kafka分区分布
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka分区分布相关的知识,希望对你有一定的参考价值。
参考技术A 查看topic的分区情况bin/kafka-topics.sh --zookeeper 192.168.1.6:2181 --describe --topic test
partiton: partion id,由于此处只有一个partition,因此partition id 为0
leader:负责处理消息的读和写,当前负责读写的lead broker id,leader是从所有节点中随机选择的.
replicas:列出了所有的副本节点,不管节点是否在服务中.
isr:是正在服务中的节点.(relicas的子集,只包含出于活动状态的broker)
如上图:
Topic: test1
分区0在 broker 0, broker 1 ,broker 2 都有分布,其中broker 0是leader,其余是副本;
分区1在 broker 0, broker 1 ,broker 2 都有分布,其中broker 1是leader,其余是副本;
分区2在 broker 0, broker 1 ,broker 2 都有分布,其中broker 2是leader,其余是副本;
分布式实时消息队列Kafka
分布式实时消息队列Kafka(四)
知识点01:课程回顾
- Kafka中生产者的数据分区规则是什么?
- 先判断是否指定了分区
- 指定分区:写入对应分区
- 没有指定:判断是否指定了Key
- 指定了Key:按照Key的Hash分区
- 没有指定Key:按照黏性分区
- 特点:优先将所有数据构建一个Batch,提交到一个分区中,尽量保证数据分配均衡
- 自定义分区规则
- step1:开发一个类实现Partitioner
- step2:实现一个partition方法
- step3:生产者指定分区器
- 先判断是否指定了分区
- Kafka中消费者消费数据的规则是什么?
- 基础规则:每个消费者消费Topic分区的数据按照Offset进行消费
- 第一次消费:根据属性决定:latest【最新位置】,earliest【最早位置:-1,请求 -1 + 1】
- 从第二次开始:自动将上一次的位置 + 1向Kafka进行请求
- 问题1:如果消费者故障了,重启消费者,如何能知道上一次消费的位置?
- 原因:offset保存内存中,重启以后就没有了
- 如果消费者遇到故障,Kafka怎么保证不重复不丢失?
- Kafka将每个消费者消费的offset存储在一个独立的Topic中:__consumer_offsets
- 如果消费者故障,重启,从这个Topic查询上一次的offset + 1
- 问题2:这个Topic中记录的offset是怎么来的?
- 默认机制:根据时间周期由消费者自动提交
- 导致问题:数据重复或者数据丢失问题
- 解决问题:根据处理的结果来实现基于每个分区的手动提交
- 消费一个分区、处理一个分区、处理成功,提交这个分区的offset
- 工作中:不需要管使用手动提交还是自动提交?
- 因为工作中不利用Kafka的存储来实现offset的恢复
- 一般我们自己存储offset:将每个分区的offset存储在MySQL、Zookeeper、Redis
- 如果程序故障,从MySQL、Zookeeper、Redis中读取上一次的Offset
- Kafka中__consumer_offsets的作用是什么?
- 用于Kafka自己实现保证消费者消费数据不丢失不重复的问题:记录所有消费者Offset
知识点02:课程目标
- 消费者组中多个消费者如何分配分区消费的问题?
- 分配的规则是什么?
- 范围分配:默认的分配规则
- 轮询分配
- 黏性分配:建议使用的分配规则
- Kafka中数据读写的流程
- 分布式存储工具
- Zookeeper:分布式协调服务工具
- HDFS:分布式文件系统
- Hbase:分布式NoSQL数据库
- Kafka:分布式消息队列
- 写的流程是什么?为什么写的很快?
- 读的流程是什么?为什么读的很快?
- Kafka如何自动清理过期的数据
- 分布式存储工具
知识点03:消费分配策略:基本规则及分配策略
-
目标:掌握Kafka消费者组中多个消费者的分配规则及问题
-
路径
- step1:消费者组中消费者分配消费分区的基本规则是什么?
- step2:如果一个消费者组中有多个消费者,消费者组消费多个Topic,每个Topic有多个分区,如何分配?
-
实施
-
基本规则
-
一个分区的数据只能有一个消费者消费
-
不能实现多个消费者消费一个分区的数据
-
原因:每个消费者在逻辑上属于同一个消费者组,但是物理上独立的消费者,无法获取彼此的offset的,不能共同协作的
-
问题:怎么实现一个消费者组中有多个消费者?
-
第一个消费者代码
prop.set("group.id","test01") consumer01 = new KafkaConsumer(prop) -
第二个消费者代码
prop.set("group.id","test01") consumer02 = new KafkaConsumer(prop) -
……
-
-
-
一个消费者可以消费多个分区的数据
- 消费者会挨个分区进行消费
-
-
分配策略:决定了多个分区如何分配给多个消费者
-
属性
partition.assignment.strategy = org.apache.kafka.clients.consumer.RangeAssignor -
策略
-
RangeAssignor:范围分配,默认的分配策略
-
RoundRobinAssignor:轮询分配,常见于Kafka2.0之前的版本
org.apache.kafka.clients.consumer.RoundRobinAssignor -
StickyAssignor:黏性分配,2.0之后建议使用
org.apache.kafka.clients.consumer.StickyAssignor
-
-
-
-
小结
- 基本规则
- 一个分区只能由一个消费者来消费
- 一个消费者可以消费多个分区
- 分配策略
- 范围分配
- 轮询分配
- 黏性分配
- 基本规则
知识点04:消费分配策略:RangeAssignor
-
目标:掌握范围分配策略的规则及应用场景
-
路径
- step1:范围分配策略的规则是什么?
- step2:范围分配的优缺点是什么?
