spark算子 分为3大类
Posted 薛定谔的猫!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark算子 分为3大类相关的知识,希望对你有一定的参考价值。
ation算子通过sparkContext执行提交作业的runJob,触发rdd的DAG执行
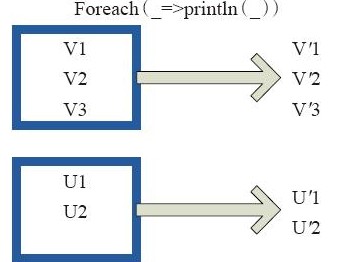
(foreach)
foreach(f) 会对rdd中的每个函数进行f操作,下面的f操作就是打印输出没有元素
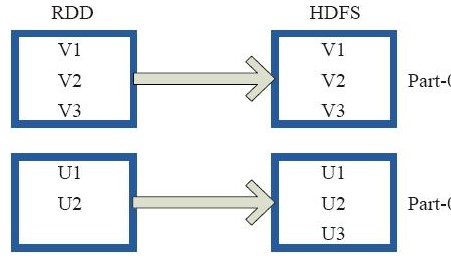
saveAsTextFile
将rdd保存到hdfs指定的路径,将rdd中每一个分区保存到hdfs上的block
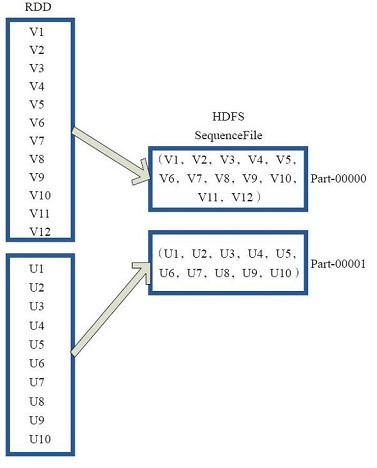
saveAsObjectFile
将rdd中每10个元素组成一个array,然后将这个array序列化,映射为(null,bytesWritable(y))
写入hdfs为Sequence格式
collect
collect将分布式的rdd返回成一个scala数组,通过函数操作,将结果返回到driver节点上存储

collectAsMap
对key-value型的rdd返回一个单击的hashMap,如果key值相同则后面的元素替换前面的元素

reduceByKeyLocally
实现是先reduce再collectAsMap操作,将结果返回一个hashMao
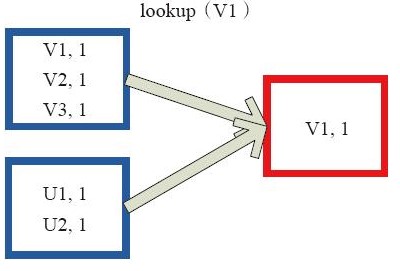
lookup
对key-value型的rdd进行操作,通过指定的key,返回对应元素的Seq()对象,这个算子的优化在于
如果这个rdd包含分区器,那么就只对指定key所在的分区进行扫描,如果没有则会对rdd进行全量扫描
count
就是返回整个rdd元素的个数
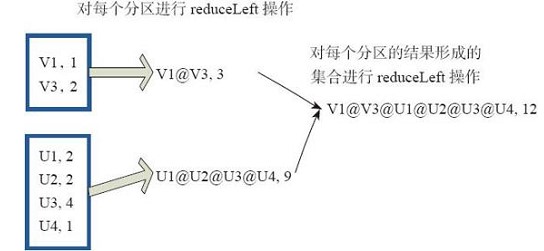
reduce
reduce就是先将rdd中的每个分区key-value的集合进行reduceLeft,在对每个分区形成的集合reduceFeft
广播变量
他广泛用户map site join 这些小表,以及广播大变量等场景,这些数据集合在单节点内存能够容纳,不想rdd那样在节点中 打散,spark运行时会把广播变量的数据发送到各个节点,保存下来,后续计算可以复用
以上是关于spark算子 分为3大类的主要内容,如果未能解决你的问题,请参考以下文章