spark算子 分为3大类
Posted 薛定谔的猫!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark算子 分为3大类相关的知识,希望对你有一定的参考价值。
value类型的算子
处理数据类型为value型的算子(也就是这个算子只处理数据类型为value的数据),可以根据rdd的输入分区与输出分区的关系分为以下几个类型
map型:对rdd的每个数据项,通过用户自定义的函数映射转换成一个新的rdd
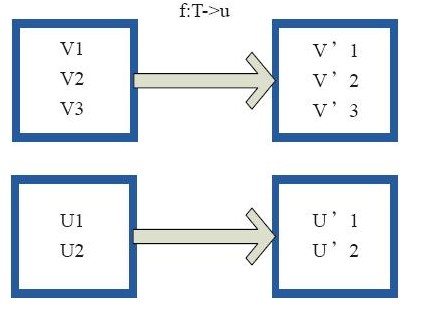
上面4个方框表示4个rdd分区,当第一个方框中的rdd经过用户自定义的map函数从v1映射为v,1.这种操作只有等到action算子触发后,这个函数才会和其他的函数在一个stage中对数据进行运算
flagMap型:将原来的rdd通过用户自定义的函数,转化为一个新的rdd,然后再将每个新生成rdd中集合的每个元素合并成一个集合
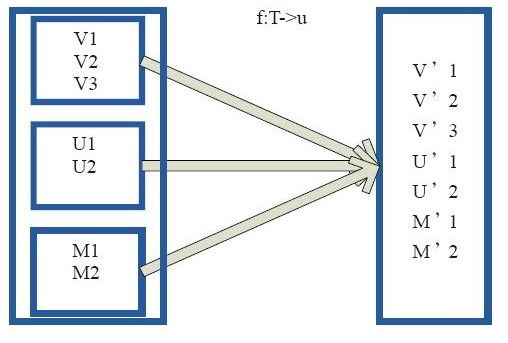
外部的大方框可以看做是一个rdd的分区,里面的小方框看做是rdd中的集合,小方框中的集合作为rdd的一个数据项,通过用户自定义的函数进行拆散,然后在对每个集合中的元素合并成一个集合
mapPartition型:通过这个函数可以每个分区的迭代器,这个迭代器可以可以对分区中的每个集合进行操作
上图中的每一个方框代表一个rdd分区,这个分区通过用户自定义的函数对每个分区中的数据项进行过滤,将过滤后的数据转换为一个新的rdd
glom:是将rdd中的数据项转换为一个数组
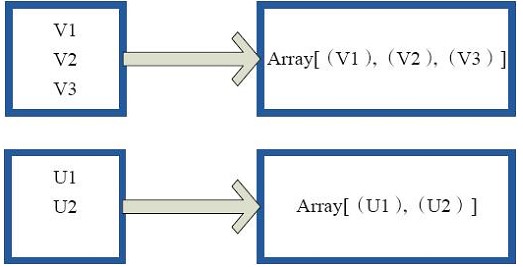
(2)![]() 输入分区与输出分区为多对一型
输入分区与输出分区为多对一型
union型:在使用union函数的时候要保证要合并的两个rdd数据类型保证一致,并且返回rdd的数据类型和被合并的rdd类型一致,在union的时候数据数据是不去重的,所有的元素都会保留,如果想去重可以使用distinct()函数
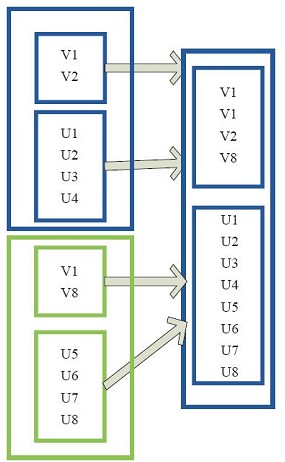
cartesian型:就是对两个rdd对笛卡尔积操作
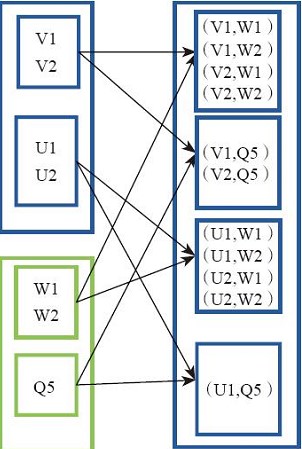