-
实施
-
范围分配规则
- Kafka中默认的分配规则
- 每个消费者消费一定范围的分区,尽量的实现将分区均分给不同的消费者,如果不能均分,优先将分区分配给编号小的消费者
- 6个分区:part0 ~ part5
- 2个消费者
- C1:part0 ~ part2
- C2:part3 ~ part5
- 4个消费者
- C1:part0 part1
- C2:part2 part3
- C3:part4
- C4:part5
- 2个消费者
-
举例
-
假设一:三个消费者,消费1个Topic,Topic1有6个分区
消费者 分区 C1 T1【0,1】 C2 T1【2,3】 C3 T1【4,5】 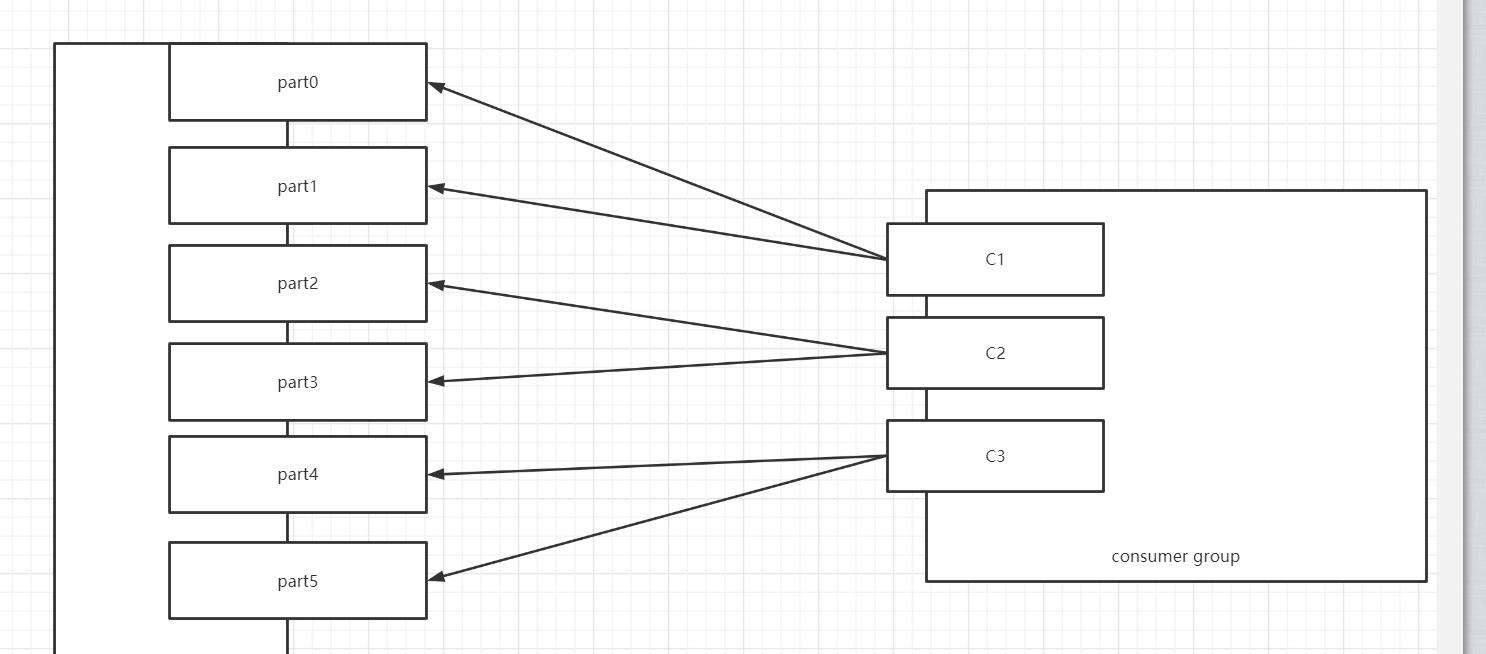
-
假设二:三个消费者,消费1个Topic,Topic1有7个分区
消费者 分区 C1 T1【0,1,2】 C2 T1【3,4】 C3 T1【5,6】 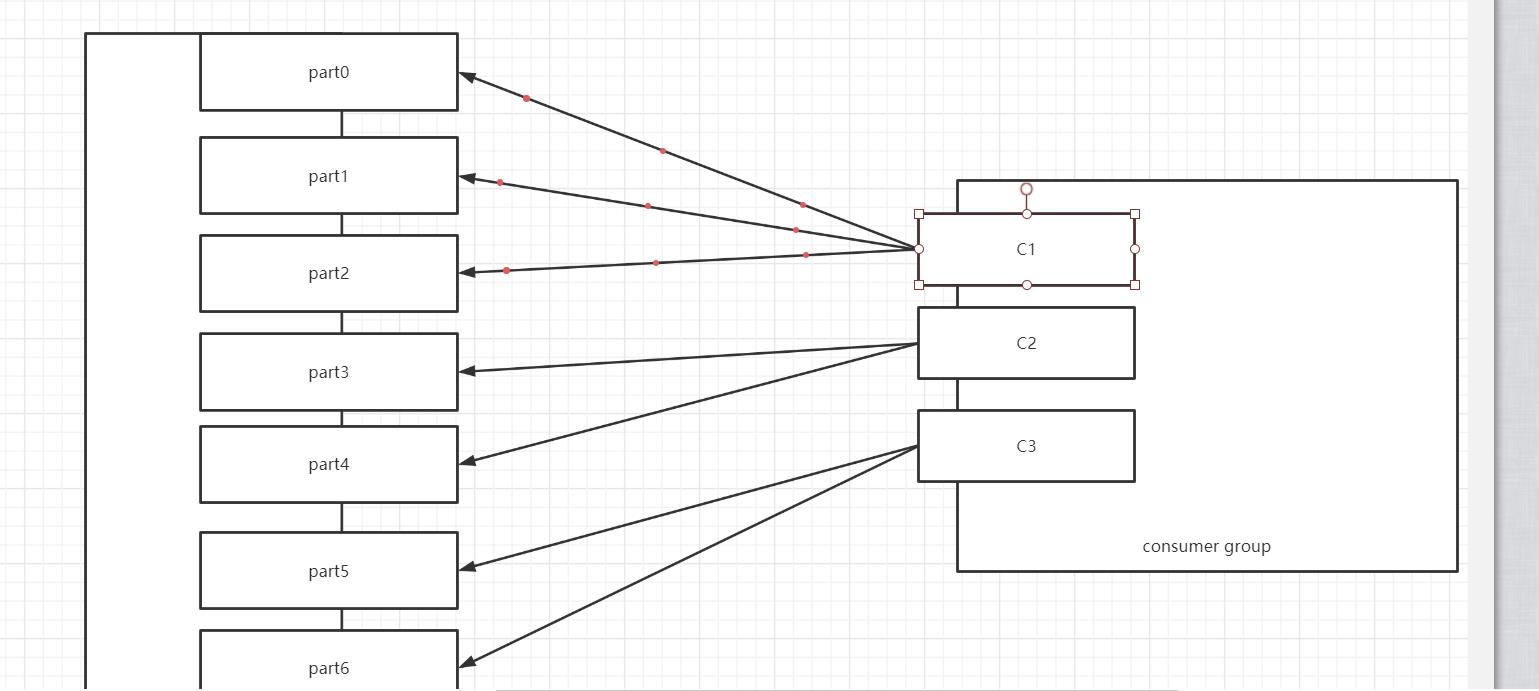
-
假设三:三个消费者,消费3个Topic,Topic1、Topic2、Topic3各有7个分区
消费者 分区 C1 T1【0,1,2】 T2【0,1,2】 T3【0,1,2】 C2 T1【3,4】 T2【3,4】 T3【3,4】 C3 T1【5,6】 T2【5,6】 T3【5,6】 - 问题:负载不均衡
