rw-r--r--. 1 spark spark 1010 Feb 27 2016 spark-class.cmd -rwxr-xr-x. 1 spark spark 1049 Feb 27 2016 sparkR -rw-r--r--. 1 spark spark 1010 Feb 27 2016 sparkR2.cmd -rw-r--r--. 1 spark spark 998 Feb 27 2016 sparkR.cmd -rwxr-xr-x. 1 spark spark 3026 Feb 27 2016 spark-shell -rw-r--r--. 1 spark spark 1528 Feb 27 2016 spark-shell2.cmd -rw-r--r--. 1 spark spark 1008 Feb 27 2016 spark-shell.cmd -rwxr-xr-x. 1 spark spark 1075 Feb 27 2016 spark-sql -rwxr-xr-x. 1 spark spark 1050 Feb 27 2016 spark-submit -rw-r--r--. 1 spark spark 1126 Feb 27 2016 spark-submit2.cmd -rw-r--r--. 1 spark spark 1010 Feb 27 2016 spark-submit.cmd [spark@sparksinglenode bin]$
拿bin目录而言。比如
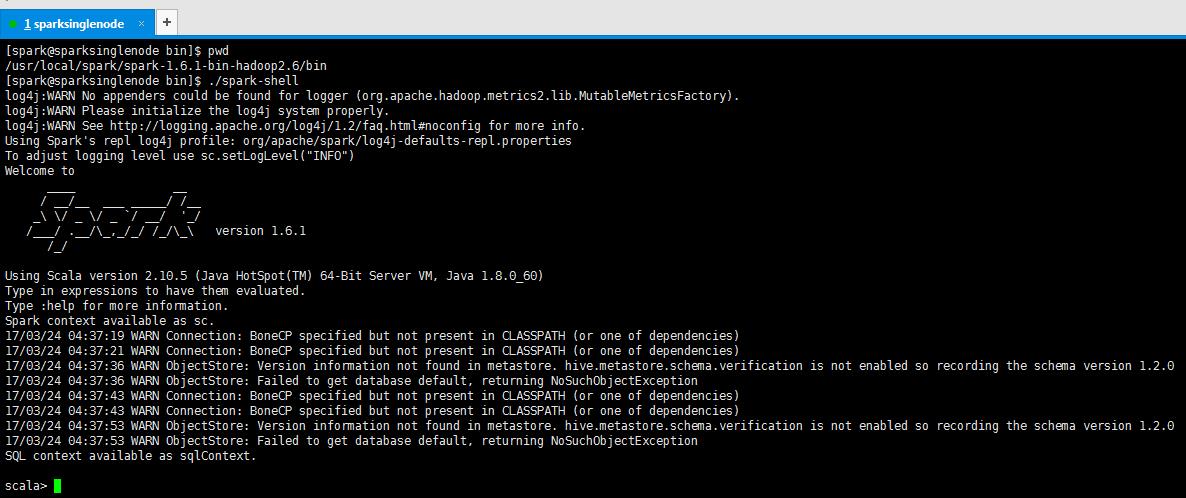
