LRN和Batch Norm
Posted 庖丁解牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LRN和Batch Norm相关的知识,希望对你有一定的参考价值。
LRN
LRN全称为Local Response Normalization,局部相应归一化层。
message LRNParameter {
optional uint32 local_size = 1 [default = 5];
optional float alpha = 2 [default = 1.];
optional float beta = 3 [default = 0.75];
enum NormRegion {
ACROSS_CHANNELS = 0;
WITHIN_CHANNEL = 1;
}
optional NormRegion norm_region = 4 [default = ACROSS_CHANNELS];
optional float k = 5 [default = 1.];
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 6 [default = DEFAULT];
}
NormRegion选择通道间归一化还是通道内空间区域归一化,默认是AcrOSS_CHANNELS,通道间。
local_size表示:通道间时为求和的通道数,通道内是为求和的区间边长,默认为5。
alpha缩放因子,beta指数项。
在通道间归一化模式中,局部区域范围是:local_size*1*1;在通道内归一化模式中,局部区域范围是:1*local_size*local_size。归一化后的值:
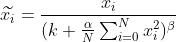
实现代码见:lrn_layer.cpp,也比较简单。
Batch Normalization
ZCA白化:http://blog.csdn.net/hjimce/article/details/50864602
对输入数据进行预处理,减均值->zscore->白化可以逐级提升随机初始化的权重对数据分割的有效性,还可以降低overfit的可能性。Google的这篇论文http://arxiv.org/pdf/1502.03167v3.pdf, 提出了BN层。
首先,BN不是针对x(输入的),而是针对Wx+b的,论文的解释是:Wx+b每维的均值本身就接近0、方差接近1,所以在Wx+b后使用Batch Normalization能得到更稳定的结果。
文中使用了类似z-score的归一化方式:每一维度减去自身均值,再除以自身标准差。由于使用的是随机梯度下降法,这些均值和方差也只能在当前迭代的batch中计算。Wx+b的均值和方差是对整张map求得的,在batch_size * channel * height * width这么大的一层中,对总共batch_size*height*width个像素点统计得到一个均值和一个标准差,共得到channel组参数。
在Normalization完成后,Google的研究员仍对数值稳定性不放心,又加入了两个参数gamma和beta,使得:
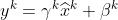
在BP的时候,我们需要求最终的损失函数对gamma和beta两个参数的导数,还要求损失函数对Wx+b中的x的导数,以便使误差继续向后传播。
在训练的最后一个epoch时,要对这一epoch所有的训练样本的均值和标准差进行统计,这样在一张测试图片进来时,使用训练样本中的标准差的期望和均值的期望对测试数据进行归一化,注意这里标准差使用的期望是其无偏估计:

优势是:更高的学习率,更快的训练过程;防止过拟合,移除或使用较小的dropout;取消LRN层。
caffe的BN
参数定义:
message BatchNormParameter {
// If false, accumulate global mean/variance values via a moving average. If
// true, use those accumulated values instead of computing mean/variance
// across the batch.
optional bool use_global_stats = 1;
// How much does the moving average decay each iteration?
optional float moving_average_fraction = 2 [default = .999];
// Small value to add to the variance estimate so that we don\'t divide by
// zero.
optional float eps = 3 [default = 1e-5];
}
use_global_stats如果是真使用保存的均值和方差,否则使用滑动平均计算新的均值和方差。测试时为真,训练时为假。
moving_average_fraction滑动平均的衰减系数;eps为分母附加项。
均值和方差的更新
BN层共存储了3个数值:均值滑动和、方差滑动和、滑动系数和,计算公式如下:
设moving_average_fraction为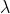 , 计算元素的数目为
, 计算元素的数目为,均值滑动和为
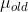 ,方差滑动和为
,方差滑动和为 ,滑动系数和为
,滑动系数和为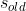 。
。
如果当前batch的均值和方差为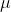 ,
, ,则更新后:
,则更新后:


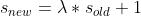
均值和方差的使用
caffe到目前仍然没有实现和论文原文保持一致的BN层,即没有 α和β 参数,因此更新公式就比较简单了,为每一个channel施加如下公式:
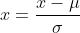
但是需要注意的是,我们存储的是均值和方差的滑动和,因此还要做一些处理。
首先计算缩放因子: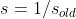 .如果
.如果 ,s=0.
,s=0.
处理后得:
均值:
标准差:
%5e%7b0.5%7d)
caffe中使用batch_norm_layer和scale_layer两个层可以达到google论文中的效果,示例:https://github.com/KaimingHe/deep-residual-networks/blob/master/prototxt/ResNet-50-deploy.prototxt
以上是关于LRN和Batch Norm的主要内容,如果未能解决你的问题,请参考以下文章