-
-
范围分配优点
- 如果Topic的个数比较少,分配会相对比较均衡
-
范围分配缺点
- 如果Topic的个数比较多,而且不能均分,导致负载不均衡问题
-
应用:Topic个数少或者每个Topic都均衡的场景
-
-
小结
- 规则:每个消费者消费一定范围的分区,尽量做均分,如果不能均分,优先将分区分配给编号小的消费者
- 应用:适合于Topic个数少或者每个Topic都能均分场景
知识点05:消费分配策略:RoundRobinAssignor
-
目标:掌握轮询分配策略的规则及应用场景
-
路径
- step1:轮询分配的规则是什么?
- step2:轮询规则有什么优缺点?
-
实施
-
轮询分配的规则
-
按照Topic的分区编号,轮询分配给每个消费者
-
如果遇到范围分区的场景,能否均衡
-
三个消费者,消费3个Topic,每个有7个分区
消费者 分区 C1 T1【0,3,6】 T2【2,5】 T3【1,4】 C2 T1【1,4】 T2【0,3,6】 T3【2,5】 C3 T1【2,5】 T2【1,4】 T3【0,3,6】
-
-
-
举例
-
假设一:三个消费者,消费2个Topic,每个Topic3个分区
消费者 分区 C1 T1【0】 T2【0】 C2 T1【1】 T2【1】 C3 T1【2】 T2【2】 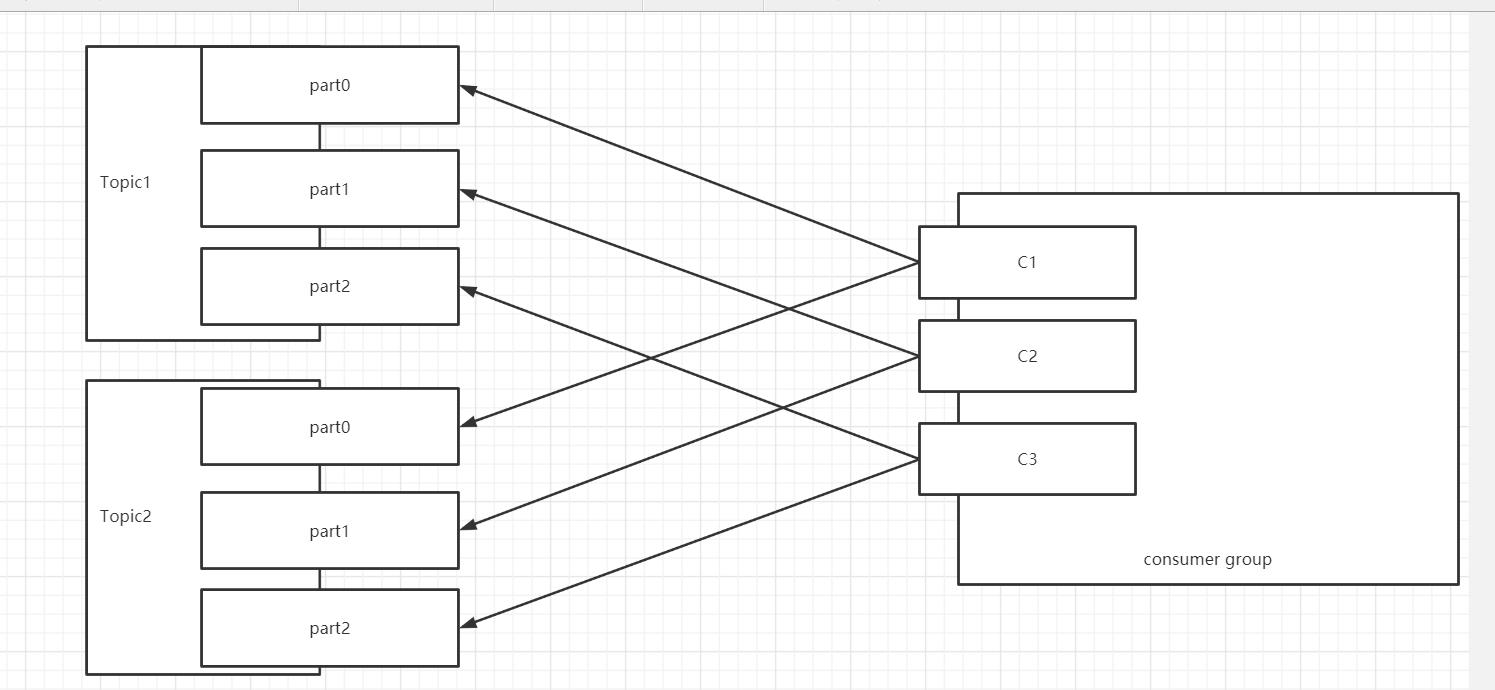
-