[spark@sparksinglenode bin]$ pwd /usr/local/spark/spark-1.6.1-bin-hadoop2.6/bin [spark@sparksinglenode bin]$ ./spark-shell log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Using Spark\'s repl log4j profile: org/apache/spark/log4j-defaults-repl.properties To adjust logging level use sc.setLogLevel("INFO") Welcome to ____ __ / __/__ ___ _____/ /__ _\\ \\/ _ \\/ _ `/ __/ \'_/ /___/ .__/\\_,_/_/ /_/\\_\\ version 1.6.1 /_/ Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60) Type in expressions to have them evaluated. Type :help for more information. Spark context available as sc. 17/03/24 04:37:19 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies) 17/03/24 04:37:21 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies) 17/03/24 04:37:36 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0 17/03/24 04:37:36 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException 17/03/24 04:37:43 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies) 17/03/24 04:37:43 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies) 17/03/24 04:37:53 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0 17/03/24 04:37:53 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException SQL context available as sqlContext. scala>
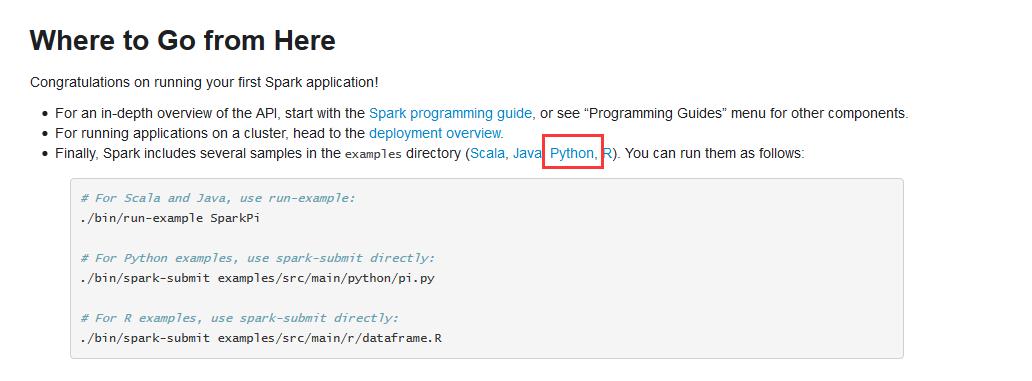
拿example而言,比如
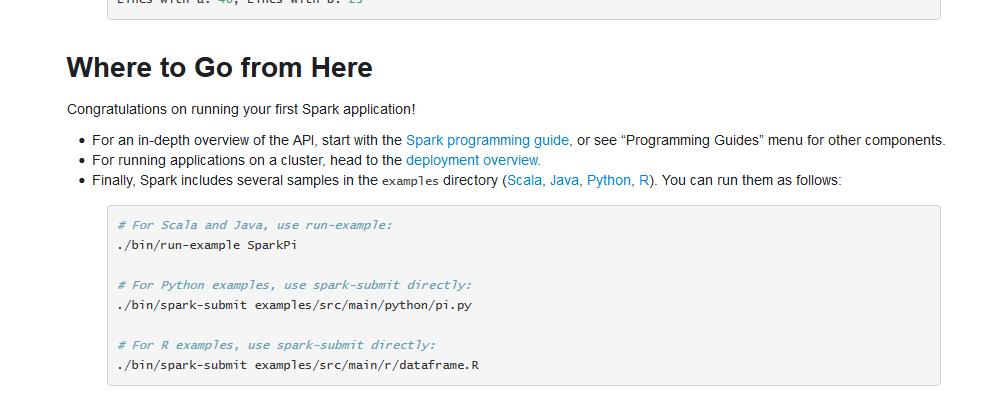
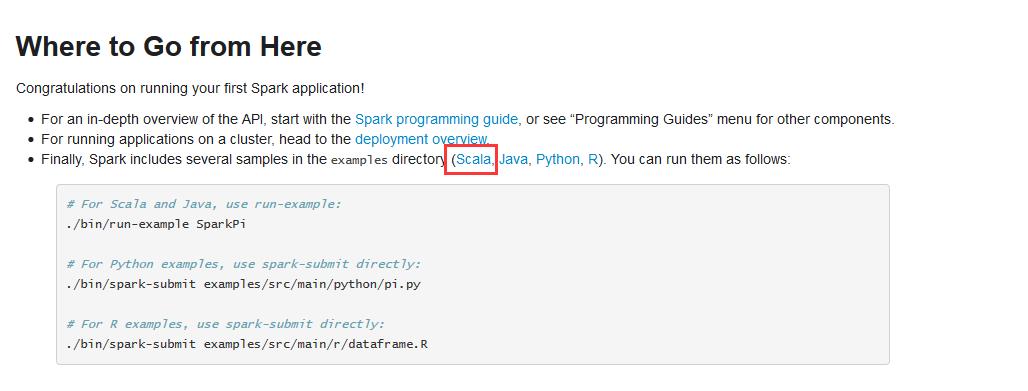
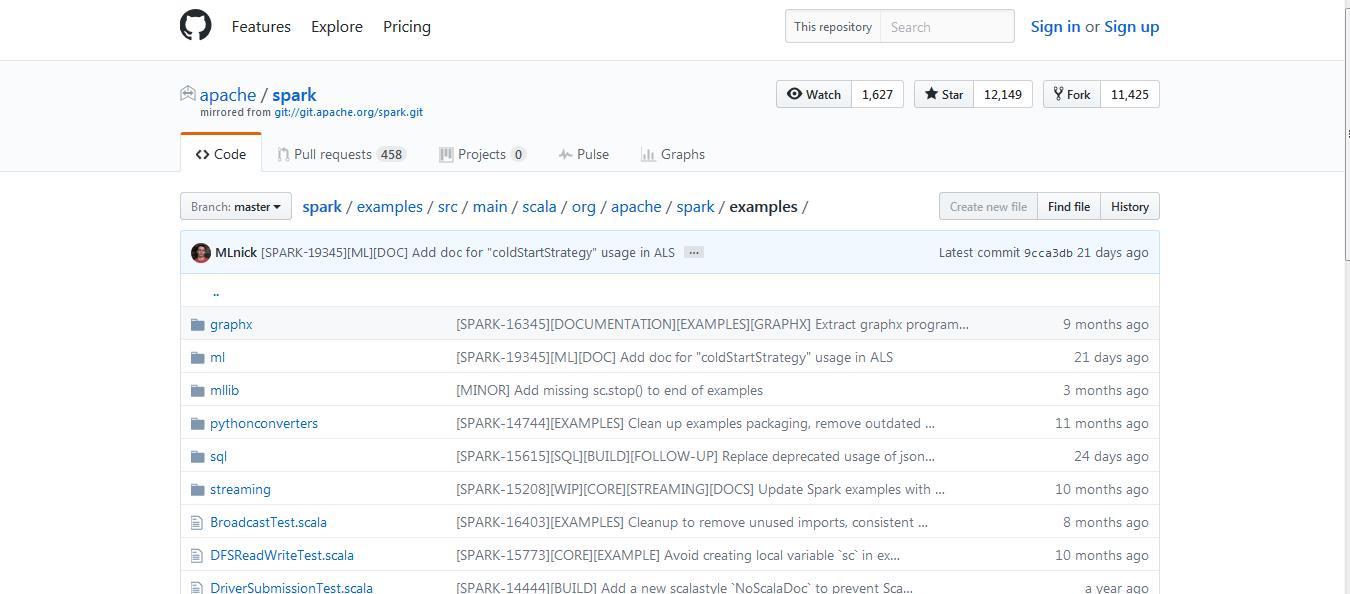
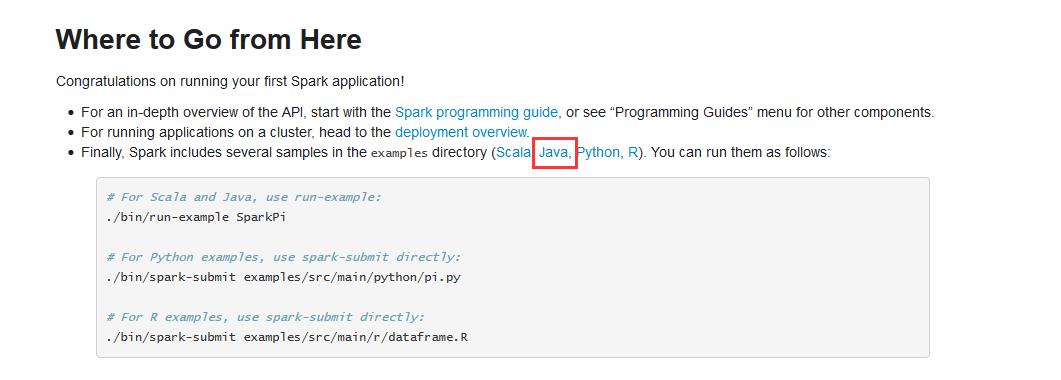
例子,(官网给的)
http://spark.apache.org/docs/latest/quick-start.html
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



打开百度App,扫码,精彩文章每天更新!欢迎关注我的百家号: 九月哥快讯

以上是关于带你认识spark安装包的目录结构的主要内容,如果未能解决你的问题,请参考以下文章