spark算子 分为3大类
Posted 薛定谔的猫!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark算子 分为3大类相关的知识,希望对你有一定的参考价值。
transgormation的算子对key-value类型的数据有三种:
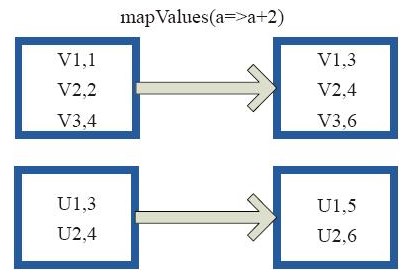
(1)输入 与 输出为一对一关系
mapValue();针对key-value类型的数据并只对其中的value进行操作,不对key进行操作
(2)对单个rdd聚集
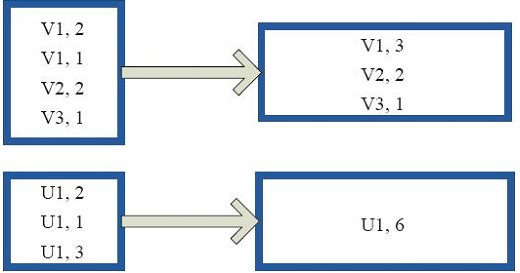
combineByKey
相当于将(v1,2 v1,1)转为(v1,Seq(1,2))的rdd

reduceByKey
就是将相同的key合并,算出他们的和
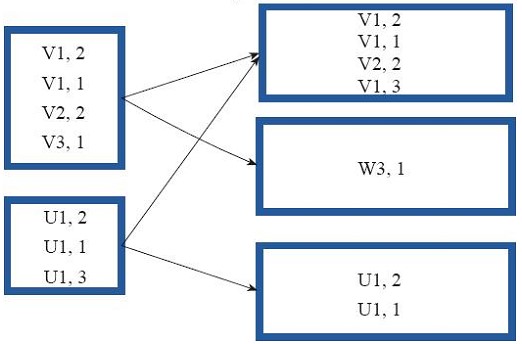
partitionBy
对rdd进行分区,如果原有的rdd与现在的rdd一致则不进行分区;如果不一致则根据分区策略生成一个新的rdd
(2)对两个rdd聚集
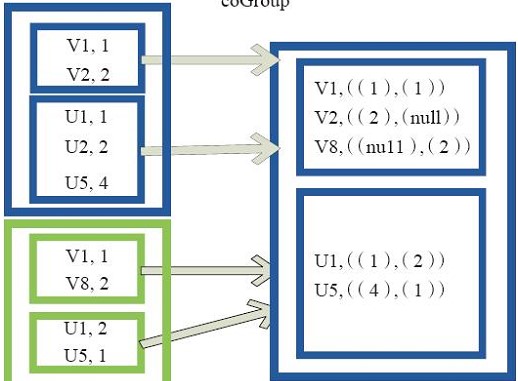
cogroup
对两个key-value的rdd,每个rdd相同的key的元素合并为一个集合,并且返回两个rdd中对应key元素的迭代器,
集合中的元素个数是相同的,没有则为null
join
join是先对rdd进行cogroup操作,然后再对新生成rdd,对key下的每个元素进行笛卡尔积操作,然后结果再平铺
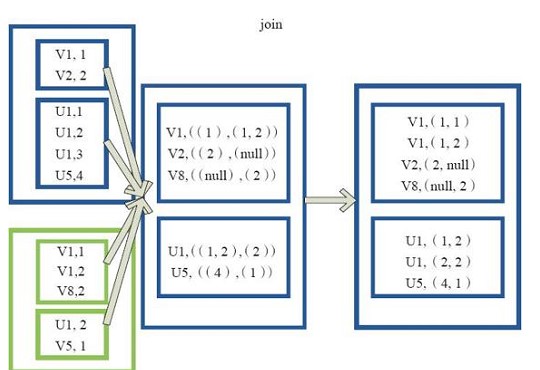
leftOutJoin和rightOutJoin
leftOutJoin(左外链接)和rightOutJoin(又外链接)意思相当,先对 两个rdd进行join操作,他在对key下面每个元素进行笛卡尔积操作之前,先判断value不为null.
以上是关于spark算子 分为3大类的主要内容,如果未能解决你的问题,请参考以下文章