假设二:三个消费者,消费3个Topic,第一个Topic1个分区,第二个Topic2个分区,第三个Topic三个分区,消费者1消费Topic1,消费者2消费Topic1,Topic2,消费者3消费Topic1,Topic2,Topic3
T1[0] T2[0,1] T3[0,1,2]消费者 分区 C1 T1【0】 C2 T2【0】 C3 T2【1】 T3【0】 T3【1】 T3【2】 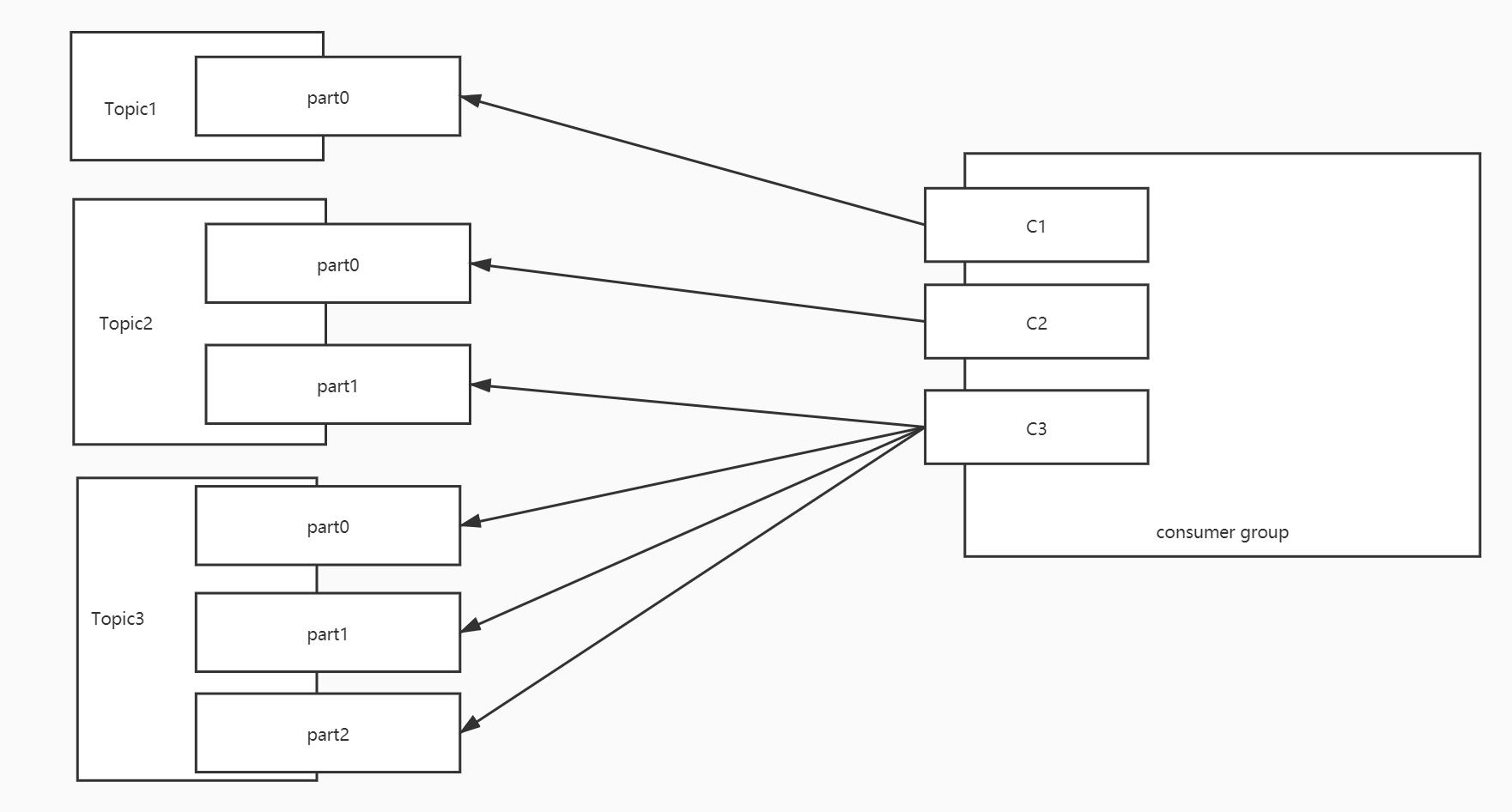
- 问题:负载不均衡
-
-
轮询分配的优点
- 如果有多个消费者,消费的Topic都是一样的,实现将所有Topic的所有分区轮询分配给所有消费者,尽量的实现负载的均衡
- 大多数的场景都是这种场景
-
轮询分配的缺点
- 遇到消费者订阅的Topic是不一致的,不同的消费者订阅了不同Topic,只能基于订阅的消费者进行轮询分配,导致整体消费者负载不均衡的
-
应用场景:所有消费者都订阅共同的Topic,能实现让所有Topic的分区轮询分配所有的消费者
-
-
小结
- 规则:根据订阅关系,将订阅的Topic的分区排序轮询分配给订阅的消费者
- 应用:订阅关系都是一致的
知识点06:消费分配策略:StickyAssignor
-
目标:掌握黏性分配策略的规则及应用场景
-
路径
- step1:黏性分配的规则是什么?
- step2:黏性分配有什么特点?
