关于rnn神经网络的loss函数的一些思考
Posted LarryGates
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于rnn神经网络的loss函数的一些思考相关的知识,希望对你有一定的参考价值。
---
做了这么长时间的基于深度学习的NLP,愈发可以感受到bayesian的意思,语言模型里面一切皆是分布,问题答案都是分布,一个问题模拟出来的是一个答案的分布;
我觉得我做的最好的一个聊天模型,就是先将问题表示成一个100维的高斯分布,然后计算各个答案跟这个分布的契合概率,当然这个模型肯定不能放出来,但是这种思想可以延伸出去,也希望有兴趣的朋友跟我探讨探讨,jy2641@columbia.edu.
---
0: 原则上,loss函数都应该选convex函数,convex函数的定义就是函数上方得点是一个convex集合
1: 之前使用的0-1的数据预测正负样本,loss函数选用的是cross entropy loss,
实际上这里的0-1 cross entropy和seq2seq的softmax cross entropy都是使用的log函数算的loss,
但是最近看到有人说,在seq2seq里面使用MSE, mean square error比softmax cross entropy要好很多,
遂作下图,可以观察比较一下各个不同的loss函数;
下面是对于分类里面的三种常见的loss的比较,函数形式是
x: predicted - true value的绝对值
log_loss = -np.log(1- x + 1e-12)
mse = x*x
abs_loss = x
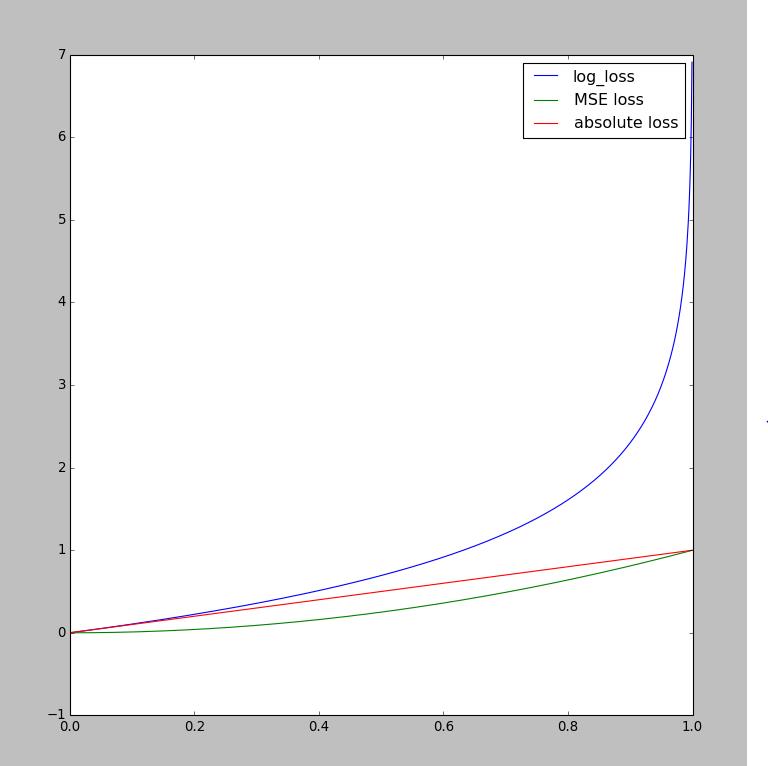
我的感觉是,类别非常多,或者越不能准确预测某一类的值的时候,不要用log loss
2: 对于刚刚做的问答匹配采用正样本和负样本之间的cosine差值的loss;
loss = max(0, 0.2 - cosine(question, true answer) + cosine(question, negative answer))
之所以有效,可能是为了防止模型过多关注那些泾渭分明的case,而不去关注那些true answer 和 negative answer很模糊的case;
以上是关于关于rnn神经网络的loss函数的一些思考的主要内容,如果未能解决你的问题,请参考以下文章