Regularization in Linear Regression & Logistic Regression
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Regularization in Linear Regression & Logistic Regression相关的知识,希望对你有一定的参考价值。
一、正则化应用于基于梯度下降的线性回归
上一篇文章我们说过,通过正则化的思想,我们将代价函数附加了一个惩罚项,变成如下的公式:
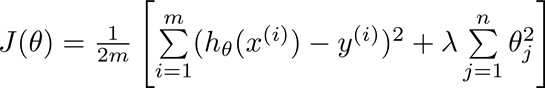
那么我们将这一公式套用到线性回归的代价函数中去。我们说过,一般而言θ0我们不做处理,所以我们把梯度下降计算代价函数最优解的过程转化为如下两个公式。
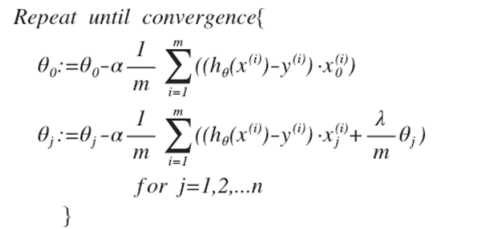
我们通过j>0的式子,能够分析得出,θj 我们可以提取公因子,即将上式变成:
由于θj的系数小于1,可以看出, 正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的
基础上令 θ 值减少了一个额外的值。 那么至此,上述公式即为正则化应用于线性回归梯度下降的公式。
二、正则化应用于基于正规方程的线性回归
回顾一下正规方程,正规方程及通过巧妙的数学运算推到而来的,不需要复杂迭代计算的矩阵公式。
我们将其分为特征变量矩阵X,以及输出结果向量y。其中X矩阵中的每一项元素都含有n个特征变量,同时需要在第一列补充适合 θ0的值,假设共有m组数据,也就是X,y的行数为m行,那么X矩阵便是m×(n+1)的矩阵,y则是m×1的向量。
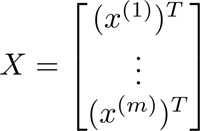
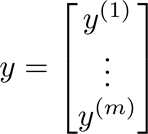
由此,我们能够推导出如下的正规方程,以此来求解θ向量:
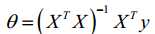
通过正则化,我们将正规方程转化为如下式子:其中的矩阵为(n+1)×(n+1)的。
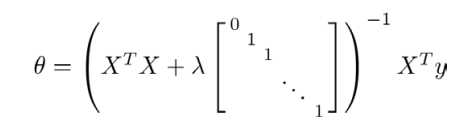
三、正则化应用于逻辑回归
与上面的线性回归相同,只不过假设函数hx变成了sigmoid函数。
以上是关于Regularization in Linear Regression & Logistic Regression的主要内容,如果未能解决你的问题,请参考以下文章
ISLR第六章Linear Model Selection and Regularization
Andrew Ng Machine Learning 专题Linear Regression
Chapter -- Linear Equations in Linear Algebra
Shadow price in linear programming