-
实施
-
轮询分配的规则
- 类似于轮询分配,尽量的将分区均衡的分配给消费者
-
黏性分配的特点
- 相对的保证的分配的均衡
-
如果某个消费者故障,尽量的避免网络传输
-
尽量保证原来的消费的分区不变,将多出来分区均衡给剩余的消费者
-
举例
-
假设一:三个消费者,消费2个Topic,每个Topic3个分区
消费者 分区 C1 T1【0】 T2【0】 C2 T1【1】 T2【1】 C3 T1【2】 T2【2】 - 效果类似于轮询,比较均衡的分配,但底层实现原理有些不一样 -
假设二:三个消费者,消费3个Topic,第一个Topic1个分区,第二个Topic2个分区,第三个Topic三个分区,消费者1消费Topic1,消费者2消费Topic1,Topic2,消费者3消费Topic1,Topic2,Topic3
消费者 分区 C1 T1【0】 C2 T2【0】 T2【1】 C3 T3【0】 T3【1】 T3【2】 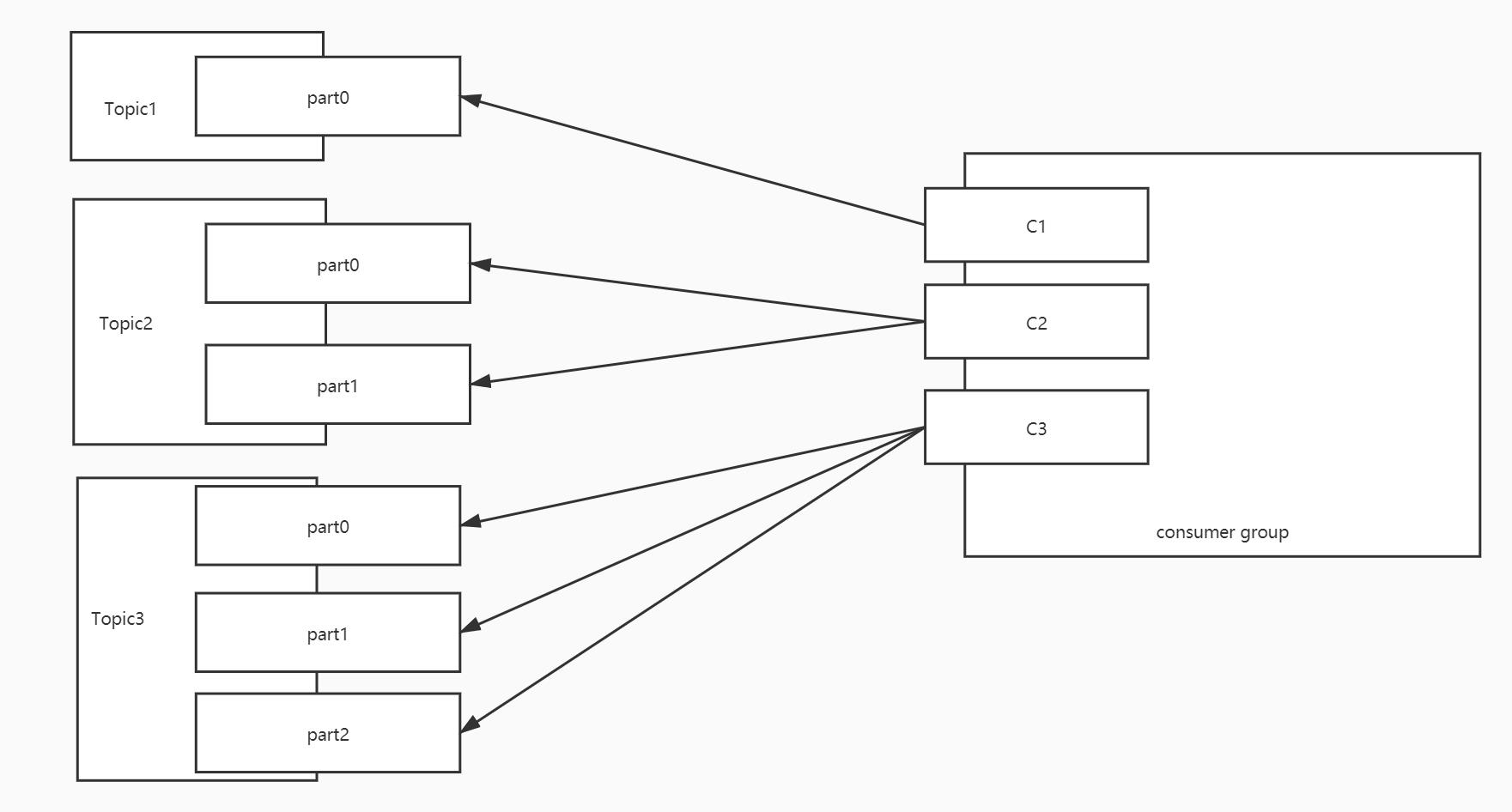
-
-
负载均衡的场景
-
假设三:如果假设一中的C3出现故障
-
假设一
消费者 分区 C1 T1【0】 T2【0】 C2 T1【1】 T2【1】 C3 T1【2】 T2【2】 -
轮询:将所有分区重新分配
消费者 分区 C1 T1【0】 T1【2】 T2【1】 C2 T1【1】 T2【0】 T2【2】 -
黏性:直接故障的分区均分给其他的消费者,其他消费者不用改变原来的分区,降低网络IO消耗
消费者 分区 C1 T1【0】 T2【0】 T1【2】 C2 T1【1】 T2【1】 T2【2】
-
-
假设四:如果假设二中的C1出现故障
-
假设二:轮询
消费者 分区 C1 T1【0】 C2 T2【0】 C3 T2【1】 T3【0】 T3【1】 T3【2】 -
轮询负载均衡
消费者 分区 C2 T1【0】 T2【1】 C3 T2【0】T3【0】 T3【1】 T3【2】 -
假设二:黏性
消费者 分区 C1 T1【0】 C2 T2【0】 T2【1】 C3 T3【0】 T3【1】 T3【2】 -
黏性负载均衡
消费者 分区 C2 T2【0】 T2【1】 T1【0】 C3 T3【0】 T3【1】 T3【2】
-
-
-
小结
- 规则:尽量保证所有分配均衡,尽量保证每个消费者如果出现故障,剩余消费者依旧保留自己原来消费的分区
- 特点
- 分配更加均衡
- 如果消费者出现故障,提高性能,避免重新分配,将多余的分区均衡的分配给剩余的消费者
知识点07:Kafka存储机制:存储结构
-
目标:掌握Kafka的存储结构设计及概念
-
路径
-
实施
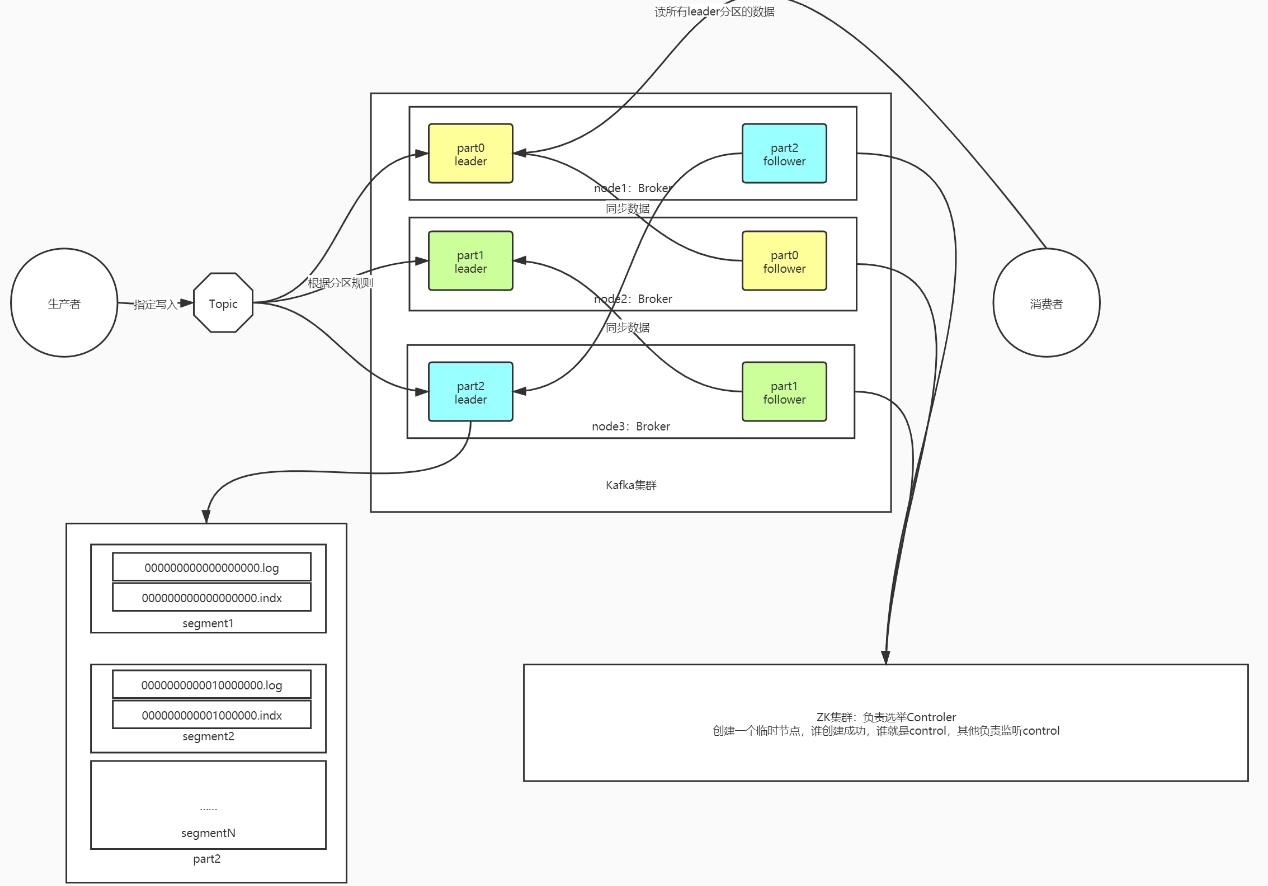
- Broker:物理存储节点,用于存储Kafka中每个分区的数据
- Producer:生产者生产数据
- Topic:逻辑存储对象,用于区分不同数据的的存储
- Partition:分布式存储单元,一个Topic可以划分多个分区,每个分区可以分布式存储在不同的Broker节点上
- Segment:分区段,每个分区的数据存储在1个或者多个Segment中,每个Segment由一对文件组成
- Segment命名规则:最小Offset
-
小结
-
Broker【物理进程节点】 | Topic【逻辑对象概念】
