bs4_2
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了bs4_2相关的知识,希望对你有一定的参考价值。
Parsing html with the BeautifulSoup Module
Beautiful Soup是用于提取HTML网页信息的模板,BeautifulSoup模板名字是bs4。
bs4.BeautifulSoup()函数需要调用时,携带包含HTML的一个字符串。这个字符串将被复制。
bs4.BeautifulSoup()返回一个BeautifulSoup对象。
Beautiful Soup is a module for extracting information from an HTML page (and is much better for this purpose than regular expressions). The BeautifulSoupmodule’s name is bs4 (for Beautiful Soup, version 4). To install it, you will need to run pip install beautifulsoup4 from the command line. (Check out Appendix A for instructions on installing third-party modules.) While beautifulsoup4 is the name used for installation, to import Beautiful Soup you run import bs4.
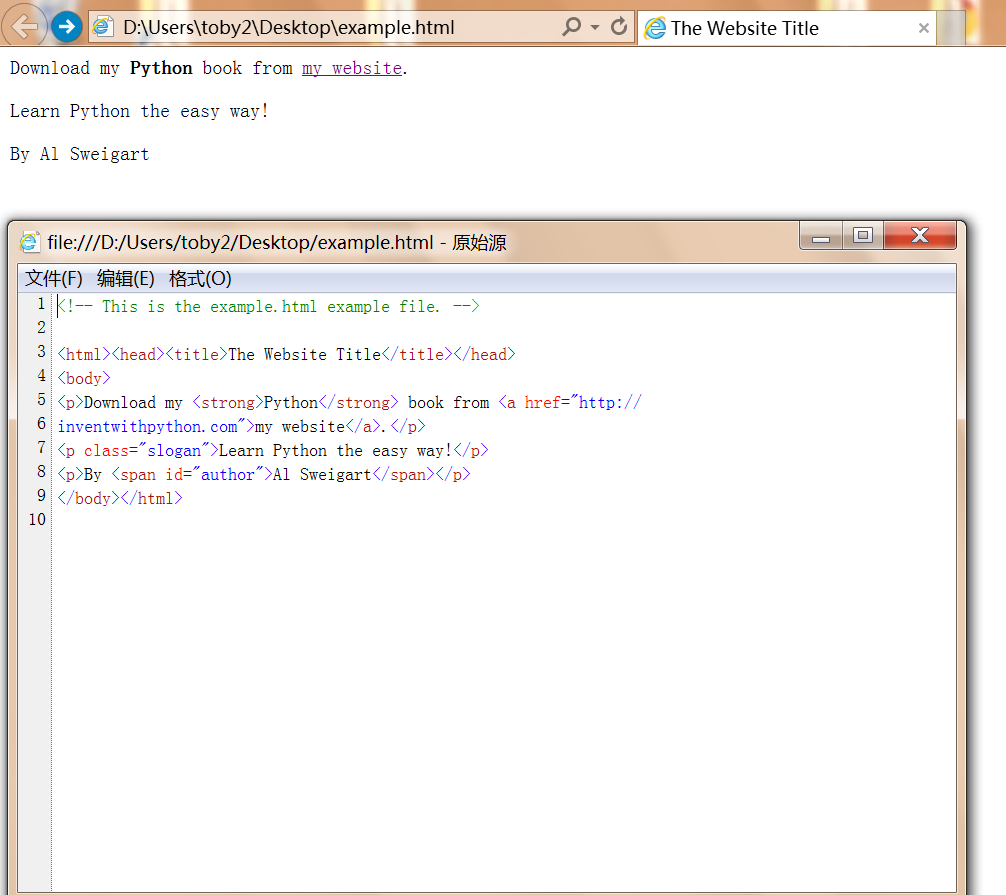
For this chapter, the Beautiful Soup examples will parse (that is, analyze and identify the parts of) an HTML file on the hard drive. Open a new file editor window in IDLE, enter the following, and save it as example.html. Alternatively, download it from http://nostarch.com/automatestuff/.