(3)![]() 输入分区与输出分区为多对多型
输入分区与输出分区为多对多型
groupby型:将元素通过函数生成对应的key,然后再对key进行分组(将相同的key分为一组),groupbykey(key)对key进行分组,其中key就决定了分区的个数和分区的函数,和并行化的个数
(4)![]() 输出分区为输入分区的子集型
输出分区为输入分区的子集型
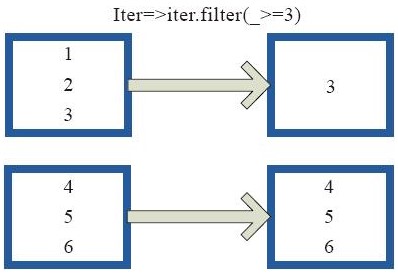
filter型:filter的功能是对rdd中的元素进行过滤,每个元素都应用于用户自定义的函数,返回值为true得以保留,false则会过滤掉
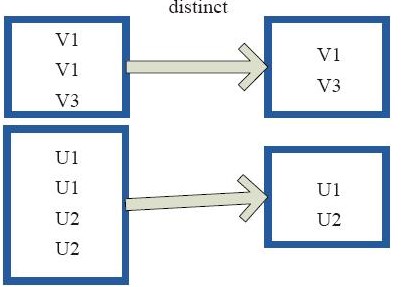
distinct型:对rdd中相同的元素进行去重
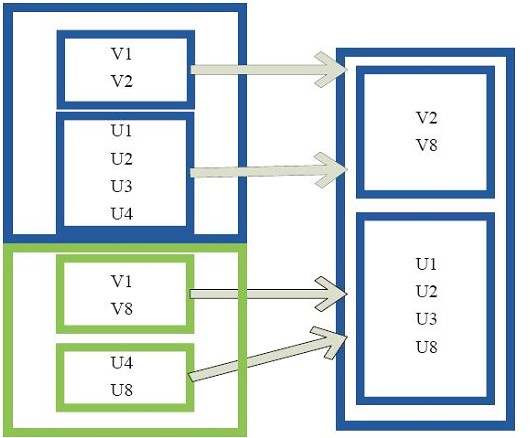
subtract型:subtract是对rdd进行减操作,比如过滤rdd1和rdd2 中有交集的元素
sample型:sample会对rdd的所有元素进行采样,获取元素的子集。用户可以设置是否有放回的抽样,百分比,随机种子,从而决定采样的方式
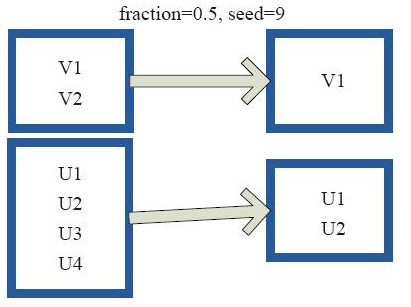
上图每一个方框是一个rdd分区,对rdd元素进行50%的采样。
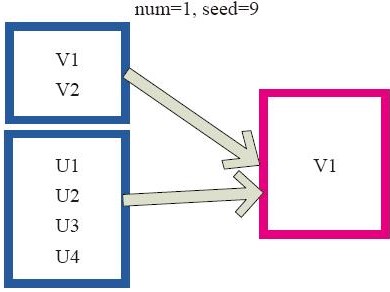
(5)![]() 还有一种输入分区与输出分区一对一型:cache型,cache分区对rdd的分区进行缓存
还有一种输入分区与输出分区一对一型:cache型,cache分区对rdd的分区进行缓存
cache型:cache就是将磁盘上的数据加载到内存里,相当于presiste(momory_only)函数功能
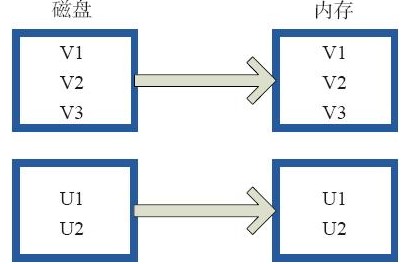
presiste型:presiste会将数据缓存操作,至于缓存到哪里由storageLevel的枚举值来确定:
storageLevel:MEMONRY(内存),DIS(磁盘),SER(该数据是否要序列化存储)
persist(newLevel:StorageLevel) //可你缓存的模式

以上是关于spark算子 分为3大类的主要内容,如果未能解决你的问题,请参考以下文章