[编织消息框架][设计协议]解决粘包半包(下)
Posted solq321
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[编织消息框架][设计协议]解决粘包半包(下)相关的知识,希望对你有一定的参考价值。
接下来介绍netty如何切割分包
学习目的,了解处理业务,方便以后脱离依赖
读者如果不感兴趣或看不懂可以先忽略,难度比较大
LengthFieldBasedFrameDecoder.class
public LengthFieldBasedFrameDecoder( ByteOrder byteOrder, //大小端模式 默认大端 ByteOrder BIG_ENDIAN int maxFrameLength, //包Frame netty叫帧概念 最大上限 int lengthFieldOffset, //包长度信息偏移多少bytes int lengthFieldLength, //包长度单位为bytes int lengthAdjustment, //包附加信息占多少位,如包尾部checksum 也可以不用设置 int initialBytesToStrip,//忽悠包头信息,返给上层时会去掉这部份bytes boolean failFast) //解包出错,控制抛异常,默认为true 无需关心这选项
如示例
int maxFrameLength = Short.MAX_VALUE; int lengthFieldOffset =1; int lengthFieldLength =2; new LengthFieldBasedFrameDecoder(ByteOrder.BIG_ENDIAN,maxFrameLength,lengthFieldOffset,lengthFieldLength,0,0,true);
如图:
数据包由低到高是从左到右
红色部份lengthFieldOffset 1byte=8bits
蓝色部份lengthFieldLength 2byte=16bits = short
粉色部份messageLength 2byte 读取 蓝色部份由于大端模式 高位 0000 0010 等于2
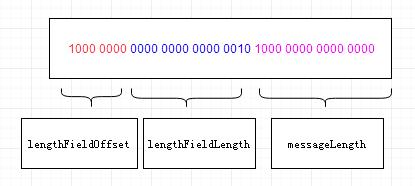
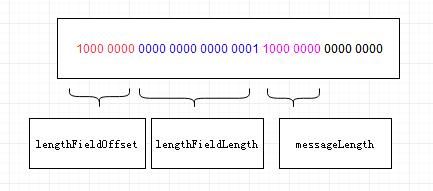
图2
消息长度为1byte
解读netty源码
分四部份
1.netty解码介绍
2.边界判断
3.计算逻辑
4.切割包
第一部份
先看下LengthFieldBasedFrameDecoder继承类之间的关系

ByteToMessageDecoder处理比较复杂,先不考虑
其实解码只要工作方法是
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception
//公开调用方法 out 是解码后保存返回,为什么是个数组?原因有可能出现粘包情况多次解码,合并结果一次返回上层业务 protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { //调用实现解码方法 Object decoded = decode(ctx, in); if (decoded != null) { out.add(decoded); } }
提示:如果自己实现解码 继承ByteToMessageDecoder类,逻辑写在decode(ChannelHandlerContext ctx, ByteBuf in)方法即可
第三部份


1 //计算包长度偏移坐标 已读坐标+lengthFieldOffset参数 2 int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset; 3 //算出包长度 4 long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder); 5 6 //包实际长度 加上开始忽悠的 lengthFieldEndOffset参数 加上 lengthAdjustment 参数 7 frameLength += lengthAdjustment + lengthFieldEndOffset; 8 9 //跳过忽悠头部 initialBytesToStrip参数 10 in.skipBytes(initialBytesToStrip); 11 12 //length 单位是byte 如2 是占一个short长度 4占int长度 8占long长度 13 protected long getUnadjustedFrameLength(ByteBuf buf, int offset, int length, ByteOrder order) { 14 //转换大小端模式 15 buf = buf.order(order); 16 long frameLength; 17 switch (length) { 18 case 1: 19 frameLength = buf.getUnsignedByte(offset); 20 break; 21 case 2: 22 frameLength = buf.getUnsignedShort(offset); 23 break; 24 case 3: 25 frameLength = buf.getUnsignedMedium(offset); 26 break; 27 case 4: 28 frameLength = buf.getUnsignedInt(offset); 29 break; 30 case 8: 31 frameLength = buf.getLong(offset); 32 break; 33 default: 34 throw new DecoderException( 35 "unsupported lengthFieldLength: " + lengthFieldLength + " (expected: 1, 2, 3, 4, or 8)"); 36 } 37 return frameLength; 38 }
第四部份
1 //切割实现,直接调用ByteBuf 方法切割 2 /** 3 * Extract the sub-region of the specified buffer. 4 * <p> 5 * If you are sure that the frame and its content are not accessed after 6 * the current {@link #decode(ChannelHandlerContext, ByteBuf)} 7 * call returns, you can even avoid memory copy by returning the sliced 8 * sub-region (i.e. <tt>return buffer.slice(index, length)</tt>). 9 **/ 10 protected ByteBuf extractFrame(ChannelHandlerContext ctx, ByteBuf buffer, int index, int length) { 11 return buffer.retainedSlice(index, length); 12 } 13 14 AbstractUnpooledSlicedByteBuf.class 15 //深追ByteBuf切割实现,发现返回的ByteBuf只是保留引用,只是简单记录了下offsetStart adjustment writerIndex 16 AbstractUnpooledSlicedByteBuf(ByteBuf buffer, int index, int length) { 17 super(length); 18 checkSliceOutOfBounds(index, length, buffer); 19 20 if (buffer instanceof AbstractUnpooledSlicedByteBuf) { 21 this.buffer = ((AbstractUnpooledSlicedByteBuf) buffer).buffer; 22 adjustment = ((AbstractUnpooledSlicedByteBuf) buffer).adjustment + index; 23 } else if (buffer instanceof DuplicatedByteBuf) { 24 this.buffer = buffer.unwrap(); 25 adjustment = index; 26 } else { 27 this.buffer = buffer; 28 adjustment = index; 29 } 30 31 initLength(length); 32 writerIndex(length); 33 }
