HashMap的源码分析
Posted beppezhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap的源码分析相关的知识,希望对你有一定的参考价值。
hashMap的底层实现是 数组+链表 的数据结构,数组是一个Entry<K,V>[] 的键值对对象数组,在数组的每个索引上存储的是包含Entry的节点对象,每个Entry对象是一个单链表结构,维护这下一个Entry节点的引用;有点绕,用个图来展示吧:
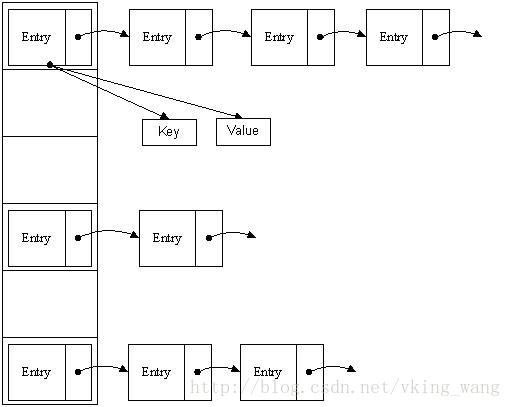
Entry<K,V>[] 数组部分保存的是首个Entry节点;Entry节点包含一个 K值引用 V值引用 以及 引用下一个Entry 节点的next引用;
Entry节点的java代码实现如下:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; //key 引用 V value; //value 引用 Entry<K,V> next; //下一个Entry 节点的引用 }
下面再看下HashMap 对象的java实现代码:
包含的属性有:
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* An empty table instance to share when the table is not inflated.
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
* The next size value at which to resize (capacity * load factor).
* @serial
*/
// If table == EMPTY_TABLE then this is the initial capacity at which the
// table will be created when inflated.
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
}
比较重要的属性是:
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; 表明这是一个 Entry<K,V>[] 的数组类型;
下面看其无参的构造器:
public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); }
进入以下的构造方法:
public HashMap(int initialCapacity, float loadFactor) { //initialCapacity:16 loadFactor 0.75f if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) //MAXIMUM_CAPACITY 1073741824 false
initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) false throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; //赋值给loadFactor=0.75 threshold = initialCapacity; //赋值给threshold=16 当为16是自动扩容 init(); }
下面再看看put(E e)的方法:
public V put(K key, V value) { //如插入 key="city" value="shanghai"
if (table == EMPTY_TABLE) { //true
inflateTable(threshold); //参数为16
}
if (key == null) // false
return putForNullKey(value);
int hash = hash(key); //返回key值的hash码; 比如返回为 337
int i = indexFor(hash, table.length); //将hash 取模与16 获得的结果为 1
for (Entry<K,V> e = table[i]; e != null; e = e.next) { //遍历 Entry[1] 中的链表节点对象 包含 原先有的节点和新增进去的节点
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { //当Entry中包含 相同的hash码的key 并且key和要添加的key相等即可以是否重复 则进入以下逻辑:新节点替换重复的节点
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
下面是 inflateTable(threshold) 方法的源码;
/**
* Inflates the table.
*/
private void inflateTable(int toSize) { //toSize 16
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize); //capacity=16
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // threshold=16*0.75
table = new Entry[capacity]; //创建 Entry[] 数组长度为16
initHashSeedAsNeeded(capacity); //这个方法可以暂时不用深究
}
下面是 roundUpToPowerOf2(int i) 源码
private static int roundUpToPowerOf2(int number) { // number=16
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY //fase 返回 16
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; //number=16>1 返回 16
}
put 方法的源码分析完了之后,接下来再看一下get(Object key) 的方法; 源码:
public V get(Object key) { //如 key="name" if (key == null) //false return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
final Entry<K,V> getEntry(Object key) { //key=name
if (size == 0) { //false
return null;
}
int hash = (key == null) ? 0 : hash(key); //例如 返回hash=337
for (Entry<K,V> e = table[indexFor(hash, table.length)]; //indexFor(hash, table.length)上面分析过 返回值为 1;遍历 table[1] 中的节点
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) //如果存在key的hash码相等,并且对象也相等则返回 对应的Entry 节点
return e;
}
return null; //否则返回null
}
到此,hashMap 的源码基本分析完毕了,通过源码分析我们知道HashMap的底层是 数组+链表结构来存数数据的,添加节点存储的位置是根据 key 取hash值 再取模于数组长度:返回的数值就是Entry接在在数组的哪个位置;这种方式的存储方式减少了存储的时间和空间的复杂度;
知道了hashMap是由 数组+链表 的数据结构存储数据后,我们也很容易明白hashMap 的遍历方式:
以上是关于HashMap的源码分析的主要内容,如果未能解决你的问题,请参考以下文章