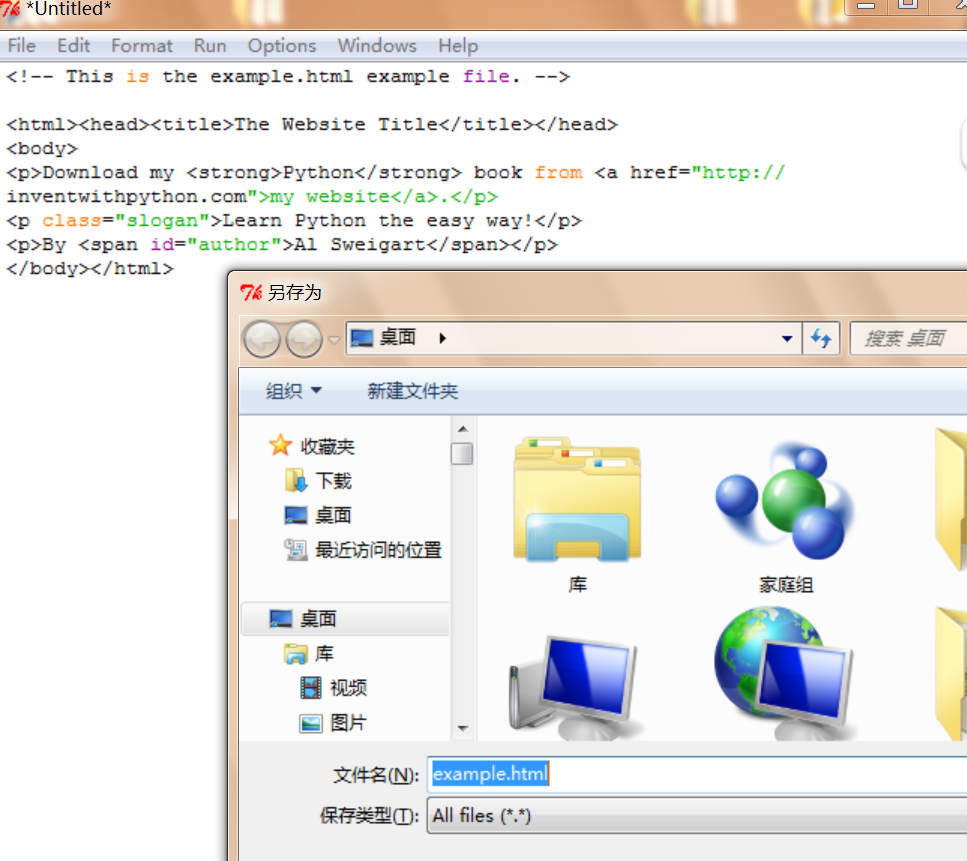
<!-- This is the example.html example file. -->
<html><head><title>The Website Title</title></head>
<body><p>Download my <strong>Python</strong> book from <a href="http://inventwithpython.com">my website</a>.</p><p class="slogan">Learn Python the easy way!</p><p>By <span id="author">Al Sweigart</span></p>
</body></html>
As you can see, even a simple HTML file involves many different tags and attributes, and matters quickly get confusing with complex websites. Thankfully, Beautiful Soup makes working with HTML much easier.
Creating a BeautifulSoup Object from HTML
bs4.BeautifulSoup()函数需要调用时,携带包含HTML的一个字符串。这个字符串将被复制。
bs4.BeautifulSoup()返回一个BeautifulSoup对象。
The bs4.BeautifulSoup() function needs to be called with a string containing the HTML it will parse. The bs4.BeautifulSoup() function returns is a BeautifulSoupobject. Enter the following into the interactive shell while your computer is connected to the Internet:
>>> import requests, bs4
>>> res = requests.get(‘http://nostarch.com‘)
>>> res.raise_for_status()
>>> noStarchSoup = bs4.BeautifulSoup(res.text) #返回文字属性给bs4.BeautifulSoup函数
>>> type(noStarchSoup)
<class ‘bs4.BeautifulSoup‘>
This code uses requests.get() to download the main page from the No Starch Press website and then passes the text attribute of the response to bs4.BeautifulSoup(). The BeautifulSoup object that it returns is stored in a variable named noStarchSoup.
You can also load an HTML file from your hard drive by passing a File object tobs4.BeautifulSoup(). Enter the following into the interactive shell (make sure theexample.html file is in the working directory):
>>> exampleFile = open(‘example.html‘)
>>> exampleSoup = bs4.BeautifulSoup(exampleFile)
>>> type(exampleSoup)
<class ‘bs4.BeautifulSoup‘>
Once you have a BeautifulSoup object, you can use its methods to locate specific parts of an HTML document.
如何创建一个example.html测试文件
打开一个idle文件,复制好下图HTML代码,用example.html文件名报存
以上是关于bs4_2的主要内容,如果未能解决你的问题,请参考以下文章