-
Partition:逻辑上分布式划分的概念、物理上存储数据的单元
- 分区名称 = Topic名称 + 分区编号
[root@node1 ~]# ll /export/server/kafka_2.12-2.4.1/logs/ 总用量 1212 drwxr-xr-x 2 root root 4096 3月 31 08:59 bigdata-0 drwxr-xr-x 2 root root 215 3月 31 11:23 bigdata01-1 drwxr-xr-x 2 root root 215 3月 31 11:23 bigdata01-2-
Segment
-rw-r--r-- 1 root root 530080 3月 30 10:48 00000000000000000000.index -rw-r--r-- 1 root root 1073733423 3月 30 10:48 00000000000000000000.log -rw-r--r-- 1 root root 530072 3月 30 10:49 00000000000001060150.index -rw-r--r-- 1 root root 1073734280 3月 30 10:49 00000000000001060150.log -rw-r--r-- 1 root root 189832 3月 31 11:23 00000000000002120301.index -rw-r--r-- 1 root root 384531548 3月 30 10:49 00000000000002120301.log
-
-
知识点08:Kafka存储机制:写入过程
-
目标:掌握Kafka数据的写入过程
-
路径
- Kafka的数据是如何写入的?
- 为什么Kafka写入速度很快?
-
实施
- step1:生产者生产每一条数据,将数据放入一个batch批次中,如果batch满了或者达到一定的时间,提交写入请求
- step2:Kafka根据分区规则将数据写入分区,获取对应的元数据,将请求提交给leader副本所在的Broker
- 元数据存储:Zookeeper中
- step3:先写入这台Broker的PageCache中
- Kafka也用了内存机制来实现数据的快速的读写:不同于Hbase的内存设计
- Hbase:JVM堆内存
- 所有Java程序都是使用JVM堆内存来实现数据管理
- 缺点
- GC:从内存中清理掉不再需要的数据,导致GC停顿,影响性能
- 如果HRegionServer故障,JVM堆内存中的数据就丢失了,只能通过HLog恢复,性能比较差
- Kafka:操作系统Page Cache
- 选用了操作系统自带的缓存区域:PageCache
- 由操作系统来管理所有内存,即使Kafka Broker故障,数据依旧存在PageCache中
- Hbase:JVM堆内存
- Kafka也用了内存机制来实现数据的快速的读写:不同于Hbase的内存设计
- step4:操作系统的后台的自动将页缓存中的数据SYNC同步到磁盘文件中:最新的Segment的.log中
- 顺序写磁盘:不断将每一条数据追加到.log文件中
- step5:其他的Follower到Leader中同步数据
-
小结
- Kafka的数据是如何写入的?