第二部份
现在回过头来看边界判断,主要是看处理出错逻辑部份
1 long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder); 2 //解码出错 3 if (frameLength < 0) { 4 //无法计算包内容时netty策略选择跳过 包头信息跟包长度大小 5 in.skipBytes(lengthFieldEndOffset); 6 throw new CorruptedFrameException( 7 "negative pre-adjustment length field: " + frameLength); 8 } 9 10 frameLength += lengthAdjustment + lengthFieldEndOffset; 11 //奇怪的逻辑,上面已加上 lengthFieldEndOffset 除非 lengthAdjustment 参数或 lengthFieldEndOffset参数设置为负值 12 //一般没什么复杂情况最好不要设置负值 13 if (frameLength < lengthFieldEndOffset) { 14 in.skipBytes(lengthFieldEndOffset); 15 throw new CorruptedFrameException( 16 "Adjusted frame length (" + frameLength + ") is less " + 17 "than lengthFieldEndOffset: " + lengthFieldEndOffset); 18 } 19 20 // never overflows because it\'s less than maxFrameLength 21 int frameLengthInt = (int) frameLength; 22 //缓冲剩余可读bytes少于包长度,说明出现半包情况,忽略处理 23 if (in.readableBytes() < frameLengthInt) { 24 return null; 25 } 26 //如果包长度少于 initialBytesToStrip 参数会抛异常并且跳过包内容 27 //没什么特殊情况最好不要设置initialBytesToStrip参数 28 if (initialBytesToStrip > frameLengthInt) { 29 in.skipBytes(frameLengthInt); 30 throw new CorruptedFrameException( 31 "Adjusted frame length (" + frameLength + ") is less " + 32 "than initialBytesToStrip: " + initialBytesToStrip); 33 }
1 //包长度大于 maxFrameLength 2 //看下netty处理策略 3 if (frameLength > maxFrameLength) { 4 //算出超出范围 5 long discard = frameLength - in.readableBytes(); 6 //记录包长度 7 tooLongFrameLength = frameLength; 8 9 //有两种情况处理 10 11 //存在粘包情况,直接 in.skipBytes((int) frameLength);跳过当前包 什么也不用记录 12 if (discard < 0) { 13 // buffer contains more bytes then the frameLength so we can discard all now 14 in.skipBytes((int) frameLength); 15 } else { 16 //当 discard>=0 17 //说明没存在粘包情况,有可能出现半包情况,in.skipBytes(in.readableBytes()); 清空所有接收数据 18 //设置discardingTooLongFrame,bytesToDiscard记录超出范围,下次解码时用上 19 // Enter the discard mode and discard everything received so far. 20 discardingTooLongFrame = true; 21 bytesToDiscard = discard; 22 in.skipBytes(in.readableBytes()); 23 } 24 failIfNecessary(true); 25 return null; 26 } 27 28 //当上次包出现超过最大包限制,要忽悠上个包半包情况 29 if (discardingTooLongFrame) { 30 long bytesToDiscard = this.bytesToDiscard; 31 //剩余半包长度 32 int localBytesToDiscard = (int) Math.min(bytesToDiscard, in.readableBytes()); 33 //忽略剩余半包长度 34 in.skipBytes(localBytesToDiscard); 35 //记录忽略已忽略多少bytes 36 bytesToDiscard -= localBytesToDiscard; 37 this.bytesToDiscard = bytesToDiscard; 38 //如果this.bytesToDiscard==0 说明已全部忽略上一个包 会重置 discardingTooLongFrame 39 failIfNecessary(false); 40 } 41 42 private void failIfNecessary(boolean firstDetectionOfTooLongFrame) { 43 if (bytesToDiscard == 0) { 44 // Reset to the initial state and tell the handlers that 45 // the frame was too large. 46 long tooLongFrameLength = this.tooLongFrameLength; 47 this.tooLongFrameLength = 0; 48 discardingTooLongFrame = false; 49 if (!failFast || 50 failFast && firstDetectionOfTooLongFrame) { 51 fail(tooLongFrameLength); 52 } 53 } else { 54 // Keep discarding and notify handlers if necessary. 55 if (failFast && firstDetectionOfTooLongFrame) { 56 fail(tooLongFrameLength); 57 } 58 } 59 }
当大于maxFrameLength 处理核心忽略当前包,如果存在粘包直接忽略,如果存在半包记录剩余包大小bytesToDiscard,下次循环解码时不停跳过bytesToDiscard
关于分包处理
为何需要分包?比如要传送10G大小的文件,如果把数据全读进内存再发送出去,明显是不合理的,这时要把10G大小的数据切割分批读,分批发送出去
为什么不做在应用协议里?因业太多业务上的逻辑,底层是无法控制的,再说是特定的功能,没必要添加支持,看作成业务上一个小功能实现就行了
以上是关于[编织消息框架][设计协议]解决粘包半包(下)的主要内容,如果未能解决你的问题,请参考以下文章