- step1:生产者构建批次,提交给Kafka集群
- step2:Kafka根据分区规则,检索元数据,将请求转发给Leader副本对应Broker
- step3:先写Broker的PageCache
- step4:后台实现将PageCache中顺序写同步到磁盘中:.log文件
- step5:Follower同步Leader副本的数据
- 为什么Kafka写入速度很快?
- 应用了PageCache的页缓存机制
- 顺序写磁盘的机制
- Kafka的数据是如何写入的?
知识点09:Kafka存储机制:Segment
-
目标:掌握Segment的设计及命名规则
-
路径
- 为什么要设计Segment?
- Segment是如何实现的?
-
实施
-
设计思想
- 加快查询效率
- 通过将分区的数据根据Offset划分多个比较小的Segment文件
- 在检索数据时,可以根据Offset快速定位数据所在的Segment
- 加载单个Segment文件查询数据,可以提高查询效率
- 减少删除数据IO
- 删除数据时,Kafka以Segment为单位删除某个Segment的数据
- 避免一条一条删除,增加IO负载,性能较差
- 加快查询效率
-
Segment的基本实现
- .log:存储真正的数据
- .index:存储对应的.log文件的索引
-
Segment的划分规则:满足任何一个条件都会划分segment
-
按照时间周期生成
#如果达到7天,重新生成一个新的Segment log.roll.hours = 168 -
按照文件大小生成
#如果一个Segment存储达到1G,就构建一个新的Segment log.segment.bytes = 1073741824
-
-
Segment文件的命名规则
- 以当前文件存储的最小offset来命名的
00000000000000000000.log offset : 0 ~ 2344 00000000000000000000.index 00000000000000002345.log offset : 2345 ~ 6788 00000000000000002345.index 00000000000000006789.log offset : 6789 ~ 00000000000000006789.index
-
-
小结
- 为什么要设计Segment?
- 加快查询效率:将数据划分到多个小文件中,通过offset匹配可以定位某个文件,从小数据量中找到需要的数据
- 提高删除性能:以Segment为单位进行删除,避免以每一条数据进行删除,影响性能
- Segment是如何实现的?
- 组合:一对文件组件
- .log
- .index
- 划分
- 时间:7天
- 大小:1G
- 命名:以这个segment中存储的最小offset来命名
- 组合:一对文件组件
- 为什么要设计Segment?
知识点10:Kafka存储机制:读取过程
- 目标:掌握Kafka数据的读取过程
- 路径
- Kafka数据是如何被读取的?
- 为什么Kafka读取数据也很快?
- 实施
- step1:消费者根据Topic、Partition、Offset提交给Kafka请求读取数据
- step2:Kafka根据元数据信息,找到对应的这个分区对应的Leader副本
- step3:请求Leader副本所在的Broker,先读PageCache,通过零拷贝机制【Zero Copy】读取PageCache
- step4:如果PageCache中没有,读取Segment文件段,先根据offset找到要读取的那个Segment
- step5:将.log文件对应的.index文件加载到内存中,根据.index中索引的信息找到Offset在.log文件中的最近位置
- 最近位置:index中记录的稀疏索引【不是每一条数据都有索引】
- step6:读取.log,根据索引读取对应Offset的数据
- 小结
- Kafka数据是如何被读取的?
- step1:消费者请求读取数据:Topic+Partition+Offset
- step2:Kafka根据元数据,找到对应分区的leader副本进行检索
- step3:先检索PageCache
- 如果有,就通过零拷贝机制从PageCache中读取数据
- 如果没有,就读取Segment文件段
- step4:先根据Offset找到对应的Segment的一对文件
- step5:先读index,找到offset对应的数据在.log文件中的最近位置
- step6:根据位置,读取.log文件
- 为什么Kafka读取数据也很快?
- 优先基于PageCache内存的读取,使用零拷贝机制
- 按照Offset有序读取每一条
- 构建Segment文件段
- 构建index索引
- Kafka数据是如何被读取的?
知识点11:Kafka存储机制:index索引设计
-
目标:掌握Kafka的Segment中index的索引设计
-
路径
- .index文件中的索引的内容是什么?
- 查询数据时如何根据索引找到对应offset的数据?
-
实施
-
索引类型
-
全量索引:每一条数据,都对应一条索引
-
稀疏索引:部分数据有索引,有一部分数据是没有索引的
-
优点:减少了索引存储的数据量加快索引的索引的检索效率
-
什么时候生成一条索引?
#.log文件每增加4096字节,在.index中增加一条索引
log.index.interval.bytes=4096
- Kafka中选择使用了稀疏索引 -
-
-
索引内容
- 两列
- 第一列:这条数据在这个文件中的位置
- 第二列:这条数据在文件中的物理偏移量
是这个文件中的第几条,数据在这个文件中的物理位置 1,0 --表示这个文件中的第一条,在文件中的位置是第0个字节开始 3,497 --表示这个文件中的第三条,在文件中的位置是第497个字节开始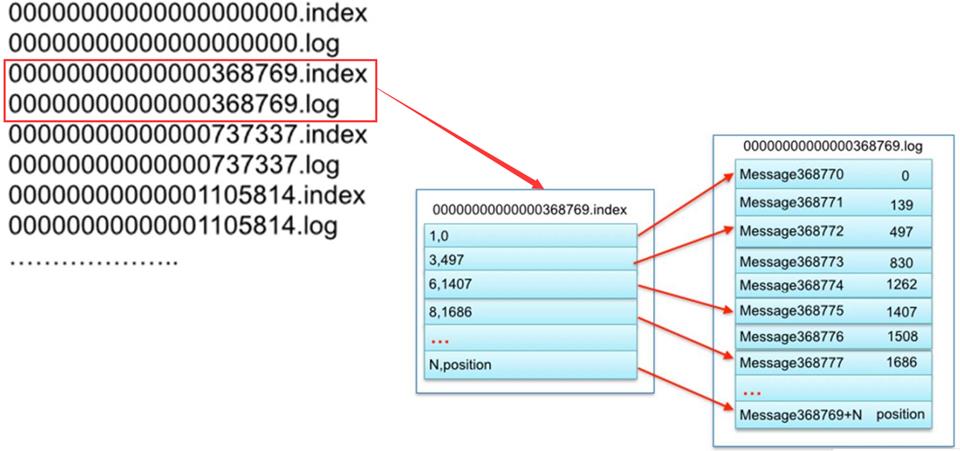
- 这个文件中的第1条数据是这个分区中的第368770条数据,offset = 368769
- 两列
-
检索数据流程
- step1:先根据offset计算这条offset是这个文件中的第几条
- step2:读取.index索引,根据二分检索,从索引中找到离这条数据最近偏小的位置
- step3:读取.log文件从最近位置读取到要查找的数据
-
举例
-
需求:查找offset = 368772
-
step1:计算是文件中的第几条
368772 - 368769 = 3 + 1 = 4,是这个文件中的第四条数据 -
step2:读取.index索引,找到最近位置
3,497 -
step3:读取.log,从497位置向后读取一条数据,得到offset = 368772的数据
-
-
问题:为什么不直接将offset作为索引的第一列?
- 因为Offset越来越大,导致索引存储越来越大,空间占用越多,检索索引比较就越麻烦
-
-
小结
- .index文件中的索引的内容是什么?
- 第一列:这条数据是这个文件第几条数据
- 第二列:存储这条数据在文件中的物理偏移量
- 查询数据时如何根据索引找到对应offset的数据?
- step1:先根据给定的offset计算这个offset是这个文件的第几条
- step2:读取index索引,找到最近物理位置
- step3:读取.log文件,找到对应的数据
- .index文件中的索引的内容是什么?
知识点12:Kafka数据清理规则
-
目标:了解Kafka中数据清理的规则
-
路径
- Kafka用于实现实时消息队列的数据缓存,不需要永久性的存储数据,如何将过期数据进行清理?
-
实施
-
属性配置
#开启清理 log.cleaner.enable = true #清理规则 log.cleanup.policy = delete | compact -
清理规则:delete
-
基于存活时间规则:最常用的方式
log.retention.ms log.retention.minutes log.retention.hours=168/7天 -
基于文件大小规则
#删除文件阈值,如果整个数据文件大小,超过阈值的一个segment大小,将会删除最老的segment,-1表示不使用这种规则 log.retention.bytes = -1 -
基于offset消费规则
-
功能:将明确已经消费的offset的数据删除
-
如何判断已经消费到什么位置
-
step1:编写一个文件offset.json
{ "partitions":[ {"topic": "bigdata", "partition": 0,"offset": 2000}, {"topic": "bigdata", "partition": 1,"offset": 2000} ], "version":1 } -
step2:指定标记这个位置
kafka-delete-records.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --offset-json-file offset.json
-
-
-
-
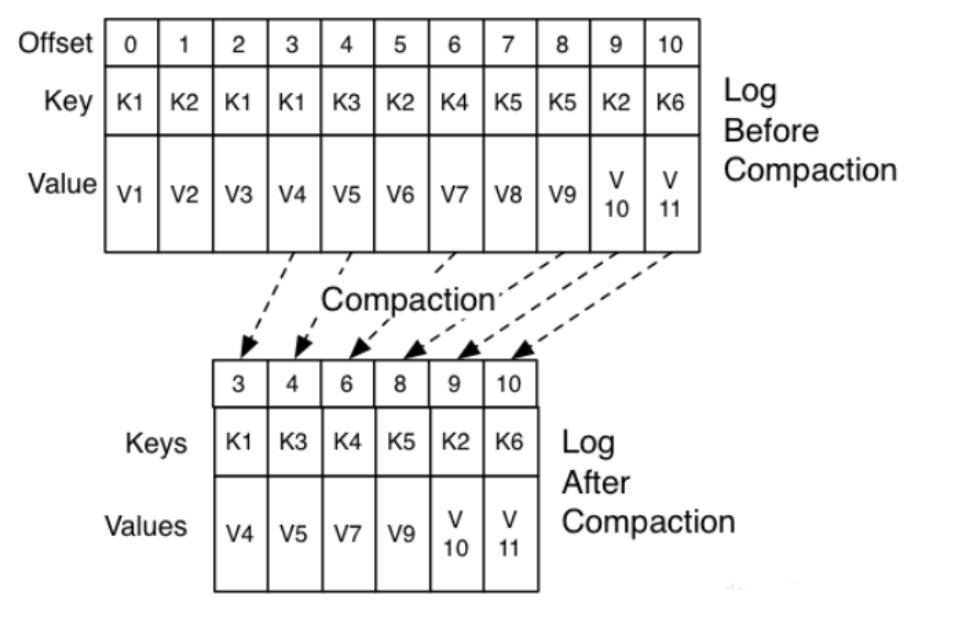
清理规则:compact
-
功能:将重复的更新数据的老版本删除,保留新版本,要求每条数据必须要有Key,根据Key来判断是否重复
-
-
小结
-
Kafka用于实现实时消息队列的数据缓存,不需要永久性的存储数据,如何将过期数据进行清理?
{ "partitions":[ {"topic": "bigdata", "partition": 0,"offset": 2000}, {"topic": "bigdata", "partition": 1,"offset": 2000} ], "version":1 } ``` - step2:指定标记这个位置 ```shell kafka-delete-records.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --offset-json-file offset.json ``` -
清理规则:compact
-
功能:将重复的更新数据的老版本删除,保留新版本,要求每条数据必须要有Key,根据Key来判断是否重复
-
-
小结
- Kafka用于实现实时消息队列的数据缓存,不需要永久性的存储数据,如何将过期数据进行清理?
- delete方案:根据时间定期的清理过期的Segment文件
以上是关于kafka分区分布的主要内容,如果未能解决你的问题,请参考以下文章